AdaFocus:强化学习驱动的高效视频识别
版权申诉
“Adaptive Focus for Efficient Video Recognition.pdf”
在当前的数字化时代,视频数据的处理和理解变得越来越重要,特别是在人工智能领域。视频识别是这一领域的关键组成部分,它涉及到对视频内容的理解和分类。然而,传统的视频识别方法往往需要处理大量的数据,这在计算资源和时间上都带来了极大的负担。为了应对这一挑战,"Adaptive Focus for Efficient Video Recognition"这篇论文提出了一个新的方法——AdaFocus,旨在通过优化空间注意力机制来提高视频识别的效率。
该研究的核心观察是,视频中的每一帧中最具信息量的区域通常是一个小的图像区域(patch),并且这个区域在不同帧之间有平滑的移动。利用这一特性,作者将patch定位问题转化为一个连续的决策任务,采用强化学习来解决。这种方法的优势在于,它能够动态地关注视频中最相关和重要的部分,而忽略不那么重要的背景信息,从而减少了计算需求。
AdaFocus的具体实现包括两个主要步骤。首先,一个轻量级的卷积神经网络(ConvNet)快速处理整个视频序列,提取全局特征。这些特征随后被输入到一个递归策略网络中,该网络负责学习如何在不同帧中定位最相关的任务区域。然后,选择出的具有高信息价值的patch由一个具有高容量的网络进行进一步处理,用于最终的预测。在离线推断阶段,一旦确定了最有信息量的patch序列,就可以用高精度模型进行高效分析。
在实验部分,AdaFocus在ActivityNet、FCVID、Mini-Kinetics以及Something-Something V1&V2这五个广泛使用的视频识别基准数据集上进行了测试。结果表明,与现有的竞争性基线方法相比,AdaFocus在保持甚至提高识别准确性的同时,显著提高了计算效率。这验证了其在实际应用中的潜力,尤其是在资源受限的环境中,如嵌入式设备或实时视频流处理。
"Adaptive Focus for Efficient Video Recognition"的研究工作为视频识别提供了一种新的视角,即通过智能地关注视频中的关键区域来减少计算开销。这项工作不仅推动了视频理解的效率,也为未来强化学习在视觉任务中的应用提供了新的思路。通过这种方法,我们可以期待在未来的视频处理系统中看到更快、更节能的视频识别解决方案。
⇡
<latexit sha1_base64="dFE2eW+rFkTgpSmL6js6MnSZTo0=">AAAIA3icnVVLT9RQFD6AWsQHoEs3jRMSFzK2xESWJG6McYHKAAkQ03buQDN92d6KhLB06VZ/hDvj1h/iP9B/4XfO7TDvjtiG4dxzv/Ode163fhaFhXacX3PzC9eu37AWby7dun3n7vLK6r3dIi3zQLWCNErzfd8rVBQmqqVDHan9LFde7Edqz+8+5/29DyovwjTZ0WeZOoq94yTshIGnoXp7mIXvVhpO05HHHhfcSmhQ9WynqwslHVKbUgqopJgUJaQhR+RRgfeAXHIog+6IzqHLIYWyr+iClmBbAqWA8KDt4vcYq4NKm2DNnIVYB/AS4S+HpU1rsEmByyGzN1v2S2Fm7TTuc+Hks53hv19xxdBqOoF2ll0P+a92HIumDm1KDCFiykTD0QUVSylZ4ZPbA1FpMGTQsdzGfg45EMtenm2xKSR2zq0n+78FyVpeBxW2pD9ySvP+/1mZNZI6nEI2+HVY2AP46fw76Afm7sA+GWI275pwFpKJTfD6YOU42c6+tKqr0gnqarLGWegMcPc99DGRnLpby1gKbpRnmLEATwxLU8MWvaFXUkHjh1m11DgB53RPPuJLsebK+0BMOnuG06SIS0kPh5IRrsg6vQerJxGxX7tiMR0yq6v7mZ3k05cJYys+IXdaG9pe79uXs8TzWecrkdnnqpheneSLpziuLPUYt+kBngiXntAGPYak5MZp1viNxS/nrVeRizG/o5gUtrlMIHdLXc3impts/NaoQ0aQOLpQsOZEV7OoQ8dyO2q5SXh667D92PkMH2uxBfQ+6hJiXcrU1aFPK2aDn525q8RlvhCzOft3/3Rkhh7viPZYJghYfB3d0W/huLC70XSdpvv6aWPrZfWdXKQH9JAeoWef0Ra9oG3cEAF4P9MX+mp9sr5Z360fBjo/V9ncp6HH+vkX8n+Gug==</latexit>
<latexit sha1_base64="dFE2eW+rFkTgpSmL6js6MnSZTo0=">AAAIA3icnVVLT9RQFD6AWsQHoEs3jRMSFzK2xESWJG6McYHKAAkQ03buQDN92d6KhLB06VZ/hDvj1h/iP9B/4XfO7TDvjtiG4dxzv/Ode163fhaFhXacX3PzC9eu37AWby7dun3n7vLK6r3dIi3zQLWCNErzfd8rVBQmqqVDHan9LFde7Edqz+8+5/29DyovwjTZ0WeZOoq94yTshIGnoXp7mIXvVhpO05HHHhfcSmhQ9WynqwslHVKbUgqopJgUJaQhR+RRgfeAXHIog+6IzqHLIYWyr+iClmBbAqWA8KDt4vcYq4NKm2DNnIVYB/AS4S+HpU1rsEmByyGzN1v2S2Fm7TTuc+Hks53hv19xxdBqOoF2ll0P+a92HIumDm1KDCFiykTD0QUVSylZ4ZPbA1FpMGTQsdzGfg45EMtenm2xKSR2zq0n+78FyVpeBxW2pD9ySvP+/1mZNZI6nEI2+HVY2AP46fw76Afm7sA+GWI275pwFpKJTfD6YOU42c6+tKqr0gnqarLGWegMcPc99DGRnLpby1gKbpRnmLEATwxLU8MWvaFXUkHjh1m11DgB53RPPuJLsebK+0BMOnuG06SIS0kPh5IRrsg6vQerJxGxX7tiMR0yq6v7mZ3k05cJYys+IXdaG9pe79uXs8TzWecrkdnnqpheneSLpziuLPUYt+kBngiXntAGPYak5MZp1viNxS/nrVeRizG/o5gUtrlMIHdLXc3impts/NaoQ0aQOLpQsOZEV7OoQ8dyO2q5SXh667D92PkMH2uxBfQ+6hJiXcrU1aFPK2aDn525q8RlvhCzOft3/3Rkhh7viPZYJghYfB3d0W/huLC70XSdpvv6aWPrZfWdXKQH9JAeoWef0Ra9oG3cEAF4P9MX+mp9sr5Z360fBjo/V9ncp6HH+vkX8n+Gug==</latexit>
<latexit sha1_base64="dFE2eW+rFkTgpSmL6js6MnSZTo0=">AAAIA3icnVVLT9RQFD6AWsQHoEs3jRMSFzK2xESWJG6McYHKAAkQ03buQDN92d6KhLB06VZ/hDvj1h/iP9B/4XfO7TDvjtiG4dxzv/Ode163fhaFhXacX3PzC9eu37AWby7dun3n7vLK6r3dIi3zQLWCNErzfd8rVBQmqqVDHan9LFde7Edqz+8+5/29DyovwjTZ0WeZOoq94yTshIGnoXp7mIXvVhpO05HHHhfcSmhQ9WynqwslHVKbUgqopJgUJaQhR+RRgfeAXHIog+6IzqHLIYWyr+iClmBbAqWA8KDt4vcYq4NKm2DNnIVYB/AS4S+HpU1rsEmByyGzN1v2S2Fm7TTuc+Hks53hv19xxdBqOoF2ll0P+a92HIumDm1KDCFiykTD0QUVSylZ4ZPbA1FpMGTQsdzGfg45EMtenm2xKSR2zq0n+78FyVpeBxW2pD9ySvP+/1mZNZI6nEI2+HVY2AP46fw76Afm7sA+GWI275pwFpKJTfD6YOU42c6+tKqr0gnqarLGWegMcPc99DGRnLpby1gKbpRnmLEATwxLU8MWvaFXUkHjh1m11DgB53RPPuJLsebK+0BMOnuG06SIS0kPh5IRrsg6vQerJxGxX7tiMR0yq6v7mZ3k05cJYys+IXdaG9pe79uXs8TzWecrkdnnqpheneSLpziuLPUYt+kBngiXntAGPYak5MZp1viNxS/nrVeRizG/o5gUtrlMIHdLXc3impts/NaoQ0aQOLpQsOZEV7OoQ8dyO2q5SXh667D92PkMH2uxBfQ+6hJiXcrU1aFPK2aDn525q8RlvhCzOft3/3Rkhh7viPZYJghYfB3d0W/huLC70XSdpvv6aWPrZfWdXKQH9JAeoWef0Ra9oG3cEAF4P9MX+mp9sr5Z360fBjo/V9ncp6HH+vkX8n+Gug==</latexit>
<latexit sha1_base64="dFE2eW+rFkTgpSmL6js6MnSZTo0=">AAAIA3icnVVLT9RQFD6AWsQHoEs3jRMSFzK2xESWJG6McYHKAAkQ03buQDN92d6KhLB06VZ/hDvj1h/iP9B/4XfO7TDvjtiG4dxzv/Ode163fhaFhXacX3PzC9eu37AWby7dun3n7vLK6r3dIi3zQLWCNErzfd8rVBQmqqVDHan9LFde7Edqz+8+5/29DyovwjTZ0WeZOoq94yTshIGnoXp7mIXvVhpO05HHHhfcSmhQ9WynqwslHVKbUgqopJgUJaQhR+RRgfeAXHIog+6IzqHLIYWyr+iClmBbAqWA8KDt4vcYq4NKm2DNnIVYB/AS4S+HpU1rsEmByyGzN1v2S2Fm7TTuc+Hks53hv19xxdBqOoF2ll0P+a92HIumDm1KDCFiykTD0QUVSylZ4ZPbA1FpMGTQsdzGfg45EMtenm2xKSR2zq0n+78FyVpeBxW2pD9ySvP+/1mZNZI6nEI2+HVY2AP46fw76Afm7sA+GWI275pwFpKJTfD6YOU42c6+tKqr0gnqarLGWegMcPc99DGRnLpby1gKbpRnmLEATwxLU8MWvaFXUkHjh1m11DgB53RPPuJLsebK+0BMOnuG06SIS0kPh5IRrsg6vQerJxGxX7tiMR0yq6v7mZ3k05cJYys+IXdaG9pe79uXs8TzWecrkdnnqpheneSLpziuLPUYt+kBngiXntAGPYak5MZp1viNxS/nrVeRizG/o5gUtrlMIHdLXc3impts/NaoQ0aQOLpQsOZEV7OoQ8dyO2q5SXh667D92PkMH2uxBfQ+6hJiXcrU1aFPK2aDn525q8RlvhCzOft3/3Rkhh7viPZYJghYfB3d0W/huLC70XSdpvv6aWPrZfWdXKQH9JAeoWef0Ra9oG3cEAF4P9MX+mp9sr5Z360fBjo/V9ncp6HH+vkX8n+Gug==</latexit>
Crop
C
f
c
<latexit sha1_base64="Xlq4arAc+IQXsRnM5wU6RY06/G8=">AAAIDnicnVXLbtNQEJ22QEp5tIUlG4uoEgsa4gqJLishJBYsCmraSm2pbOcmteIX9jVtFeUfWLKFj2CH2PIL/AH8BWfmOs3bodhqOnfumTN3XtduEviZrtd/LSwu3bh5q7J8e+XO3Xv3V9fWH+xncZ56quHFQZweuk6mAj9SDe3rQB0mqXJCN1AHbucl7x98VGnmx9GevkzUSei0I7/le46G6n3rtHus1YXOvK7X652uVeu1ujzWpGAXQpWKZzdeX8rpmJoUk0c5haQoIg05IIcyvEdkU50S6E6oC10KyZd9RT1agW0OlALCgbaD3zZWR4U2wpo5M7H24CXAXwpLizZgEwOXQmZvluznwszaWdxd4eSzXeK/W3CF0Go6g3aeXR/5r3Yci6YWbUsMPmJKRMPReQVLLlnhk1tDUWkwJNCx3MR+CtkTy36eLbHJJHbOrSP7vwXJWl57BTanP3JK8/7/WZk1kDqcQzb4TVhYQ/jZ/HvoB+ZuwT4aYTbvhnBmkolt8Lpg5TjZzrqyKqvSGepqssZZaA1xDzwMMIGculPKmAtunGeUMQNPCEtTwwa9ozdSQeOHWbXUOALnbE8u4oux5sq7QEw7e4LTxIhLSQ/7khGuyCZ9AKsjEbFfq2AxHTKvqweZnebTlQljKz4hd1oT2n7vW1ezxPNZ5iuS2eeqmF6d5ounOCws9QS36QGeCJue0RY9haTkxqmV+A3FL+etX5HehN9xTAzbVCaQu6WsZmHJTTZ5a5QhA0gcnS9Yc6LrWZShQ7kdtdwkPL1l2EHsfIaLUmwGvYu6+FjnMnVl6POC2eDnZ+46cZkvxHzOwd0/G5mgx1uibcsEAYuvoz3+LZwU9rdqdr1mv31e3XlVfCeX6RE9pifo2Re0Q69pFzcE99pn+kJfK58q3yrfKz8MdHGhsHlII0/l51/hiIv9</latexit>
<latexit sha1_base64="Xlq4arAc+IQXsRnM5wU6RY06/G8=">AAAIDnicnVXLbtNQEJ22QEp5tIUlG4uoEgsa4gqJLishJBYsCmraSm2pbOcmteIX9jVtFeUfWLKFj2CH2PIL/AH8BWfmOs3bodhqOnfumTN3XtduEviZrtd/LSwu3bh5q7J8e+XO3Xv3V9fWH+xncZ56quHFQZweuk6mAj9SDe3rQB0mqXJCN1AHbucl7x98VGnmx9GevkzUSei0I7/le46G6n3rtHus1YXOvK7X652uVeu1ujzWpGAXQpWKZzdeX8rpmJoUk0c5haQoIg05IIcyvEdkU50S6E6oC10KyZd9RT1agW0OlALCgbaD3zZWR4U2wpo5M7H24CXAXwpLizZgEwOXQmZvluznwszaWdxd4eSzXeK/W3CF0Go6g3aeXR/5r3Yci6YWbUsMPmJKRMPReQVLLlnhk1tDUWkwJNCx3MR+CtkTy36eLbHJJHbOrSP7vwXJWl57BTanP3JK8/7/WZk1kDqcQzb4TVhYQ/jZ/HvoB+ZuwT4aYTbvhnBmkolt8Lpg5TjZzrqyKqvSGepqssZZaA1xDzwMMIGculPKmAtunGeUMQNPCEtTwwa9ozdSQeOHWbXUOALnbE8u4oux5sq7QEw7e4LTxIhLSQ/7khGuyCZ9AKsjEbFfq2AxHTKvqweZnebTlQljKz4hd1oT2n7vW1ezxPNZ5iuS2eeqmF6d5ounOCws9QS36QGeCJue0RY9haTkxqmV+A3FL+etX5HehN9xTAzbVCaQu6WsZmHJTTZ5a5QhA0gcnS9Yc6LrWZShQ7kdtdwkPL1l2EHsfIaLUmwGvYu6+FjnMnVl6POC2eDnZ+46cZkvxHzOwd0/G5mgx1uibcsEAYuvoz3+LZwU9rdqdr1mv31e3XlVfCeX6RE9pifo2Re0Q69pFzcE99pn+kJfK58q3yrfKz8MdHGhsHlII0/l51/hiIv9</latexit>
<latexit sha1_base64="Xlq4arAc+IQXsRnM5wU6RY06/G8=">AAAIDnicnVXLbtNQEJ22QEp5tIUlG4uoEgsa4gqJLishJBYsCmraSm2pbOcmteIX9jVtFeUfWLKFj2CH2PIL/AH8BWfmOs3bodhqOnfumTN3XtduEviZrtd/LSwu3bh5q7J8e+XO3Xv3V9fWH+xncZ56quHFQZweuk6mAj9SDe3rQB0mqXJCN1AHbucl7x98VGnmx9GevkzUSei0I7/le46G6n3rtHus1YXOvK7X652uVeu1ujzWpGAXQpWKZzdeX8rpmJoUk0c5haQoIg05IIcyvEdkU50S6E6oC10KyZd9RT1agW0OlALCgbaD3zZWR4U2wpo5M7H24CXAXwpLizZgEwOXQmZvluznwszaWdxd4eSzXeK/W3CF0Go6g3aeXR/5r3Yci6YWbUsMPmJKRMPReQVLLlnhk1tDUWkwJNCx3MR+CtkTy36eLbHJJHbOrSP7vwXJWl57BTanP3JK8/7/WZk1kDqcQzb4TVhYQ/jZ/HvoB+ZuwT4aYTbvhnBmkolt8Lpg5TjZzrqyKqvSGepqssZZaA1xDzwMMIGculPKmAtunGeUMQNPCEtTwwa9ozdSQeOHWbXUOALnbE8u4oux5sq7QEw7e4LTxIhLSQ/7khGuyCZ9AKsjEbFfq2AxHTKvqweZnebTlQljKz4hd1oT2n7vW1ezxPNZ5iuS2eeqmF6d5ounOCws9QS36QGeCJue0RY9haTkxqmV+A3FL+etX5HehN9xTAzbVCaQu6WsZmHJTTZ5a5QhA0gcnS9Yc6LrWZShQ7kdtdwkPL1l2EHsfIaLUmwGvYu6+FjnMnVl6POC2eDnZ+46cZkvxHzOwd0/G5mgx1uibcsEAYuvoz3+LZwU9rdqdr1mv31e3XlVfCeX6RE9pifo2Re0Q69pFzcE99pn+kJfK58q3yrfKz8MdHGhsHlII0/l51/hiIv9</latexit>
<latexit sha1_base64="Xlq4arAc+IQXsRnM5wU6RY06/G8=">AAAIDnicnVXLbtNQEJ22QEp5tIUlG4uoEgsa4gqJLishJBYsCmraSm2pbOcmteIX9jVtFeUfWLKFj2CH2PIL/AH8BWfmOs3bodhqOnfumTN3XtduEviZrtd/LSwu3bh5q7J8e+XO3Xv3V9fWH+xncZ56quHFQZweuk6mAj9SDe3rQB0mqXJCN1AHbucl7x98VGnmx9GevkzUSei0I7/le46G6n3rtHus1YXOvK7X652uVeu1ujzWpGAXQpWKZzdeX8rpmJoUk0c5haQoIg05IIcyvEdkU50S6E6oC10KyZd9RT1agW0OlALCgbaD3zZWR4U2wpo5M7H24CXAXwpLizZgEwOXQmZvluznwszaWdxd4eSzXeK/W3CF0Go6g3aeXR/5r3Yci6YWbUsMPmJKRMPReQVLLlnhk1tDUWkwJNCx3MR+CtkTy36eLbHJJHbOrSP7vwXJWl57BTanP3JK8/7/WZk1kDqcQzb4TVhYQ/jZ/HvoB+ZuwT4aYTbvhnBmkolt8Lpg5TjZzrqyKqvSGepqssZZaA1xDzwMMIGculPKmAtunGeUMQNPCEtTwwa9ozdSQeOHWbXUOALnbE8u4oux5sq7QEw7e4LTxIhLSQ/7khGuyCZ9AKsjEbFfq2AxHTKvqweZnebTlQljKz4hd1oT2n7vW1ezxPNZ5iuS2eeqmF6d5ounOCws9QS36QGeCJue0RY9haTkxqmV+A3FL+etX5HehN9xTAzbVCaQu6WsZmHJTTZ5a5QhA0gcnS9Yc6LrWZShQ7kdtdwkPL1l2EHsfIaLUmwGvYu6+FjnMnVl6POC2eDnZ+46cZkvxHzOwd0/G5mgx1uibcsEAYuvoz3+LZwU9rdqdr1mv31e3XlVfCeX6RE9pifo2Re0Q69pFzcE99pn+kJfK58q3yrfKz8MdHGhsHlII0/l51/hiIv9</latexit>
Global CNN
f
g
<latexit sha1_base64="eVyoCO5GoHBdiLvdViQska8ik/Q=">AAAIEXicnVXLbtNQEJ22QEp4NIUlG4uoEgsakgqJLiuxYcEioKat1FaR7dykVv3CvqatonwFS7bwEewQW76AP4C/4Mxcp3k7FFtNx3PPnLnzuteJfS/V9fqvldW1W7fvlNbvlu/df/Bwo7L56CCNssRVLTfyo+TIsVPle6FqaU/76ihOlB04vjp0zl/z+uFHlaReFO7rq1idBnYv9Lqea2uo2pWNbrt/otWlTt1+bzAotyvVeq0ujzUrNHKhSvnTjDbXMjqhDkXkUkYBKQpJQ/bJphTvMTWoTjF0p9SHLoHkybqiAZVhmwGlgLChPcdvD1/HuTbEN3OmYu3Ci4+/BJYWbcEmAi6BzN4sWc+EmbWLuPvCyXu7wn8n5wqg1XQG7TK7IfJf7TgWTV3alRg8xBSLhqNzc5ZMssI7t8ai0mCIoWO5g/UEsiuWwzxbYpNK7JxbW9Z/C5K1/O3m2Iz+yC7N+/97ZVZf6nAB2eC3YWGN4Rfz76MfmLsL+3CC2bxbwplKJnbB64CV42Q769qqqEpnqKvJGmehO8Y98jDC+LLr80LGTHDTPJOMKXgCWJoatug9vZUKGj/MqqXGITgXe3IQX4RvrrwDxLy9x9hNhLiU9LAnGeGKbNMHsNoSEfu1chbTIcu6epTZeT4dmTC24h1yp3WgHfa+dT1LPJ9FvkKZfa6K6dV5vniKg9xSz3CbHuCJaNAL2qHnkJScOLUCv4H45bwNKzKY8TuNiWCbyARytxTVLCg4yWZPjSKkD4mj8wRrdnQziyJ0IKejlpOEp7cIO4qd93BZiE2hd1AXD9+ZTF0R+iJnNvjlmbtJXOaGWM45OvsXI2P0eFe0PZkgYHE7NqbvwlnhYKfWqNca715W95r5PblOT+gpPUPPvqI9ekNNnBB8X36mL/S19Kn0rfS99MNAV1dym8c08ZR+/gW1eYxR</latexit>
<latexit sha1_base64="eVyoCO5GoHBdiLvdViQska8ik/Q=">AAAIEXicnVXLbtNQEJ22QEp4NIUlG4uoEgsakgqJLiuxYcEioKat1FaR7dykVv3CvqatonwFS7bwEewQW76AP4C/4Mxcp3k7FFtNx3PPnLnzuteJfS/V9fqvldW1W7fvlNbvlu/df/Bwo7L56CCNssRVLTfyo+TIsVPle6FqaU/76ihOlB04vjp0zl/z+uFHlaReFO7rq1idBnYv9Lqea2uo2pWNbrt/otWlTt1+bzAotyvVeq0ujzUrNHKhSvnTjDbXMjqhDkXkUkYBKQpJQ/bJphTvMTWoTjF0p9SHLoHkybqiAZVhmwGlgLChPcdvD1/HuTbEN3OmYu3Ci4+/BJYWbcEmAi6BzN4sWc+EmbWLuPvCyXu7wn8n5wqg1XQG7TK7IfJf7TgWTV3alRg8xBSLhqNzc5ZMssI7t8ai0mCIoWO5g/UEsiuWwzxbYpNK7JxbW9Z/C5K1/O3m2Iz+yC7N+/97ZVZf6nAB2eC3YWGN4Rfz76MfmLsL+3CC2bxbwplKJnbB64CV42Q769qqqEpnqKvJGmehO8Y98jDC+LLr80LGTHDTPJOMKXgCWJoatug9vZUKGj/MqqXGITgXe3IQX4RvrrwDxLy9x9hNhLiU9LAnGeGKbNMHsNoSEfu1chbTIcu6epTZeT4dmTC24h1yp3WgHfa+dT1LPJ9FvkKZfa6K6dV5vniKg9xSz3CbHuCJaNAL2qHnkJScOLUCv4H45bwNKzKY8TuNiWCbyARytxTVLCg4yWZPjSKkD4mj8wRrdnQziyJ0IKejlpOEp7cIO4qd93BZiE2hd1AXD9+ZTF0R+iJnNvjlmbtJXOaGWM45OvsXI2P0eFe0PZkgYHE7NqbvwlnhYKfWqNca715W95r5PblOT+gpPUPPvqI9ekNNnBB8X36mL/S19Kn0rfS99MNAV1dym8c08ZR+/gW1eYxR</latexit>
<latexit sha1_base64="eVyoCO5GoHBdiLvdViQska8ik/Q=">AAAIEXicnVXLbtNQEJ22QEp4NIUlG4uoEgsakgqJLiuxYcEioKat1FaR7dykVv3CvqatonwFS7bwEewQW76AP4C/4Mxcp3k7FFtNx3PPnLnzuteJfS/V9fqvldW1W7fvlNbvlu/df/Bwo7L56CCNssRVLTfyo+TIsVPle6FqaU/76ihOlB04vjp0zl/z+uFHlaReFO7rq1idBnYv9Lqea2uo2pWNbrt/otWlTt1+bzAotyvVeq0ujzUrNHKhSvnTjDbXMjqhDkXkUkYBKQpJQ/bJphTvMTWoTjF0p9SHLoHkybqiAZVhmwGlgLChPcdvD1/HuTbEN3OmYu3Ci4+/BJYWbcEmAi6BzN4sWc+EmbWLuPvCyXu7wn8n5wqg1XQG7TK7IfJf7TgWTV3alRg8xBSLhqNzc5ZMssI7t8ai0mCIoWO5g/UEsiuWwzxbYpNK7JxbW9Z/C5K1/O3m2Iz+yC7N+/97ZVZf6nAB2eC3YWGN4Rfz76MfmLsL+3CC2bxbwplKJnbB64CV42Q769qqqEpnqKvJGmehO8Y98jDC+LLr80LGTHDTPJOMKXgCWJoatug9vZUKGj/MqqXGITgXe3IQX4RvrrwDxLy9x9hNhLiU9LAnGeGKbNMHsNoSEfu1chbTIcu6epTZeT4dmTC24h1yp3WgHfa+dT1LPJ9FvkKZfa6K6dV5vniKg9xSz3CbHuCJaNAL2qHnkJScOLUCv4H45bwNKzKY8TuNiWCbyARytxTVLCg4yWZPjSKkD4mj8wRrdnQziyJ0IKejlpOEp7cIO4qd93BZiE2hd1AXD9+ZTF0R+iJnNvjlmbtJXOaGWM45OvsXI2P0eFe0PZkgYHE7NqbvwlnhYKfWqNca715W95r5PblOT+gpPUPPvqI9ekNNnBB8X36mL/S19Kn0rfS99MNAV1dym8c08ZR+/gW1eYxR</latexit>
<latexit sha1_base64="eVyoCO5GoHBdiLvdViQska8ik/Q=">AAAIEXicnVXLbtNQEJ22QEp4NIUlG4uoEgsakgqJLiuxYcEioKat1FaR7dykVv3CvqatonwFS7bwEewQW76AP4C/4Mxcp3k7FFtNx3PPnLnzuteJfS/V9fqvldW1W7fvlNbvlu/df/Bwo7L56CCNssRVLTfyo+TIsVPle6FqaU/76ihOlB04vjp0zl/z+uFHlaReFO7rq1idBnYv9Lqea2uo2pWNbrt/otWlTt1+bzAotyvVeq0ujzUrNHKhSvnTjDbXMjqhDkXkUkYBKQpJQ/bJphTvMTWoTjF0p9SHLoHkybqiAZVhmwGlgLChPcdvD1/HuTbEN3OmYu3Ci4+/BJYWbcEmAi6BzN4sWc+EmbWLuPvCyXu7wn8n5wqg1XQG7TK7IfJf7TgWTV3alRg8xBSLhqNzc5ZMssI7t8ai0mCIoWO5g/UEsiuWwzxbYpNK7JxbW9Z/C5K1/O3m2Iz+yC7N+/97ZVZf6nAB2eC3YWGN4Rfz76MfmLsL+3CC2bxbwplKJnbB64CV42Q769qqqEpnqKvJGmehO8Y98jDC+LLr80LGTHDTPJOMKXgCWJoatug9vZUKGj/MqqXGITgXe3IQX4RvrrwDxLy9x9hNhLiU9LAnGeGKbNMHsNoSEfu1chbTIcu6epTZeT4dmTC24h1yp3WgHfa+dT1LPJ9FvkKZfa6K6dV5vniKg9xSz3CbHuCJaNAL2qHnkJScOLUCv4H45bwNKzKY8TuNiWCbyARytxTVLCg4yWZPjSKkD4mj8wRrdnQziyJ0IKejlpOEp7cIO4qd93BZiE2hd1AXD9+ZTF0R+iJnNvjlmbtJXOaGWM45OvsXI2P0eFe0PZkgYHE7NqbvwlnhYKfWqNca715W95r5PblOT+gpPUPPvqI9ekNNnBB8X36mL/S19Kn0rfS99MNAV1dym8c08ZR+/gW1eYxR</latexit>
Local CNN
f
l
<latexit sha1_base64="VXGnBpf+o/t8akLDsYEpkCr4iKM=">AAAIEXicnVXNbtNAEJ62QEr4aQpHLhZRJQ40JBUSPVZCSBw4FNS0ldoqsp1NasV/tde0VZSn4MgVHoIb4soT8AbwFnwz6zRJkzgUW03Hs998s/O368S+l+p6/dfS8sqt23dKq3fL9+4/eLhWWX+0n0ZZ4qqmG/lRcujYqfK9UDW1p311GCfKDhxfHTi917x+8FElqReFe/oyVieB3Q29jufaGqpWZa3T6h9rdaFTt+8PBuVWpVqv1eWxpoVGLlQpf3aj9ZWMjqlNEbmUUUCKQtKQfbIpxXtEDapTDN0J9aFLIHmyrmhAZdhmQCkgbGh7+O3i6yjXhvhmzlSsXXjx8ZfA0qIN2ETAJZDZmyXrmTCzdh53Xzh5b5f47+RcAbSaTqFdZDdE/qsdx6KpQ9sSg4eYYtFwdG7OkklWeOfWWFQaDDF0LLexnkB2xXKYZ0tsUomdc2vL+m9Bspa/3Ryb0R/ZpXn/f6/M6ksdziEb/CYsrDH8fP499ANzd2AfTjCbd0M4U8nENngdsHKcbGddWRVV6RR1NVnjLHTGuEceRhhfdt0rZMwEd51nkjEFTwBLU8MmfaB3UkHjh1m11DgE53xPDuKL8M2Vd4CYtfcYu4kQl5Ie9iQjXJFNOgOrLRGxXytnMR2yqKtHmZ3l05EJYyveIXdaG9ph71tXs8TzWeQrlNnnqpheneWLpzjILfUUt+kBnogGvaAteg5JyYlTK/AbiF/O27Aigym/1zERbBOZQO6WopoFBSfZ9KlRhPQhcXSeYM2ObmZRhA7kdNRykvD0FmFHsfMeLgqxKfQO6uLhO5OpK0Kf58wGvzhzN4nL3BCLOUdn/3xkjB7viLYrEwQsbsfG9btwWtjfqjXqtcb7l9WdN/k9uUpP6Ck9Q8++oh16S7s4Ifi+/Exf6GvpU+lb6Xvph4EuL+U2j2niKf38C9hKjEs=</latexit>
<latexit sha1_base64="VXGnBpf+o/t8akLDsYEpkCr4iKM=">AAAIEXicnVXNbtNAEJ62QEr4aQpHLhZRJQ40JBUSPVZCSBw4FNS0ldoqsp1NasV/tde0VZSn4MgVHoIb4soT8AbwFnwz6zRJkzgUW03Hs998s/O368S+l+p6/dfS8sqt23dKq3fL9+4/eLhWWX+0n0ZZ4qqmG/lRcujYqfK9UDW1p311GCfKDhxfHTi917x+8FElqReFe/oyVieB3Q29jufaGqpWZa3T6h9rdaFTt+8PBuVWpVqv1eWxpoVGLlQpf3aj9ZWMjqlNEbmUUUCKQtKQfbIpxXtEDapTDN0J9aFLIHmyrmhAZdhmQCkgbGh7+O3i6yjXhvhmzlSsXXjx8ZfA0qIN2ETAJZDZmyXrmTCzdh53Xzh5b5f47+RcAbSaTqFdZDdE/qsdx6KpQ9sSg4eYYtFwdG7OkklWeOfWWFQaDDF0LLexnkB2xXKYZ0tsUomdc2vL+m9Bspa/3Ryb0R/ZpXn/f6/M6ksdziEb/CYsrDH8fP499ANzd2AfTjCbd0M4U8nENngdsHKcbGddWRVV6RR1NVnjLHTGuEceRhhfdt0rZMwEd51nkjEFTwBLU8MmfaB3UkHjh1m11DgE53xPDuKL8M2Vd4CYtfcYu4kQl5Ie9iQjXJFNOgOrLRGxXytnMR2yqKtHmZ3l05EJYyveIXdaG9ph71tXs8TzWeQrlNnnqpheneWLpzjILfUUt+kBnogGvaAteg5JyYlTK/AbiF/O27Aigym/1zERbBOZQO6WopoFBSfZ9KlRhPQhcXSeYM2ObmZRhA7kdNRykvD0FmFHsfMeLgqxKfQO6uLhO5OpK0Kf58wGvzhzN4nL3BCLOUdn/3xkjB7viLYrEwQsbsfG9btwWtjfqjXqtcb7l9WdN/k9uUpP6Ck9Q8++oh16S7s4Ifi+/Exf6GvpU+lb6Xvph4EuL+U2j2niKf38C9hKjEs=</latexit>
<latexit sha1_base64="VXGnBpf+o/t8akLDsYEpkCr4iKM=">AAAIEXicnVXNbtNAEJ62QEr4aQpHLhZRJQ40JBUSPVZCSBw4FNS0ldoqsp1NasV/tde0VZSn4MgVHoIb4soT8AbwFnwz6zRJkzgUW03Hs998s/O368S+l+p6/dfS8sqt23dKq3fL9+4/eLhWWX+0n0ZZ4qqmG/lRcujYqfK9UDW1p311GCfKDhxfHTi917x+8FElqReFe/oyVieB3Q29jufaGqpWZa3T6h9rdaFTt+8PBuVWpVqv1eWxpoVGLlQpf3aj9ZWMjqlNEbmUUUCKQtKQfbIpxXtEDapTDN0J9aFLIHmyrmhAZdhmQCkgbGh7+O3i6yjXhvhmzlSsXXjx8ZfA0qIN2ETAJZDZmyXrmTCzdh53Xzh5b5f47+RcAbSaTqFdZDdE/qsdx6KpQ9sSg4eYYtFwdG7OkklWeOfWWFQaDDF0LLexnkB2xXKYZ0tsUomdc2vL+m9Bspa/3Ryb0R/ZpXn/f6/M6ksdziEb/CYsrDH8fP499ANzd2AfTjCbd0M4U8nENngdsHKcbGddWRVV6RR1NVnjLHTGuEceRhhfdt0rZMwEd51nkjEFTwBLU8MmfaB3UkHjh1m11DgE53xPDuKL8M2Vd4CYtfcYu4kQl5Ie9iQjXJFNOgOrLRGxXytnMR2yqKtHmZ3l05EJYyveIXdaG9ph71tXs8TzWeQrlNnnqpheneWLpzjILfUUt+kBnogGvaAteg5JyYlTK/AbiF/O27Aigym/1zERbBOZQO6WopoFBSfZ9KlRhPQhcXSeYM2ObmZRhA7kdNRykvD0FmFHsfMeLgqxKfQO6uLhO5OpK0Kf58wGvzhzN4nL3BCLOUdn/3xkjB7viLYrEwQsbsfG9btwWtjfqjXqtcb7l9WdN/k9uUpP6Ck9Q8++oh16S7s4Ifi+/Exf6GvpU+lb6Xvph4EuL+U2j2niKf38C9hKjEs=</latexit>
<latexit sha1_base64="VXGnBpf+o/t8akLDsYEpkCr4iKM=">AAAIEXicnVXNbtNAEJ62QEr4aQpHLhZRJQ40JBUSPVZCSBw4FNS0ldoqsp1NasV/tde0VZSn4MgVHoIb4soT8AbwFnwz6zRJkzgUW03Hs998s/O368S+l+p6/dfS8sqt23dKq3fL9+4/eLhWWX+0n0ZZ4qqmG/lRcujYqfK9UDW1p311GCfKDhxfHTi917x+8FElqReFe/oyVieB3Q29jufaGqpWZa3T6h9rdaFTt+8PBuVWpVqv1eWxpoVGLlQpf3aj9ZWMjqlNEbmUUUCKQtKQfbIpxXtEDapTDN0J9aFLIHmyrmhAZdhmQCkgbGh7+O3i6yjXhvhmzlSsXXjx8ZfA0qIN2ETAJZDZmyXrmTCzdh53Xzh5b5f47+RcAbSaTqFdZDdE/qsdx6KpQ9sSg4eYYtFwdG7OkklWeOfWWFQaDDF0LLexnkB2xXKYZ0tsUomdc2vL+m9Bspa/3Ryb0R/ZpXn/f6/M6ksdziEb/CYsrDH8fP499ANzd2AfTjCbd0M4U8nENngdsHKcbGddWRVV6RR1NVnjLHTGuEceRhhfdt0rZMwEd51nkjEFTwBLU8MmfaB3UkHjh1m11DgE53xPDuKL8M2Vd4CYtfcYu4kQl5Ie9iQjXJFNOgOrLRGxXytnMR2yqKtHmZ3l05EJYyveIXdaG9ph71tXs8TzWeQrlNnnqpheneWLpzjILfUUt+kBnogGvaAteg5JyYlTK/AbiF/O27Aigym/1zERbBOZQO6WopoFBSfZ9KlRhPQhcXSeYM2ObmZRhA7kdNRykvD0FmFHsfMeLgqxKfQO6uLhO5OpK0Kf58wGvzhzN4nL3BCLOUdn/3xkjB7viLYrEwQsbsfG9btwWtjfqjXqtcb7l9WdN/k9uUpP6Ck9Q8++oh16S7s4Ifi+/Exf6GvpU+lb6Xvph4EuL+U2j2niKf38C9hKjEs=</latexit>
Classifier
Policy
Network
˜v
t
<latexit sha1_base64="w8F+86psGabQNiGylBy1kJIoDBg=">AAAIEnicnVXNbtNAEJ62QEr5S+HIxSKqxIGGpEKix0oc4MChoKat1FSR7WxSK/7DXqdUUd6CI1d4CG6IKy/AG8Bb8M2s0yRN4lBsNZ2d/eabnb+1E/teqmu1Xyurazdu3iqt3964c/fe/QflzYeHaZQlrmq4kR8lx46dKt8LVUN72lfHcaLswPHVkdN7xftHfZWkXhQe6ItYnQZ2N/Q6nmtrqFrlctMJBk3t+W016A+HLd0qV2rVmjzWrFDPhQrlz360uZZRk9oUkUsZBaQoJA3ZJ5tSvCdUpxrF0J3SALoEkif7ioa0AdsMKAWEDW0Pv12sTnJtiDVzpmLtwouPvwSWFm3BJgIugczeLNnPhJm1i7gHwslnu8B/J+cKoNV0Bu0yuxHyX+04Fk0d2pUYPMQUi4ajc3OWTLLCJ7cmotJgiKFjuY39BLIrlqM8W2KTSuycW1v2fwuStbx2c2xGf+SU5v3/szKrL3U4h2zw27CwJvCL+Q/QD8zdgX04xWzeLeFMJRO74HXAynGynXVpVVSlM9TVZI2z0JngHnsYY3w5da+QMRPcVZ5pxhQ8ASxNDRv0nt5KBY0fZtVS4xCciz05iC/CmivvADHv7DFOEyEuJT3sSUa4Itv0Aay2RMR+rZzFdMiyrh5ndp5PRyaMrfiE3GltaEe9b13OEs9nka9QZp+rYnp1ni+e4iC31DPcpgd4Iur0nHboGSQlN061wG8gfjlvo4oMZ/xexUSwTWQCuVuKahYU3GSzt0YR0ofE0XmCNSe6nkUROpDbUctNwtNbhB3Hzmf4WIhNoXdQFw/rTKauCH2eMxv88sxdJy7zhVjOOb77FyNj9HhHtF2ZIGDxdaxf/RbOCoc71XqtWn/3orL3Ov9OrtNjekJP0bMvaY/e0D5uCJf69Jm+0NfSp9K30vfSDwNdXcltHtHUU/r5F0XBjQc=</latexit>
<latexit sha1_base64="w8F+86psGabQNiGylBy1kJIoDBg=">AAAIEnicnVXNbtNAEJ62QEr5S+HIxSKqxIGGpEKix0oc4MChoKat1FSR7WxSK/7DXqdUUd6CI1d4CG6IKy/AG8Bb8M2s0yRN4lBsNZ2d/eabnb+1E/teqmu1Xyurazdu3iqt3964c/fe/QflzYeHaZQlrmq4kR8lx46dKt8LVUN72lfHcaLswPHVkdN7xftHfZWkXhQe6ItYnQZ2N/Q6nmtrqFrlctMJBk3t+W016A+HLd0qV2rVmjzWrFDPhQrlz360uZZRk9oUkUsZBaQoJA3ZJ5tSvCdUpxrF0J3SALoEkif7ioa0AdsMKAWEDW0Pv12sTnJtiDVzpmLtwouPvwSWFm3BJgIugczeLNnPhJm1i7gHwslnu8B/J+cKoNV0Bu0yuxHyX+04Fk0d2pUYPMQUi4ajc3OWTLLCJ7cmotJgiKFjuY39BLIrlqM8W2KTSuycW1v2fwuStbx2c2xGf+SU5v3/szKrL3U4h2zw27CwJvCL+Q/QD8zdgX04xWzeLeFMJRO74HXAynGynXVpVVSlM9TVZI2z0JngHnsYY3w5da+QMRPcVZ5pxhQ8ASxNDRv0nt5KBY0fZtVS4xCciz05iC/CmivvADHv7DFOEyEuJT3sSUa4Itv0Aay2RMR+rZzFdMiyrh5ndp5PRyaMrfiE3GltaEe9b13OEs9nka9QZp+rYnp1ni+e4iC31DPcpgd4Iur0nHboGSQlN061wG8gfjlvo4oMZ/xexUSwTWQCuVuKahYU3GSzt0YR0ofE0XmCNSe6nkUROpDbUctNwtNbhB3Hzmf4WIhNoXdQFw/rTKauCH2eMxv88sxdJy7zhVjOOb77FyNj9HhHtF2ZIGDxdaxf/RbOCoc71XqtWn/3orL3Ov9OrtNjekJP0bMvaY/e0D5uCJf69Jm+0NfSp9K30vfSDwNdXcltHtHUU/r5F0XBjQc=</latexit>
<latexit sha1_base64="w8F+86psGabQNiGylBy1kJIoDBg=">AAAIEnicnVXNbtNAEJ62QEr5S+HIxSKqxIGGpEKix0oc4MChoKat1FSR7WxSK/7DXqdUUd6CI1d4CG6IKy/AG8Bb8M2s0yRN4lBsNZ2d/eabnb+1E/teqmu1Xyurazdu3iqt3964c/fe/QflzYeHaZQlrmq4kR8lx46dKt8LVUN72lfHcaLswPHVkdN7xftHfZWkXhQe6ItYnQZ2N/Q6nmtrqFrlctMJBk3t+W016A+HLd0qV2rVmjzWrFDPhQrlz360uZZRk9oUkUsZBaQoJA3ZJ5tSvCdUpxrF0J3SALoEkif7ioa0AdsMKAWEDW0Pv12sTnJtiDVzpmLtwouPvwSWFm3BJgIugczeLNnPhJm1i7gHwslnu8B/J+cKoNV0Bu0yuxHyX+04Fk0d2pUYPMQUi4ajc3OWTLLCJ7cmotJgiKFjuY39BLIrlqM8W2KTSuycW1v2fwuStbx2c2xGf+SU5v3/szKrL3U4h2zw27CwJvCL+Q/QD8zdgX04xWzeLeFMJRO74HXAynGynXVpVVSlM9TVZI2z0JngHnsYY3w5da+QMRPcVZ5pxhQ8ASxNDRv0nt5KBY0fZtVS4xCciz05iC/CmivvADHv7DFOEyEuJT3sSUa4Itv0Aay2RMR+rZzFdMiyrh5ndp5PRyaMrfiE3GltaEe9b13OEs9nka9QZp+rYnp1ni+e4iC31DPcpgd4Iur0nHboGSQlN061wG8gfjlvo4oMZ/xexUSwTWQCuVuKahYU3GSzt0YR0ofE0XmCNSe6nkUROpDbUctNwtNbhB3Hzmf4WIhNoXdQFw/rTKauCH2eMxv88sxdJy7zhVjOOb77FyNj9HhHtF2ZIGDxdaxf/RbOCoc71XqtWn/3orL3Ov9OrtNjekJP0bMvaY/e0D5uCJf69Jm+0NfSp9K30vfSDwNdXcltHtHUU/r5F0XBjQc=</latexit>
<latexit sha1_base64="w8F+86psGabQNiGylBy1kJIoDBg=">AAAIEnicnVXNbtNAEJ62QEr5S+HIxSKqxIGGpEKix0oc4MChoKat1FSR7WxSK/7DXqdUUd6CI1d4CG6IKy/AG8Bb8M2s0yRN4lBsNZ2d/eabnb+1E/teqmu1Xyurazdu3iqt3964c/fe/QflzYeHaZQlrmq4kR8lx46dKt8LVUN72lfHcaLswPHVkdN7xftHfZWkXhQe6ItYnQZ2N/Q6nmtrqFrlctMJBk3t+W016A+HLd0qV2rVmjzWrFDPhQrlz360uZZRk9oUkUsZBaQoJA3ZJ5tSvCdUpxrF0J3SALoEkif7ioa0AdsMKAWEDW0Pv12sTnJtiDVzpmLtwouPvwSWFm3BJgIugczeLNnPhJm1i7gHwslnu8B/J+cKoNV0Bu0yuxHyX+04Fk0d2pUYPMQUi4ajc3OWTLLCJ7cmotJgiKFjuY39BLIrlqM8W2KTSuycW1v2fwuStbx2c2xGf+SU5v3/szKrL3U4h2zw27CwJvCL+Q/QD8zdgX04xWzeLeFMJRO74HXAynGynXVpVVSlM9TVZI2z0JngHnsYY3w5da+QMRPcVZ5pxhQ8ASxNDRv0nt5KBY0fZtVS4xCciz05iC/CmivvADHv7DFOEyEuJT3sSUa4Itv0Aay2RMR+rZzFdMiyrh5ndp5PRyaMrfiE3GltaEe9b13OEs9nka9QZp+rYnp1ni+e4iC31DPcpgd4Iur0nHboGSQlN061wG8gfjlvo4oMZ/xexUSwTWQCuVuKahYU3GSzt0YR0ofE0XmCNSe6nkUROpDbUctNwtNbhB3Hzmf4WIhNoXdQFw/rTKauCH2eMxv88sxdJy7zhVjOOb77FyNj9HhHtF2ZIGDxdaxf/RbOCoc71XqtWn/3orL3Ov9OrtNjekJP0bMvaY/e0D5uCJf69Jm+0NfSp9K30vfSDwNdXcltHtHUU/r5F0XBjQc=</latexit>
Image Patch
v
t
<latexit sha1_base64="14SVys++q0sMxBtlo/MGbKgd7NY=">AAAICHicnVXLbtNQEJ22QEp5tbBkYxFVYkFDXCHRZSWExIJFQU0bqa0q27lJrfiFfd1SRfkBlmzhI9ghtvwFfwB/wZm5TvN2KLaajueeOXPnda+bBH6m6/VfS8srN27eqqzeXrtz9979B+sbDw+yOE891fDiIE6brpOpwI9UQ/s6UM0kVU7oBurQ7b7i9cNzlWZ+HO3ry0SdhE4n8tu+52iomsdu2Dvvn+rT9Wq9VpfHmhbsQqhS8ezFGys5HVOLYvIop5AURaQhB+RQhveIbKpTAt0J9aBLIfmyrqhPa7DNgVJAONB28dvB11GhjfDNnJlYe/AS4C+FpUWbsImBSyGzN0vWc2Fm7TzunnDy3i7x3y24Qmg1nUG7yG6A/Fc7jkVTm3YkBh8xJaLh6LyCJZes8M6tkag0GBLoWG5hPYXsieUgz5bYZBI759aR9d+CZC1/ewU2pz+yS/P+/16ZNZA6XEA2+C1YWCP4+fz76AfmbsM+GmM276ZwZpKJHfC6YOU42c66siqr0hnqarLGWWiPcA89DDGB7LpbypgLbpJnnDEDTwhLU8MGvae3UkHjh1m11DgC53xPLuKL8c2Vd4GYtfcEu4kRl5Ie9iUjXJEt+gBWRyJiv1bBYjpkUVcPMzvLpysTxla8Q+60FrSD3reuZonns8xXJLPPVTG9OssXT3FYWOopbtMDPBE2PadtegZJyYlTK/Ebil/O26Ai/Sm/k5gYtqlMIHdLWc3CkpNs+tQoQwaQODpfsGZH17MoQ4dyOmo5SXh6y7DD2HkPH0uxGfQu6uLjO5epK0NfFMwGvzhz14nL3BCLOYdn/3xkgh5vi7YjEwQsbkd78i6cFg62a3a9Zr97Ud19XdyTq/SYntBT9OxL2qU3tIcTgu/Az/SFvlY+Vb5Vvld+GOjyUmHziMaeys+/sFCJHg==</latexit>
<latexit sha1_base64="14SVys++q0sMxBtlo/MGbKgd7NY=">AAAICHicnVXLbtNQEJ22QEp5tbBkYxFVYkFDXCHRZSWExIJFQU0bqa0q27lJrfiFfd1SRfkBlmzhI9ghtvwFfwB/wZm5TvN2KLaajueeOXPnda+bBH6m6/VfS8srN27eqqzeXrtz9979B+sbDw+yOE891fDiIE6brpOpwI9UQ/s6UM0kVU7oBurQ7b7i9cNzlWZ+HO3ry0SdhE4n8tu+52iomsdu2Dvvn+rT9Wq9VpfHmhbsQqhS8ezFGys5HVOLYvIop5AURaQhB+RQhveIbKpTAt0J9aBLIfmyrqhPa7DNgVJAONB28dvB11GhjfDNnJlYe/AS4C+FpUWbsImBSyGzN0vWc2Fm7TzunnDy3i7x3y24Qmg1nUG7yG6A/Fc7jkVTm3YkBh8xJaLh6LyCJZes8M6tkag0GBLoWG5hPYXsieUgz5bYZBI759aR9d+CZC1/ewU2pz+yS/P+/16ZNZA6XEA2+C1YWCP4+fz76AfmbsM+GmM276ZwZpKJHfC6YOU42c66siqr0hnqarLGWWiPcA89DDGB7LpbypgLbpJnnDEDTwhLU8MGvae3UkHjh1m11DgC53xPLuKL8c2Vd4GYtfcEu4kRl5Ie9iUjXJEt+gBWRyJiv1bBYjpkUVcPMzvLpysTxla8Q+60FrSD3reuZonns8xXJLPPVTG9OssXT3FYWOopbtMDPBE2PadtegZJyYlTK/Ebil/O26Ai/Sm/k5gYtqlMIHdLWc3CkpNs+tQoQwaQODpfsGZH17MoQ4dyOmo5SXh6y7DD2HkPH0uxGfQu6uLjO5epK0NfFMwGvzhz14nL3BCLOYdn/3xkgh5vi7YjEwQsbkd78i6cFg62a3a9Zr97Ud19XdyTq/SYntBT9OxL2qU3tIcTgu/Az/SFvlY+Vb5Vvld+GOjyUmHziMaeys+/sFCJHg==</latexit>
<latexit sha1_base64="14SVys++q0sMxBtlo/MGbKgd7NY=">AAAICHicnVXLbtNQEJ22QEp5tbBkYxFVYkFDXCHRZSWExIJFQU0bqa0q27lJrfiFfd1SRfkBlmzhI9ghtvwFfwB/wZm5TvN2KLaajueeOXPnda+bBH6m6/VfS8srN27eqqzeXrtz9979B+sbDw+yOE891fDiIE6brpOpwI9UQ/s6UM0kVU7oBurQ7b7i9cNzlWZ+HO3ry0SdhE4n8tu+52iomsdu2Dvvn+rT9Wq9VpfHmhbsQqhS8ezFGys5HVOLYvIop5AURaQhB+RQhveIbKpTAt0J9aBLIfmyrqhPa7DNgVJAONB28dvB11GhjfDNnJlYe/AS4C+FpUWbsImBSyGzN0vWc2Fm7TzunnDy3i7x3y24Qmg1nUG7yG6A/Fc7jkVTm3YkBh8xJaLh6LyCJZes8M6tkag0GBLoWG5hPYXsieUgz5bYZBI759aR9d+CZC1/ewU2pz+yS/P+/16ZNZA6XEA2+C1YWCP4+fz76AfmbsM+GmM276ZwZpKJHfC6YOU42c66siqr0hnqarLGWWiPcA89DDGB7LpbypgLbpJnnDEDTwhLU8MGvae3UkHjh1m11DgC53xPLuKL8c2Vd4GYtfcEu4kRl5Ie9iUjXJEt+gBWRyJiv1bBYjpkUVcPMzvLpysTxla8Q+60FrSD3reuZonns8xXJLPPVTG9OssXT3FYWOopbtMDPBE2PadtegZJyYlTK/Ebil/O26Ai/Sm/k5gYtqlMIHdLWc3CkpNs+tQoQwaQODpfsGZH17MoQ4dyOmo5SXh6y7DD2HkPH0uxGfQu6uLjO5epK0NfFMwGvzhz14nL3BCLOYdn/3xkgh5vi7YjEwQsbkd78i6cFg62a3a9Zr97Ud19XdyTq/SYntBT9OxL2qU3tIcTgu/Az/SFvlY+Vb5Vvld+GOjyUmHziMaeys+/sFCJHg==</latexit>
<latexit sha1_base64="14SVys++q0sMxBtlo/MGbKgd7NY=">AAAICHicnVXLbtNQEJ22QEp5tbBkYxFVYkFDXCHRZSWExIJFQU0bqa0q27lJrfiFfd1SRfkBlmzhI9ghtvwFfwB/wZm5TvN2KLaajueeOXPnda+bBH6m6/VfS8srN27eqqzeXrtz9979B+sbDw+yOE891fDiIE6brpOpwI9UQ/s6UM0kVU7oBurQ7b7i9cNzlWZ+HO3ry0SdhE4n8tu+52iomsdu2Dvvn+rT9Wq9VpfHmhbsQqhS8ezFGys5HVOLYvIop5AURaQhB+RQhveIbKpTAt0J9aBLIfmyrqhPa7DNgVJAONB28dvB11GhjfDNnJlYe/AS4C+FpUWbsImBSyGzN0vWc2Fm7TzunnDy3i7x3y24Qmg1nUG7yG6A/Fc7jkVTm3YkBh8xJaLh6LyCJZes8M6tkag0GBLoWG5hPYXsieUgz5bYZBI759aR9d+CZC1/ewU2pz+yS/P+/16ZNZA6XEA2+C1YWCP4+fz76AfmbsM+GmM276ZwZpKJHfC6YOU42c66siqr0hnqarLGWWiPcA89DDGB7LpbypgLbpJnnDEDTwhLU8MGvae3UkHjh1m11DgC53xPLuKL8c2Vd4GYtfcEu4kRl5Ie9iUjXJEt+gBWRyJiv1bBYjpkUVcPMzvLpysTxla8Q+60FrSD3reuZonns8xXJLPPVTG9OssXT3FYWOopbtMDPBE2PadtegZJyYlTK/Ebil/O26Ai/Sm/k5gYtqlMIHdLWc3CkpNs+tQoQwaQODpfsGZH17MoQ4dyOmo5SXh6y7DD2HkPH0uxGfQu6uLjO5epK0NfFMwGvzhz14nL3BCLOYdn/3xkgh5vi7YjEwQsbkd78i6cFg62a3a9Zr97Ud19XdyTq/SYntBT9OxL2qU3tIcTgu/Az/SFvlY+Vb5Vvld+GOjyUmHziMaeys+/sFCJHg==</latexit>
Video Frame
p
t
<latexit sha1_base64="2ph0BqVh6va8OjPD4HEuw4Dlglg=">AAAICHicnVXLbtNQEJ22QEp5tbBkYxFVYkFDXCHRZSQ2LFgU1LSR2qqynZvUil/Y15Qqyg+wZAsfwQ6x5S/4A/gLzsx1mrdDsdV0PPfMmTuve90k8DNdr/9aWV27cfNWZf32xp279+4/2Nx6eJjFeeqpphcHcdpynUwFfqSa2teBaiWpckI3UEdu7xWvH31QaebH0YG+TNRp6HQjv+N7joaqdeKG/WRwps82q/VaXR5rVrALoUrFsx9vreV0Qm2KyaOcQlIUkYYckEMZ3mOyqU4JdKfUhy6F5Mu6ogFtwDYHSgHhQNvDbxdfx4U2wjdzZmLtwUuAvxSWFm3DJgYuhczeLFnPhZm1i7j7wsl7u8R/t+AKodV0Du0yuyHyX+04Fk0d2pMYfMSUiIaj8wqWXLLCO7fGotJgSKBjuY31FLInlsM8W2KTSeycW0fWfwuStfztFdic/sguzfv/e2XWQOpwAdngd2BhjeEX8x+gH5i7A/togtm828KZSSb2wOuCleNkO+vKqqxK56iryRpnoTPGPfIwwgSy614pYy64aZ5Jxgw8ISxNDZv0jt5IBY0fZtVS4wiciz25iC/GN1feBWLe3hPsJkZcSnrYl4xwRXboPVgdiYj9WgWL6ZBlXT3K7DyfrkwYW/EOudPa0A5737qaJZ7PMl+RzD5XxfTqPF88xWFhqWe4TQ/wRNj0nHbpGSQlJ06txG8ofjlvw4oMZvxOY2LYpjKB3C1lNQtLTrLZU6MMGUDi6HzBmh1dz6IMHcrpqOUk4ektw45i5z18LMVm0Luoi4/vXKauDH1RMBv88sxdJy5zQyznHJ39i5EJerwj2q5MELC4He3pu3BWONyt2fWa/fZFtdEo7sl1ekxP6Cl69iU16DXt44TgO/AzfaGvlU+Vb5XvlR8GurpS2Dyiiafy8y+BD4kT</latexit>
<latexit sha1_base64="2ph0BqVh6va8OjPD4HEuw4Dlglg=">AAAICHicnVXLbtNQEJ22QEp5tbBkYxFVYkFDXCHRZSQ2LFgU1LSR2qqynZvUil/Y15Qqyg+wZAsfwQ6x5S/4A/gLzsx1mrdDsdV0PPfMmTuve90k8DNdr/9aWV27cfNWZf32xp279+4/2Nx6eJjFeeqpphcHcdpynUwFfqSa2teBaiWpckI3UEdu7xWvH31QaebH0YG+TNRp6HQjv+N7joaqdeKG/WRwps82q/VaXR5rVrALoUrFsx9vreV0Qm2KyaOcQlIUkYYckEMZ3mOyqU4JdKfUhy6F5Mu6ogFtwDYHSgHhQNvDbxdfx4U2wjdzZmLtwUuAvxSWFm3DJgYuhczeLFnPhZm1i7j7wsl7u8R/t+AKodV0Du0yuyHyX+04Fk0d2pMYfMSUiIaj8wqWXLLCO7fGotJgSKBjuY31FLInlsM8W2KTSeycW0fWfwuStfztFdic/sguzfv/e2XWQOpwAdngd2BhjeEX8x+gH5i7A/togtm828KZSSb2wOuCleNkO+vKqqxK56iryRpnoTPGPfIwwgSy614pYy64aZ5Jxgw8ISxNDZv0jt5IBY0fZtVS4wiciz25iC/GN1feBWLe3hPsJkZcSnrYl4xwRXboPVgdiYj9WgWL6ZBlXT3K7DyfrkwYW/EOudPa0A5737qaJZ7PMl+RzD5XxfTqPF88xWFhqWe4TQ/wRNj0nHbpGSQlJ06txG8ofjlvw4oMZvxOY2LYpjKB3C1lNQtLTrLZU6MMGUDi6HzBmh1dz6IMHcrpqOUk4ektw45i5z18LMVm0Luoi4/vXKauDH1RMBv88sxdJy5zQyznHJ39i5EJerwj2q5MELC4He3pu3BWONyt2fWa/fZFtdEo7sl1ekxP6Cl69iU16DXt44TgO/AzfaGvlU+Vb5XvlR8GurpS2Dyiiafy8y+BD4kT</latexit>
<latexit sha1_base64="2ph0BqVh6va8OjPD4HEuw4Dlglg=">AAAICHicnVXLbtNQEJ22QEp5tbBkYxFVYkFDXCHRZSQ2LFgU1LSR2qqynZvUil/Y15Qqyg+wZAsfwQ6x5S/4A/gLzsx1mrdDsdV0PPfMmTuve90k8DNdr/9aWV27cfNWZf32xp279+4/2Nx6eJjFeeqpphcHcdpynUwFfqSa2teBaiWpckI3UEdu7xWvH31QaebH0YG+TNRp6HQjv+N7joaqdeKG/WRwps82q/VaXR5rVrALoUrFsx9vreV0Qm2KyaOcQlIUkYYckEMZ3mOyqU4JdKfUhy6F5Mu6ogFtwDYHSgHhQNvDbxdfx4U2wjdzZmLtwUuAvxSWFm3DJgYuhczeLFnPhZm1i7j7wsl7u8R/t+AKodV0Du0yuyHyX+04Fk0d2pMYfMSUiIaj8wqWXLLCO7fGotJgSKBjuY31FLInlsM8W2KTSeycW0fWfwuStfztFdic/sguzfv/e2XWQOpwAdngd2BhjeEX8x+gH5i7A/togtm828KZSSb2wOuCleNkO+vKqqxK56iryRpnoTPGPfIwwgSy614pYy64aZ5Jxgw8ISxNDZv0jt5IBY0fZtVS4wiciz25iC/GN1feBWLe3hPsJkZcSnrYl4xwRXboPVgdiYj9WgWL6ZBlXT3K7DyfrkwYW/EOudPa0A5737qaJZ7PMl+RzD5XxfTqPF88xWFhqWe4TQ/wRNj0nHbpGSQlJ06txG8ofjlvw4oMZvxOY2LYpjKB3C1lNQtLTrLZU6MMGUDi6HzBmh1dz6IMHcrpqOUk4ektw45i5z18LMVm0Luoi4/vXKauDH1RMBv88sxdJy5zQyznHJ39i5EJerwj2q5MELC4He3pu3BWONyt2fWa/fZFtdEo7sl1ekxP6Cl69iU16DXt44TgO/AzfaGvlU+Vb5XvlR8GurpS2Dyiiafy8y+BD4kT</latexit>
<latexit sha1_base64="2ph0BqVh6va8OjPD4HEuw4Dlglg=">AAAICHicnVXLbtNQEJ22QEp5tbBkYxFVYkFDXCHRZSQ2LFgU1LSR2qqynZvUil/Y15Qqyg+wZAsfwQ6x5S/4A/gLzsx1mrdDsdV0PPfMmTuve90k8DNdr/9aWV27cfNWZf32xp279+4/2Nx6eJjFeeqpphcHcdpynUwFfqSa2teBaiWpckI3UEdu7xWvH31QaebH0YG+TNRp6HQjv+N7joaqdeKG/WRwps82q/VaXR5rVrALoUrFsx9vreV0Qm2KyaOcQlIUkYYckEMZ3mOyqU4JdKfUhy6F5Mu6ogFtwDYHSgHhQNvDbxdfx4U2wjdzZmLtwUuAvxSWFm3DJgYuhczeLFnPhZm1i7j7wsl7u8R/t+AKodV0Du0yuyHyX+04Fk0d2pMYfMSUiIaj8wqWXLLCO7fGotJgSKBjuY31FLInlsM8W2KTSeycW0fWfwuStfztFdic/sguzfv/e2XWQOpwAdngd2BhjeEX8x+gH5i7A/togtm828KZSSb2wOuCleNkO+vKqqxK56iryRpnoTPGPfIwwgSy614pYy64aZ5Jxgw8ISxNDZv0jt5IBY0fZtVS4wiciz25iC/GN1feBWLe3hPsJkZcSnrYl4xwRXboPVgdiYj9WgWL6ZBlXT3K7DyfrkwYW/EOudPa0A5737qaJZ7PMl+RzD5XxfTqPF88xWFhqWe4TQ/wRNj0nHbpGSQlJ06txG8ofjlvw4oMZvxOY2LYpjKB3C1lNQtLTrLZU6MMGUDi6HzBmh1dz6IMHcrpqOUk4ektw45i5z18LMVm0Luoi4/vXKauDH1RMBv88sxdJy5zQyznHJ39i5EJerwj2q5MELC4He3pu3BWONyt2fWa/fZFtdEo7sl1ekxP6Cl69iU16DXt44TgO/AzfaGvlU+Vb5XvlR8GurpS2Dyiiafy8y+BD4kT</latexit>
⇡
<latexit sha1_base64="dFE2eW+rFkTgpSmL6js6MnSZTo0=">AAAIA3icnVVLT9RQFD6AWsQHoEs3jRMSFzK2xESWJG6McYHKAAkQ03buQDN92d6KhLB06VZ/hDvj1h/iP9B/4XfO7TDvjtiG4dxzv/Ode163fhaFhXacX3PzC9eu37AWby7dun3n7vLK6r3dIi3zQLWCNErzfd8rVBQmqqVDHan9LFde7Edqz+8+5/29DyovwjTZ0WeZOoq94yTshIGnoXp7mIXvVhpO05HHHhfcSmhQ9WynqwslHVKbUgqopJgUJaQhR+RRgfeAXHIog+6IzqHLIYWyr+iClmBbAqWA8KDt4vcYq4NKm2DNnIVYB/AS4S+HpU1rsEmByyGzN1v2S2Fm7TTuc+Hks53hv19xxdBqOoF2ll0P+a92HIumDm1KDCFiykTD0QUVSylZ4ZPbA1FpMGTQsdzGfg45EMtenm2xKSR2zq0n+78FyVpeBxW2pD9ySvP+/1mZNZI6nEI2+HVY2AP46fw76Afm7sA+GWI275pwFpKJTfD6YOU42c6+tKqr0gnqarLGWegMcPc99DGRnLpby1gKbpRnmLEATwxLU8MWvaFXUkHjh1m11DgB53RPPuJLsebK+0BMOnuG06SIS0kPh5IRrsg6vQerJxGxX7tiMR0yq6v7mZ3k05cJYys+IXdaG9pe79uXs8TzWecrkdnnqpheneSLpziuLPUYt+kBngiXntAGPYak5MZp1viNxS/nrVeRizG/o5gUtrlMIHdLXc3impts/NaoQ0aQOLpQsOZEV7OoQ8dyO2q5SXh667D92PkMH2uxBfQ+6hJiXcrU1aFPK2aDn525q8RlvhCzOft3/3Rkhh7viPZYJghYfB3d0W/huLC70XSdpvv6aWPrZfWdXKQH9JAeoWef0Ra9oG3cEAF4P9MX+mp9sr5Z360fBjo/V9ncp6HH+vkX8n+Gug==</latexit>
<latexit sha1_base64="dFE2eW+rFkTgpSmL6js6MnSZTo0=">AAAIA3icnVVLT9RQFD6AWsQHoEs3jRMSFzK2xESWJG6McYHKAAkQ03buQDN92d6KhLB06VZ/hDvj1h/iP9B/4XfO7TDvjtiG4dxzv/Ode163fhaFhXacX3PzC9eu37AWby7dun3n7vLK6r3dIi3zQLWCNErzfd8rVBQmqqVDHan9LFde7Edqz+8+5/29DyovwjTZ0WeZOoq94yTshIGnoXp7mIXvVhpO05HHHhfcSmhQ9WynqwslHVKbUgqopJgUJaQhR+RRgfeAXHIog+6IzqHLIYWyr+iClmBbAqWA8KDt4vcYq4NKm2DNnIVYB/AS4S+HpU1rsEmByyGzN1v2S2Fm7TTuc+Hks53hv19xxdBqOoF2ll0P+a92HIumDm1KDCFiykTD0QUVSylZ4ZPbA1FpMGTQsdzGfg45EMtenm2xKSR2zq0n+78FyVpeBxW2pD9ySvP+/1mZNZI6nEI2+HVY2AP46fw76Afm7sA+GWI275pwFpKJTfD6YOU42c6+tKqr0gnqarLGWegMcPc99DGRnLpby1gKbpRnmLEATwxLU8MWvaFXUkHjh1m11DgB53RPPuJLsebK+0BMOnuG06SIS0kPh5IRrsg6vQerJxGxX7tiMR0yq6v7mZ3k05cJYys+IXdaG9pe79uXs8TzWecrkdnnqpheneSLpziuLPUYt+kBngiXntAGPYak5MZp1viNxS/nrVeRizG/o5gUtrlMIHdLXc3impts/NaoQ0aQOLpQsOZEV7OoQ8dyO2q5SXh667D92PkMH2uxBfQ+6hJiXcrU1aFPK2aDn525q8RlvhCzOft3/3Rkhh7viPZYJghYfB3d0W/huLC70XSdpvv6aWPrZfWdXKQH9JAeoWef0Ra9oG3cEAF4P9MX+mp9sr5Z360fBjo/V9ncp6HH+vkX8n+Gug==</latexit>
<latexit sha1_base64="dFE2eW+rFkTgpSmL6js6MnSZTo0=">AAAIA3icnVVLT9RQFD6AWsQHoEs3jRMSFzK2xESWJG6McYHKAAkQ03buQDN92d6KhLB06VZ/hDvj1h/iP9B/4XfO7TDvjtiG4dxzv/Ode163fhaFhXacX3PzC9eu37AWby7dun3n7vLK6r3dIi3zQLWCNErzfd8rVBQmqqVDHan9LFde7Edqz+8+5/29DyovwjTZ0WeZOoq94yTshIGnoXp7mIXvVhpO05HHHhfcSmhQ9WynqwslHVKbUgqopJgUJaQhR+RRgfeAXHIog+6IzqHLIYWyr+iClmBbAqWA8KDt4vcYq4NKm2DNnIVYB/AS4S+HpU1rsEmByyGzN1v2S2Fm7TTuc+Hks53hv19xxdBqOoF2ll0P+a92HIumDm1KDCFiykTD0QUVSylZ4ZPbA1FpMGTQsdzGfg45EMtenm2xKSR2zq0n+78FyVpeBxW2pD9ySvP+/1mZNZI6nEI2+HVY2AP46fw76Afm7sA+GWI275pwFpKJTfD6YOU42c6+tKqr0gnqarLGWegMcPc99DGRnLpby1gKbpRnmLEATwxLU8MWvaFXUkHjh1m11DgB53RPPuJLsebK+0BMOnuG06SIS0kPh5IRrsg6vQerJxGxX7tiMR0yq6v7mZ3k05cJYys+IXdaG9pe79uXs8TzWecrkdnnqpheneSLpziuLPUYt+kBngiXntAGPYak5MZp1viNxS/nrVeRizG/o5gUtrlMIHdLXc3impts/NaoQ0aQOLpQsOZEV7OoQ8dyO2q5SXh667D92PkMH2uxBfQ+6hJiXcrU1aFPK2aDn525q8RlvhCzOft3/3Rkhh7viPZYJghYfB3d0W/huLC70XSdpvv6aWPrZfWdXKQH9JAeoWef0Ra9oG3cEAF4P9MX+mp9sr5Z360fBjo/V9ncp6HH+vkX8n+Gug==</latexit>
<latexit sha1_base64="dFE2eW+rFkTgpSmL6js6MnSZTo0=">AAAIA3icnVVLT9RQFD6AWsQHoEs3jRMSFzK2xESWJG6McYHKAAkQ03buQDN92d6KhLB06VZ/hDvj1h/iP9B/4XfO7TDvjtiG4dxzv/Ode163fhaFhXacX3PzC9eu37AWby7dun3n7vLK6r3dIi3zQLWCNErzfd8rVBQmqqVDHan9LFde7Edqz+8+5/29DyovwjTZ0WeZOoq94yTshIGnoXp7mIXvVhpO05HHHhfcSmhQ9WynqwslHVKbUgqopJgUJaQhR+RRgfeAXHIog+6IzqHLIYWyr+iClmBbAqWA8KDt4vcYq4NKm2DNnIVYB/AS4S+HpU1rsEmByyGzN1v2S2Fm7TTuc+Hks53hv19xxdBqOoF2ll0P+a92HIumDm1KDCFiykTD0QUVSylZ4ZPbA1FpMGTQsdzGfg45EMtenm2xKSR2zq0n+78FyVpeBxW2pD9ySvP+/1mZNZI6nEI2+HVY2AP46fw76Afm7sA+GWI275pwFpKJTfD6YOU42c6+tKqr0gnqarLGWegMcPc99DGRnLpby1gKbpRnmLEATwxLU8MWvaFXUkHjh1m11DgB53RPPuJLsebK+0BMOnuG06SIS0kPh5IRrsg6vQerJxGxX7tiMR0yq6v7mZ3k05cJYys+IXdaG9pe79uXs8TzWecrkdnnqpheneSLpziuLPUYt+kBngiXntAGPYak5MZp1viNxS/nrVeRizG/o5gUtrlMIHdLXc3impts/NaoQ0aQOLpQsOZEV7OoQ8dyO2q5SXh667D92PkMH2uxBfQ+6hJiXcrU1aFPK2aDn525q8RlvhCzOft3/3Rkhh7viPZYJghYfB3d0W/huLC70XSdpvv6aWPrZfWdXKQH9JAeoWef0Ra9oG3cEAF4P9MX+mp9sr5Z360fBjo/V9ncp6HH+vkX8n+Gug==</latexit>
Crop
C
f
c
<latexit sha1_base64="Xlq4arAc+IQXsRnM5wU6RY06/G8=">AAAIDnicnVXLbtNQEJ22QEp5tIUlG4uoEgsa4gqJLishJBYsCmraSm2pbOcmteIX9jVtFeUfWLKFj2CH2PIL/AH8BWfmOs3bodhqOnfumTN3XtduEviZrtd/LSwu3bh5q7J8e+XO3Xv3V9fWH+xncZ56quHFQZweuk6mAj9SDe3rQB0mqXJCN1AHbucl7x98VGnmx9GevkzUSei0I7/le46G6n3rtHus1YXOvK7X652uVeu1ujzWpGAXQpWKZzdeX8rpmJoUk0c5haQoIg05IIcyvEdkU50S6E6oC10KyZd9RT1agW0OlALCgbaD3zZWR4U2wpo5M7H24CXAXwpLizZgEwOXQmZvluznwszaWdxd4eSzXeK/W3CF0Go6g3aeXR/5r3Yci6YWbUsMPmJKRMPReQVLLlnhk1tDUWkwJNCx3MR+CtkTy36eLbHJJHbOrSP7vwXJWl57BTanP3JK8/7/WZk1kDqcQzb4TVhYQ/jZ/HvoB+ZuwT4aYTbvhnBmkolt8Lpg5TjZzrqyKqvSGepqssZZaA1xDzwMMIGculPKmAtunGeUMQNPCEtTwwa9ozdSQeOHWbXUOALnbE8u4oux5sq7QEw7e4LTxIhLSQ/7khGuyCZ9AKsjEbFfq2AxHTKvqweZnebTlQljKz4hd1oT2n7vW1ezxPNZ5iuS2eeqmF6d5ounOCws9QS36QGeCJue0RY9haTkxqmV+A3FL+etX5HehN9xTAzbVCaQu6WsZmHJTTZ5a5QhA0gcnS9Yc6LrWZShQ7kdtdwkPL1l2EHsfIaLUmwGvYu6+FjnMnVl6POC2eDnZ+46cZkvxHzOwd0/G5mgx1uibcsEAYuvoz3+LZwU9rdqdr1mv31e3XlVfCeX6RE9pifo2Re0Q69pFzcE99pn+kJfK58q3yrfKz8MdHGhsHlII0/l51/hiIv9</latexit>
<latexit sha1_base64="Xlq4arAc+IQXsRnM5wU6RY06/G8=">AAAIDnicnVXLbtNQEJ22QEp5tIUlG4uoEgsa4gqJLishJBYsCmraSm2pbOcmteIX9jVtFeUfWLKFj2CH2PIL/AH8BWfmOs3bodhqOnfumTN3XtduEviZrtd/LSwu3bh5q7J8e+XO3Xv3V9fWH+xncZ56quHFQZweuk6mAj9SDe3rQB0mqXJCN1AHbucl7x98VGnmx9GevkzUSei0I7/le46G6n3rtHus1YXOvK7X652uVeu1ujzWpGAXQpWKZzdeX8rpmJoUk0c5haQoIg05IIcyvEdkU50S6E6oC10KyZd9RT1agW0OlALCgbaD3zZWR4U2wpo5M7H24CXAXwpLizZgEwOXQmZvluznwszaWdxd4eSzXeK/W3CF0Go6g3aeXR/5r3Yci6YWbUsMPmJKRMPReQVLLlnhk1tDUWkwJNCx3MR+CtkTy36eLbHJJHbOrSP7vwXJWl57BTanP3JK8/7/WZk1kDqcQzb4TVhYQ/jZ/HvoB+ZuwT4aYTbvhnBmkolt8Lpg5TjZzrqyKqvSGepqssZZaA1xDzwMMIGculPKmAtunGeUMQNPCEtTwwa9ozdSQeOHWbXUOALnbE8u4oux5sq7QEw7e4LTxIhLSQ/7khGuyCZ9AKsjEbFfq2AxHTKvqweZnebTlQljKz4hd1oT2n7vW1ezxPNZ5iuS2eeqmF6d5ounOCws9QS36QGeCJue0RY9haTkxqmV+A3FL+etX5HehN9xTAzbVCaQu6WsZmHJTTZ5a5QhA0gcnS9Yc6LrWZShQ7kdtdwkPL1l2EHsfIaLUmwGvYu6+FjnMnVl6POC2eDnZ+46cZkvxHzOwd0/G5mgx1uibcsEAYuvoz3+LZwU9rdqdr1mv31e3XlVfCeX6RE9pifo2Re0Q69pFzcE99pn+kJfK58q3yrfKz8MdHGhsHlII0/l51/hiIv9</latexit>
<latexit sha1_base64="Xlq4arAc+IQXsRnM5wU6RY06/G8=">AAAIDnicnVXLbtNQEJ22QEp5tIUlG4uoEgsa4gqJLishJBYsCmraSm2pbOcmteIX9jVtFeUfWLKFj2CH2PIL/AH8BWfmOs3bodhqOnfumTN3XtduEviZrtd/LSwu3bh5q7J8e+XO3Xv3V9fWH+xncZ56quHFQZweuk6mAj9SDe3rQB0mqXJCN1AHbucl7x98VGnmx9GevkzUSei0I7/le46G6n3rtHus1YXOvK7X652uVeu1ujzWpGAXQpWKZzdeX8rpmJoUk0c5haQoIg05IIcyvEdkU50S6E6oC10KyZd9RT1agW0OlALCgbaD3zZWR4U2wpo5M7H24CXAXwpLizZgEwOXQmZvluznwszaWdxd4eSzXeK/W3CF0Go6g3aeXR/5r3Yci6YWbUsMPmJKRMPReQVLLlnhk1tDUWkwJNCx3MR+CtkTy36eLbHJJHbOrSP7vwXJWl57BTanP3JK8/7/WZk1kDqcQzb4TVhYQ/jZ/HvoB+ZuwT4aYTbvhnBmkolt8Lpg5TjZzrqyKqvSGepqssZZaA1xDzwMMIGculPKmAtunGeUMQNPCEtTwwa9ozdSQeOHWbXUOALnbE8u4oux5sq7QEw7e4LTxIhLSQ/7khGuyCZ9AKsjEbFfq2AxHTKvqweZnebTlQljKz4hd1oT2n7vW1ezxPNZ5iuS2eeqmF6d5ounOCws9QS36QGeCJue0RY9haTkxqmV+A3FL+etX5HehN9xTAzbVCaQu6WsZmHJTTZ5a5QhA0gcnS9Yc6LrWZShQ7kdtdwkPL1l2EHsfIaLUmwGvYu6+FjnMnVl6POC2eDnZ+46cZkvxHzOwd0/G5mgx1uibcsEAYuvoz3+LZwU9rdqdr1mv31e3XlVfCeX6RE9pifo2Re0Q69pFzcE99pn+kJfK58q3yrfKz8MdHGhsHlII0/l51/hiIv9</latexit>
<latexit sha1_base64="Xlq4arAc+IQXsRnM5wU6RY06/G8=">AAAIDnicnVXLbtNQEJ22QEp5tIUlG4uoEgsa4gqJLishJBYsCmraSm2pbOcmteIX9jVtFeUfWLKFj2CH2PIL/AH8BWfmOs3bodhqOnfumTN3XtduEviZrtd/LSwu3bh5q7J8e+XO3Xv3V9fWH+xncZ56quHFQZweuk6mAj9SDe3rQB0mqXJCN1AHbucl7x98VGnmx9GevkzUSei0I7/le46G6n3rtHus1YXOvK7X652uVeu1ujzWpGAXQpWKZzdeX8rpmJoUk0c5haQoIg05IIcyvEdkU50S6E6oC10KyZd9RT1agW0OlALCgbaD3zZWR4U2wpo5M7H24CXAXwpLizZgEwOXQmZvluznwszaWdxd4eSzXeK/W3CF0Go6g3aeXR/5r3Yci6YWbUsMPmJKRMPReQVLLlnhk1tDUWkwJNCx3MR+CtkTy36eLbHJJHbOrSP7vwXJWl57BTanP3JK8/7/WZk1kDqcQzb4TVhYQ/jZ/HvoB+ZuwT4aYTbvhnBmkolt8Lpg5TjZzrqyKqvSGepqssZZaA1xDzwMMIGculPKmAtunGeUMQNPCEtTwwa9ozdSQeOHWbXUOALnbE8u4oux5sq7QEw7e4LTxIhLSQ/7khGuyCZ9AKsjEbFfq2AxHTKvqweZnebTlQljKz4hd1oT2n7vW1ezxPNZ5iuS2eeqmF6d5ounOCws9QS36QGeCJue0RY9haTkxqmV+A3FL+etX5HehN9xTAzbVCaQu6WsZmHJTTZ5a5QhA0gcnS9Yc6LrWZShQ7kdtdwkPL1l2EHsfIaLUmwGvYu6+FjnMnVl6POC2eDnZ+46cZkvxHzOwd0/G5mgx1uibcsEAYuvoz3+LZwU9rdqdr1mv31e3XlVfCeX6RE9pifo2Re0Q69pFzcE99pn+kJfK58q3yrfKz8MdHGhsHlII0/l51/hiIv9</latexit>
Video Frame
v
t+1
<latexit sha1_base64="4IMAtnkbkATAAW+FI6dtfKiu7EQ=">AAAIKnicpVVLT9RQFD6AOogPQJduGickJsrYEhNZEt24cIGGARKGkLZzZ2imL9tbkExm529wqz/AX+OOuHWh/8LvnHaYdwdiG4bTc7/znXte9zqx76XaNC8XFpdu3b5TWb67cu/+g4era+uP9tMoS1xVdyM/Sg4dO1W+F6q69rSvDuNE2YHjqwOn85bXD85UknpRuKcvYnUc2O3Qa3muraFqNJyge9Y76ernVu9krWrWTHmMScEqhCoVz260vvSFGtSkiFzKKCBFIWnIPtmU4j0ii0yKoTumLnQJJE/WFfVoBbYZUAoIG9oOftv4Oiq0Ib6ZMxVrF158/CWwNGgDNhFwCWT2Zsh6JsysncXdFU7e2wX+OwVXAK2mU2jn2fWR17XjWDS1aFti8BBTLBqOzi1YMskK79wYikqDIYaO5SbWE8iuWPbzbIhNKrFzbm1Z/yNI1vK3W2Az+lsanQNWrsjKf0XCPn2p0jnkHL8JC2MIP5t/D93C3C3YhyPM+bshnKnkaRu8Dlg5C2xnXFmVRXmKquc55Ry1hrgHHgYYX3bdKWXMBDfOM8qYgieAZV7hOn2k91Lf3A+zaumAEJxlFYrwdqQvHCCm7T3GbiLEpaTDPckIV2STPoHVlojYr1Gw5P0zr+cHmZ3m05H5YyveIfdhE9r+ZBhXk8bTW+YrlJOBq5J38jRfPONBYaknuPMe4Hmx6CVt0QtISs6jWonfQPxy3voV6U34HcdEsE1kPrlb5k/Vdc+UMqQPiaPzBJvv6GYWZehAzk4t5wxPbxl2EDvv4XMpNoXeQV08fGcydWXo84I5x8/P3E3iyu+P+ZyDm2E2MkaPt0TblgkCFnenNX5TTgr7WzXLrFkfXlV33hS36DI9oaf0DD37mnboHe3ihHDB/ZW+0ffKj8rPymXlVw5dXChsHtPIU/n9D3ymkXg=</latexit>
<latexit sha1_base64="4IMAtnkbkATAAW+FI6dtfKiu7EQ=">AAAIKnicpVVLT9RQFD6AOogPQJduGickJsrYEhNZEt24cIGGARKGkLZzZ2imL9tbkExm529wqz/AX+OOuHWh/8LvnHaYdwdiG4bTc7/znXte9zqx76XaNC8XFpdu3b5TWb67cu/+g4era+uP9tMoS1xVdyM/Sg4dO1W+F6q69rSvDuNE2YHjqwOn85bXD85UknpRuKcvYnUc2O3Qa3muraFqNJyge9Y76ernVu9krWrWTHmMScEqhCoVz260vvSFGtSkiFzKKCBFIWnIPtmU4j0ii0yKoTumLnQJJE/WFfVoBbYZUAoIG9oOftv4Oiq0Ib6ZMxVrF158/CWwNGgDNhFwCWT2Zsh6JsysncXdFU7e2wX+OwVXAK2mU2jn2fWR17XjWDS1aFti8BBTLBqOzi1YMskK79wYikqDIYaO5SbWE8iuWPbzbIhNKrFzbm1Z/yNI1vK3W2Az+lsanQNWrsjKf0XCPn2p0jnkHL8JC2MIP5t/D93C3C3YhyPM+bshnKnkaRu8Dlg5C2xnXFmVRXmKquc55Ry1hrgHHgYYX3bdKWXMBDfOM8qYgieAZV7hOn2k91Lf3A+zaumAEJxlFYrwdqQvHCCm7T3GbiLEpaTDPckIV2STPoHVlojYr1Gw5P0zr+cHmZ3m05H5YyveIfdhE9r+ZBhXk8bTW+YrlJOBq5J38jRfPONBYaknuPMe4Hmx6CVt0QtISs6jWonfQPxy3voV6U34HcdEsE1kPrlb5k/Vdc+UMqQPiaPzBJvv6GYWZehAzk4t5wxPbxl2EDvv4XMpNoXeQV08fGcydWXo84I5x8/P3E3iyu+P+ZyDm2E2MkaPt0TblgkCFnenNX5TTgr7WzXLrFkfXlV33hS36DI9oaf0DD37mnboHe3ihHDB/ZW+0ffKj8rPymXlVw5dXChsHtPIU/n9D3ymkXg=</latexit>
<latexit sha1_base64="4IMAtnkbkATAAW+FI6dtfKiu7EQ=">AAAIKnicpVVLT9RQFD6AOogPQJduGickJsrYEhNZEt24cIGGARKGkLZzZ2imL9tbkExm529wqz/AX+OOuHWh/8LvnHaYdwdiG4bTc7/znXte9zqx76XaNC8XFpdu3b5TWb67cu/+g4era+uP9tMoS1xVdyM/Sg4dO1W+F6q69rSvDuNE2YHjqwOn85bXD85UknpRuKcvYnUc2O3Qa3muraFqNJyge9Y76ernVu9krWrWTHmMScEqhCoVz260vvSFGtSkiFzKKCBFIWnIPtmU4j0ii0yKoTumLnQJJE/WFfVoBbYZUAoIG9oOftv4Oiq0Ib6ZMxVrF158/CWwNGgDNhFwCWT2Zsh6JsysncXdFU7e2wX+OwVXAK2mU2jn2fWR17XjWDS1aFti8BBTLBqOzi1YMskK79wYikqDIYaO5SbWE8iuWPbzbIhNKrFzbm1Z/yNI1vK3W2Az+lsanQNWrsjKf0XCPn2p0jnkHL8JC2MIP5t/D93C3C3YhyPM+bshnKnkaRu8Dlg5C2xnXFmVRXmKquc55Ry1hrgHHgYYX3bdKWXMBDfOM8qYgieAZV7hOn2k91Lf3A+zaumAEJxlFYrwdqQvHCCm7T3GbiLEpaTDPckIV2STPoHVlojYr1Gw5P0zr+cHmZ3m05H5YyveIfdhE9r+ZBhXk8bTW+YrlJOBq5J38jRfPONBYaknuPMe4Hmx6CVt0QtISs6jWonfQPxy3voV6U34HcdEsE1kPrlb5k/Vdc+UMqQPiaPzBJvv6GYWZehAzk4t5wxPbxl2EDvv4XMpNoXeQV08fGcydWXo84I5x8/P3E3iyu+P+ZyDm2E2MkaPt0TblgkCFnenNX5TTgr7WzXLrFkfXlV33hS36DI9oaf0DD37mnboHe3ihHDB/ZW+0ffKj8rPymXlVw5dXChsHtPIU/n9D3ymkXg=</latexit>
<latexit sha1_base64="4IMAtnkbkATAAW+FI6dtfKiu7EQ=">AAAIKnicpVVLT9RQFD6AOogPQJduGickJsrYEhNZEt24cIGGARKGkLZzZ2imL9tbkExm529wqz/AX+OOuHWh/8LvnHaYdwdiG4bTc7/znXte9zqx76XaNC8XFpdu3b5TWb67cu/+g4era+uP9tMoS1xVdyM/Sg4dO1W+F6q69rSvDuNE2YHjqwOn85bXD85UknpRuKcvYnUc2O3Qa3muraFqNJyge9Y76ernVu9krWrWTHmMScEqhCoVz260vvSFGtSkiFzKKCBFIWnIPtmU4j0ii0yKoTumLnQJJE/WFfVoBbYZUAoIG9oOftv4Oiq0Ib6ZMxVrF158/CWwNGgDNhFwCWT2Zsh6JsysncXdFU7e2wX+OwVXAK2mU2jn2fWR17XjWDS1aFti8BBTLBqOzi1YMskK79wYikqDIYaO5SbWE8iuWPbzbIhNKrFzbm1Z/yNI1vK3W2Az+lsanQNWrsjKf0XCPn2p0jnkHL8JC2MIP5t/D93C3C3YhyPM+bshnKnkaRu8Dlg5C2xnXFmVRXmKquc55Ry1hrgHHgYYX3bdKWXMBDfOM8qYgieAZV7hOn2k91Lf3A+zaumAEJxlFYrwdqQvHCCm7T3GbiLEpaTDPckIV2STPoHVlojYr1Gw5P0zr+cHmZ3m05H5YyveIfdhE9r+ZBhXk8bTW+YrlJOBq5J38jRfPONBYaknuPMe4Hmx6CVt0QtISs6jWonfQPxy3voV6U34HcdEsE1kPrlb5k/Vdc+UMqQPiaPzBJvv6GYWZehAzk4t5wxPbxl2EDvv4XMpNoXeQV08fGcydWXo84I5x8/P3E3iyu+P+ZyDm2E2MkaPt0TblgkCFnenNX5TTgr7WzXLrFkfXlV33hS36DI9oaf0DD37mnboHe3ihHDB/ZW+0ffKj8rPymXlVw5dXChsHtPIU/n9D3ymkXg=</latexit>
Image Patch
˜v
t+1
<latexit sha1_base64="zAHqG2sa2TM4o6Pbv/S6B+FvN1c=">AAAINHicpVVLT9RQFD6AOogvUHduGickJsrQEhNZEt24cIGGARKGkLZzB5rpy/YWxMns/CFu9Qf4X0zcGRPd+Bv8zmmHeXcgtmE4Pfc737nnda8T+16qTfP73PzCtes3Kos3l27dvnP33vLK/d00yhJX1d3Ij5J9x06V74Wqrj3tq/04UXbg+GrPab/i9b1TlaReFO7o81gdBvZx6LU819ZQHS0/bDhBp6E9v6k6p93uUUc/tbpHy1WzZspjjAtWIVSpeLajlYVP1KAmReRSRgEpCklD9smmFO8BWWRSDN0hdaBLIHmyrqhLS7DNgFJA2NC28XuMr4NCG+KbOVOxduHFx18CS4NWYRMBl0Bmb4asZ8LM2mncHeHkvZ3jv1NwBdBqOoF2ll0PeVk7jkVTizYlBg8xxaLh6NyCJZOs8M6Ngag0GGLoWG5iPYHsimUvz4bYpBI759aW9d+CZC1/uwU2oz+l0Tlg5Yos/Vck7NOXKp1BzvFrsDAG8NP5d9AtzN2CfTjEnL+rwplKnjbB64CVs8B2xoVVWZQnqHqeU85Ra4C776GP8WXX7VLGTHCjPMOMKXgCWOYVrtM7eiP1zf0wq5YOCMFZVqEIb1v6wgFi0t5j7CZCXEo63JOMcEXW6D1YbYmI/RoFS94/s3q+n9lJPh2ZP7biHXIfNqHtTYZxMWk8vWW+QjkZuCp5J0/yxTMeFJZ6jDvvAZ4Xi9Zpg55BUnIe1Ur8BuKX89arSHfM7ygmgm0i88ndMnuqLnumlCF9SBydJ9h8R1ezKEMHcnZqOWd4esuw/dh5Dx9KsSn0Duri4TuTqStDnxXMOX525q4SV35/zObs3wzTkTF6vCXaY5kgYHF3WqM35biwu1GzzJr19nl162Vxiy7SI3pMT9CzL2iLXtM2TgiXPtJn+kJfK98qPyo/K79y6PxcYfOAhp7K33+KV5Vf</latexit>
<latexit sha1_base64="zAHqG2sa2TM4o6Pbv/S6B+FvN1c=">AAAINHicpVVLT9RQFD6AOogvUHduGickJsrQEhNZEt24cIGGARKGkLZzB5rpy/YWxMns/CFu9Qf4X0zcGRPd+Bv8zmmHeXcgtmE4Pfc737nnda8T+16qTfP73PzCtes3Kos3l27dvnP33vLK/d00yhJX1d3Ij5J9x06V74Wqrj3tq/04UXbg+GrPab/i9b1TlaReFO7o81gdBvZx6LU819ZQHS0/bDhBp6E9v6k6p93uUUc/tbpHy1WzZspjjAtWIVSpeLajlYVP1KAmReRSRgEpCklD9smmFO8BWWRSDN0hdaBLIHmyrqhLS7DNgFJA2NC28XuMr4NCG+KbOVOxduHFx18CS4NWYRMBl0Bmb4asZ8LM2mncHeHkvZ3jv1NwBdBqOoF2ll0PeVk7jkVTizYlBg8xxaLh6NyCJZOs8M6Ngag0GGLoWG5iPYHsimUvz4bYpBI759aW9d+CZC1/uwU2oz+l0Tlg5Yos/Vck7NOXKp1BzvFrsDAG8NP5d9AtzN2CfTjEnL+rwplKnjbB64CVs8B2xoVVWZQnqHqeU85Ra4C776GP8WXX7VLGTHCjPMOMKXgCWOYVrtM7eiP1zf0wq5YOCMFZVqEIb1v6wgFi0t5j7CZCXEo63JOMcEXW6D1YbYmI/RoFS94/s3q+n9lJPh2ZP7biHXIfNqHtTYZxMWk8vWW+QjkZuCp5J0/yxTMeFJZ6jDvvAZ4Xi9Zpg55BUnIe1Ur8BuKX89arSHfM7ygmgm0i88ndMnuqLnumlCF9SBydJ9h8R1ezKEMHcnZqOWd4esuw/dh5Dx9KsSn0Duri4TuTqStDnxXMOX525q4SV35/zObs3wzTkTF6vCXaY5kgYHF3WqM35biwu1GzzJr19nl162Vxiy7SI3pMT9CzL2iLXtM2TgiXPtJn+kJfK98qPyo/K79y6PxcYfOAhp7K33+KV5Vf</latexit>
<latexit sha1_base64="zAHqG2sa2TM4o6Pbv/S6B+FvN1c=">AAAINHicpVVLT9RQFD6AOogvUHduGickJsrQEhNZEt24cIGGARKGkLZzB5rpy/YWxMns/CFu9Qf4X0zcGRPd+Bv8zmmHeXcgtmE4Pfc737nnda8T+16qTfP73PzCtes3Kos3l27dvnP33vLK/d00yhJX1d3Ij5J9x06V74Wqrj3tq/04UXbg+GrPab/i9b1TlaReFO7o81gdBvZx6LU819ZQHS0/bDhBp6E9v6k6p93uUUc/tbpHy1WzZspjjAtWIVSpeLajlYVP1KAmReRSRgEpCklD9smmFO8BWWRSDN0hdaBLIHmyrqhLS7DNgFJA2NC28XuMr4NCG+KbOVOxduHFx18CS4NWYRMBl0Bmb4asZ8LM2mncHeHkvZ3jv1NwBdBqOoF2ll0PeVk7jkVTizYlBg8xxaLh6NyCJZOs8M6Ngag0GGLoWG5iPYHsimUvz4bYpBI759aW9d+CZC1/uwU2oz+l0Tlg5Yos/Vck7NOXKp1BzvFrsDAG8NP5d9AtzN2CfTjEnL+rwplKnjbB64CVs8B2xoVVWZQnqHqeU85Ra4C776GP8WXX7VLGTHCjPMOMKXgCWOYVrtM7eiP1zf0wq5YOCMFZVqEIb1v6wgFi0t5j7CZCXEo63JOMcEXW6D1YbYmI/RoFS94/s3q+n9lJPh2ZP7biHXIfNqHtTYZxMWk8vWW+QjkZuCp5J0/yxTMeFJZ6jDvvAZ4Xi9Zpg55BUnIe1Ur8BuKX89arSHfM7ygmgm0i88ndMnuqLnumlCF9SBydJ9h8R1ezKEMHcnZqOWd4esuw/dh5Dx9KsSn0Duri4TuTqStDnxXMOX525q4SV35/zObs3wzTkTF6vCXaY5kgYHF3WqM35biwu1GzzJr19nl162Vxiy7SI3pMT9CzL2iLXtM2TgiXPtJn+kJfK98qPyo/K79y6PxcYfOAhp7K33+KV5Vf</latexit>
<latexit sha1_base64="zAHqG2sa2TM4o6Pbv/S6B+FvN1c=">AAAINHicpVVLT9RQFD6AOogvUHduGickJsrQEhNZEt24cIGGARKGkLZzB5rpy/YWxMns/CFu9Qf4X0zcGRPd+Bv8zmmHeXcgtmE4Pfc737nnda8T+16qTfP73PzCtes3Kos3l27dvnP33vLK/d00yhJX1d3Ij5J9x06V74Wqrj3tq/04UXbg+GrPab/i9b1TlaReFO7o81gdBvZx6LU819ZQHS0/bDhBp6E9v6k6p93uUUc/tbpHy1WzZspjjAtWIVSpeLajlYVP1KAmReRSRgEpCklD9smmFO8BWWRSDN0hdaBLIHmyrqhLS7DNgFJA2NC28XuMr4NCG+KbOVOxduHFx18CS4NWYRMBl0Bmb4asZ8LM2mncHeHkvZ3jv1NwBdBqOoF2ll0PeVk7jkVTizYlBg8xxaLh6NyCJZOs8M6Ngag0GGLoWG5iPYHsimUvz4bYpBI759aW9d+CZC1/uwU2oz+l0Tlg5Yos/Vck7NOXKp1BzvFrsDAG8NP5d9AtzN2CfTjEnL+rwplKnjbB64CVs8B2xoVVWZQnqHqeU85Ra4C776GP8WXX7VLGTHCjPMOMKXgCWOYVrtM7eiP1zf0wq5YOCMFZVqEIb1v6wgFi0t5j7CZCXEo63JOMcEXW6D1YbYmI/RoFS94/s3q+n9lJPh2ZP7biHXIfNqHtTYZxMWk8vWW+QjkZuCp5J0/yxTMeFJZ6jDvvAZ4Xi9Zpg55BUnIe1Ur8BuKX89arSHfM7ygmgm0i88ndMnuqLnumlCF9SBydJ9h8R1ezKEMHcnZqOWd4esuw/dh5Dx9KsSn0Duri4TuTqStDnxXMOX525q4SV35/zObs3wzTkTF6vCXaY5kgYHF3WqM35biwu1GzzJr19nl162Vxiy7SI3pMT9CzL2iLXtM2TgiXPtJn+kJfK98qPyo/K79y6PxcYfOAhp7K33+KV5Vf</latexit>
……
… …
…
…
Prediction
p
t+1
<latexit sha1_base64="JDX8TVi2JfVOd9iBGUsNpiFA3FA=">AAAIKnicpVXLbtNQEJ22QEp4tbBkYxFVQoIGu0Kiywo2LFgU1LSVmqqynZvUil/Y15Qqyo5vYAsfwNewq9iygL/gzNhp3k4rbDUdzz1z5s7rXif2vVSb5sXS8sqNm7cqq7erd+7eu/9gbf3hfhpliasabuRHyaFjp8r3QtXQnvbVYZwoO3B8deB03/D6wSeVpF4U7unzWB0Hdif02p5ra6iaTSfoxf2Tnn5m9U/WambdlMeYFqxCqFHx7EbrK1+oSS2KyKWMAlIUkobsk00p3iOyyKQYumPqQZdA8mRdUZ+qsM2AUkDY0Hbx28HXUaEN8c2cqVi78OLjL4GlQRuwiYBLILM3Q9YzYWbtPO6ecPLezvHfKbgCaDWdQrvIboC8qh3HoqlN2xKDh5hi0XB0bsGSSVZ458ZIVBoMMXQst7CeQHbFcpBnQ2xSiZ1za8v6H0Gylr/dApvR39LoHLByRar/FQn79KVKZ5Bz/CYsjBH8fP49dAtzt2EfjjHn74ZwppKnbfA6YOUssJ1xaVUW5SmqnueUc9Qe4R56GGJ82XW3lDET3CTPOGMKngCWeYUb9IHeSX1zP8yqpQNCcJZVKMLblb5wgJi19xi7iRCXkg73JCNckU36CFZbImK/RsGS98+inh9mdpZPR+aPrXiH3IctaAeTYVxOGk9vma9QTgauSt7Js3zxjAeFpZ7iznuA58WiF7RFzyEpOY/qJX4D8ct5G1SkP+V3EhPBNpH55G5ZPFVXPVPKkD4kjs4TbL6j61mUoQM5O7WcMzy9Zdhh7LyHz6XYFHoHdfHwncnUlaHPCuYcvzhz14krvz8Wcw5vhvnIGD3eFm1HJghY3J3W5E05Lexv1S2zbr1/Wdt5Xdyiq/SYntBT9Owr2qG3tIsTwgX3V/pG3ys/Kj8rF5VfOXR5qbB5RGNP5fc/ThqRcg==</latexit>
<latexit sha1_base64="JDX8TVi2JfVOd9iBGUsNpiFA3FA=">AAAIKnicpVXLbtNQEJ22QEp4tbBkYxFVQoIGu0Kiywo2LFgU1LSVmqqynZvUil/Y15Qqyo5vYAsfwNewq9iygL/gzNhp3k4rbDUdzz1z5s7rXif2vVSb5sXS8sqNm7cqq7erd+7eu/9gbf3hfhpliasabuRHyaFjp8r3QtXQnvbVYZwoO3B8deB03/D6wSeVpF4U7unzWB0Hdif02p5ra6iaTSfoxf2Tnn5m9U/WambdlMeYFqxCqFHx7EbrK1+oSS2KyKWMAlIUkobsk00p3iOyyKQYumPqQZdA8mRdUZ+qsM2AUkDY0Hbx28HXUaEN8c2cqVi78OLjL4GlQRuwiYBLILM3Q9YzYWbtPO6ecPLezvHfKbgCaDWdQrvIboC8qh3HoqlN2xKDh5hi0XB0bsGSSVZ458ZIVBoMMXQst7CeQHbFcpBnQ2xSiZ1za8v6H0Gylr/dApvR39LoHLByRar/FQn79KVKZ5Bz/CYsjBH8fP49dAtzt2EfjjHn74ZwppKnbfA6YOUssJ1xaVUW5SmqnueUc9Qe4R56GGJ82XW3lDET3CTPOGMKngCWeYUb9IHeSX1zP8yqpQNCcJZVKMLblb5wgJi19xi7iRCXkg73JCNckU36CFZbImK/RsGS98+inh9mdpZPR+aPrXiH3IctaAeTYVxOGk9vma9QTgauSt7Js3zxjAeFpZ7iznuA58WiF7RFzyEpOY/qJX4D8ct5G1SkP+V3EhPBNpH55G5ZPFVXPVPKkD4kjs4TbL6j61mUoQM5O7WcMzy9Zdhh7LyHz6XYFHoHdfHwncnUlaHPCuYcvzhz14krvz8Wcw5vhvnIGD3eFm1HJghY3J3W5E05Lexv1S2zbr1/Wdt5Xdyiq/SYntBT9Owr2qG3tIsTwgX3V/pG3ys/Kj8rF5VfOXR5qbB5RGNP5fc/ThqRcg==</latexit>
<latexit sha1_base64="JDX8TVi2JfVOd9iBGUsNpiFA3FA=">AAAIKnicpVXLbtNQEJ22QEp4tbBkYxFVQoIGu0Kiywo2LFgU1LSVmqqynZvUil/Y15Qqyo5vYAsfwNewq9iygL/gzNhp3k4rbDUdzz1z5s7rXif2vVSb5sXS8sqNm7cqq7erd+7eu/9gbf3hfhpliasabuRHyaFjp8r3QtXQnvbVYZwoO3B8deB03/D6wSeVpF4U7unzWB0Hdif02p5ra6iaTSfoxf2Tnn5m9U/WambdlMeYFqxCqFHx7EbrK1+oSS2KyKWMAlIUkobsk00p3iOyyKQYumPqQZdA8mRdUZ+qsM2AUkDY0Hbx28HXUaEN8c2cqVi78OLjL4GlQRuwiYBLILM3Q9YzYWbtPO6ecPLezvHfKbgCaDWdQrvIboC8qh3HoqlN2xKDh5hi0XB0bsGSSVZ458ZIVBoMMXQst7CeQHbFcpBnQ2xSiZ1za8v6H0Gylr/dApvR39LoHLByRar/FQn79KVKZ5Bz/CYsjBH8fP49dAtzt2EfjjHn74ZwppKnbfA6YOUssJ1xaVUW5SmqnueUc9Qe4R56GGJ82XW3lDET3CTPOGMKngCWeYUb9IHeSX1zP8yqpQNCcJZVKMLblb5wgJi19xi7iRCXkg73JCNckU36CFZbImK/RsGS98+inh9mdpZPR+aPrXiH3IctaAeTYVxOGk9vma9QTgauSt7Js3zxjAeFpZ7iznuA58WiF7RFzyEpOY/qJX4D8ct5G1SkP+V3EhPBNpH55G5ZPFVXPVPKkD4kjs4TbL6j61mUoQM5O7WcMzy9Zdhh7LyHz6XYFHoHdfHwncnUlaHPCuYcvzhz14krvz8Wcw5vhvnIGD3eFm1HJghY3J3W5E05Lexv1S2zbr1/Wdt5Xdyiq/SYntBT9Owr2qG3tIsTwgX3V/pG3ys/Kj8rF5VfOXR5qbB5RGNP5fc/ThqRcg==</latexit>
<latexit sha1_base64="JDX8TVi2JfVOd9iBGUsNpiFA3FA=">AAAIKnicpVXLbtNQEJ22QEp4tbBkYxFVQoIGu0Kiywo2LFgU1LSVmqqynZvUil/Y15Qqyo5vYAsfwNewq9iygL/gzNhp3k4rbDUdzz1z5s7rXif2vVSb5sXS8sqNm7cqq7erd+7eu/9gbf3hfhpliasabuRHyaFjp8r3QtXQnvbVYZwoO3B8deB03/D6wSeVpF4U7unzWB0Hdif02p5ra6iaTSfoxf2Tnn5m9U/WambdlMeYFqxCqFHx7EbrK1+oSS2KyKWMAlIUkobsk00p3iOyyKQYumPqQZdA8mRdUZ+qsM2AUkDY0Hbx28HXUaEN8c2cqVi78OLjL4GlQRuwiYBLILM3Q9YzYWbtPO6ecPLezvHfKbgCaDWdQrvIboC8qh3HoqlN2xKDh5hi0XB0bsGSSVZ458ZIVBoMMXQst7CeQHbFcpBnQ2xSiZ1za8v6H0Gylr/dApvR39LoHLByRar/FQn79KVKZ5Bz/CYsjBH8fP49dAtzt2EfjjHn74ZwppKnbfA6YOUssJ1xaVUW5SmqnueUc9Qe4R56GGJ82XW3lDET3CTPOGMKngCWeYUb9IHeSX1zP8yqpQNCcJZVKMLblb5wgJi19xi7iRCXkg73JCNckU36CFZbImK/RsGS98+inh9mdpZPR+aPrXiH3IctaAeTYVxOGk9vma9QTgauSt7Js3zxjAeFpZ7iznuA58WiF7RFzyEpOY/qJX4D8ct5G1SkP+V3EhPBNpH55G5ZPFVXPVPKkD4kjs4TbL6j61mUoQM5O7WcMzy9Zdhh7LyHz6XYFHoHdfHwncnUlaHPCuYcvzhz14krvz8Wcw5vhvnIGD3eFm1HJghY3J3W5E05Lexv1S2zbr1/Wdt5Xdyiq/SYntBT9Owr2qG3tIsTwgX3V/pG3ys/Kj8rF5VfOXR5qbB5RGNP5fc/ThqRcg==</latexit>
Recurrent
Networks
Forward
Identity
Updating
Hidden
State
C
Concatenation
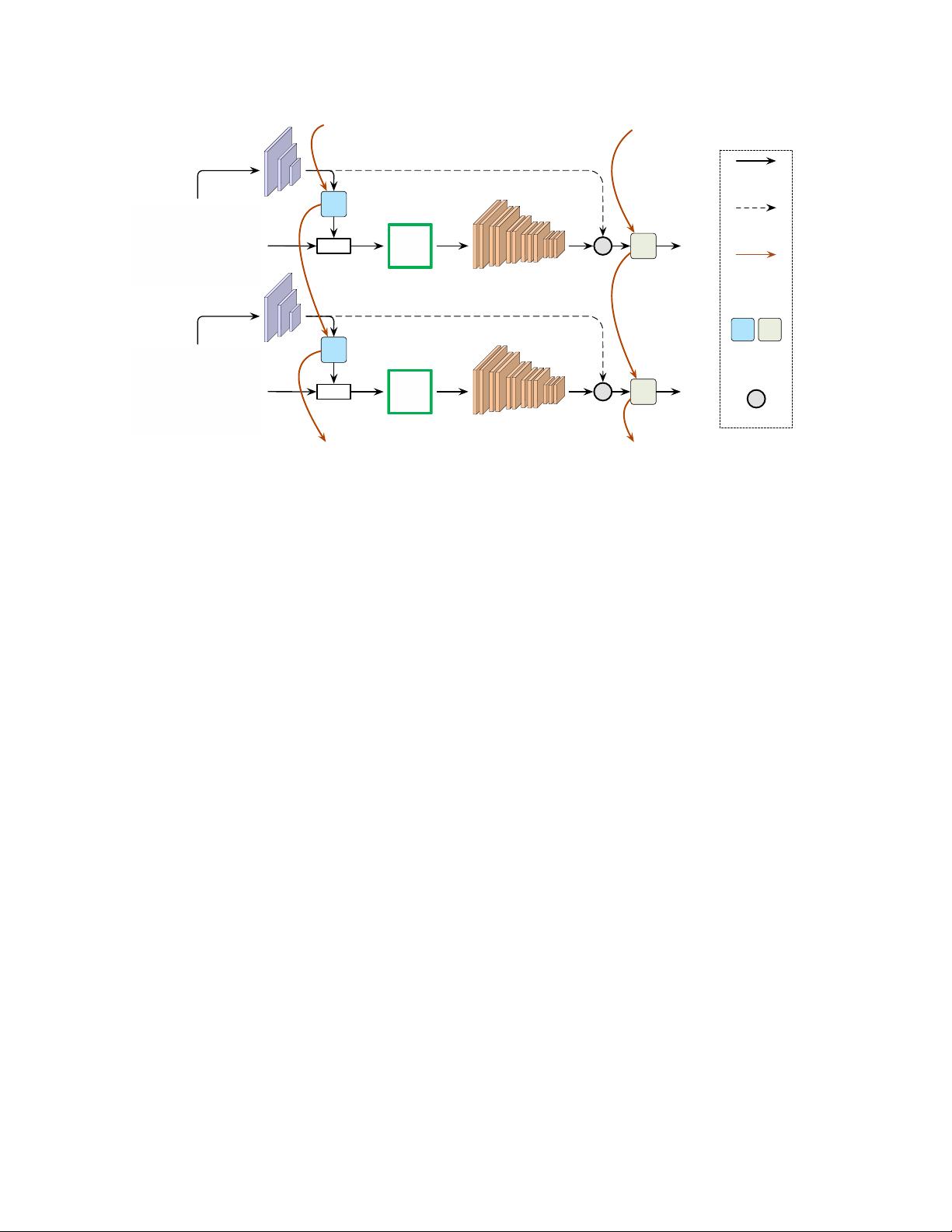
Figure 2. Overview of AdaFocus. It first takes a quick glance at each frame v
t
using a light-weighted global CNN f
G
. Then a recurrent
policy network π is built on top of f
G
to select the most important image region
˜
v
t
in terms of recognition. A high-capacity local CNN f
L
is adopted to extract features from
˜
v
t
. Finally, a recurrent classifier aggregates the features across frames to obtain the prediction p
t
.
3. Method
Different from most existing works that facilitate effi-
cient video recognition by leveraging the temporal redun-
dancy, we seek to save the computation spent on the task-
irrelevant regions of video frames, and thus improve the ef-
ficiency by reducing the spatial redundancy. To this end, we
propose an adaptive focus (AdaFocus) framework to adap-
tively identify and attend to the most informative regions of
each frame, such that the computational cost can be signifi-
cantly reduced without sacrificing accuracy.
In this section, we first describe its components and the
correspond training algorithm in Section 3.1 and Section
3.2, respectively. Then we show in Section 3.3 that AdaFo-
cus can be improved by further considering temporal redun-
dancy (e.g., skipping uninformative frames).
3.1. Network Architecture
Overview. We first give an overview of AdaFocus (Fig-
ure 2). Consider the online video recognition scenario,
where a stream of frames come in sequentially while a pre-
diction may be retrieved after processing any number of
frames. At each time step, AdaFocus first takes a quick
glance at the full frame with a light-weighted CNN f
G
, ob-
taining cheap and coarse global features. Then the features
are fed into a recurrent policy network π to aggregate the in-
formation across frames and accordingly determine the lo-
cation of an image patch to be focused on, under the goal of
maximizing its contribution to video recognition. A high-
capacity local CNN f
L
is then adopted to process the se-
lected patch for more accurate but computationally expen-
sive representations. Finally, a classifier f
C
integrates the
features of all previous frames to produce a prediction. In
the following, we describe these four components in details.
Global CNN f
G
and local CNN f
L
are backbone net-
works that both extract deep features from the inputs, but
with distinct aims. The former is designed to quickly catch
a glimpse of each frame, providing necessary information
for determining which region the local CNN f
L
should at-
tend to. Therefore, a light-weighted network is adopted for
f
G
. On the contrary, f
L
is leveraged to take full advantage of
the selected image regions for learning discriminative repre-
sentations, and hence we deploy large and accurate models.
Since f
L
only needs to process a series of relatively small re-
gions instead of the full images, this stage also enjoys high
efficiency. We defer the details on the architectures of f
G
and f
L
to Section 4.
Formally, given video frames {v
1
, v
2
, . . .}with size H×
W , f
G
directly takes them as inputs and produces the coarse
global feature maps e
G
t
:
e
G
t
= f
G
(v
t
), t = 1, 2, . . . , (1)
where t is the frame index. By contrast, f
L
processes P ×P
(P < H, W ) square image patches {
˜
v
1
,
˜
v
2
, . . .}, which are
cropped from {v
1
, v
2
, . . .} respectively, and we have
e
L
t
= f
L
(
˜
v
t
), t = 1, 2, . . . , (2)
where e
L
t
denotes the fine local feature maps. Importantly,
the patch
˜
v
t
is localized to capture the most informative re-
剩余11页未读,继续阅读
2021-10-25 上传
2018-12-24 上传
点击了解资源详情
点击了解资源详情
2024-12-02 上传
2024-12-02 上传
2024-12-02 上传
2024-12-02 上传
2024-12-02 上传

AI算法攻城狮
- 粉丝: 1w+
- 资源: 39
 我的内容管理
展开
我的内容管理
展开







最新资源
- WordPress作为新闻管理面板的实现指南
- NPC_Generator:使用Ruby打造的游戏角色生成器
- MATLAB实现变邻域搜索算法源码解析
- 探索C++并行编程:使用INTEL TBB的项目实践
- 玫枫跟打器:网页版五笔打字工具,提升macOS打字效率
- 萨尔塔·阿萨尔·希塔斯:SATINDER项目解析
- 掌握变邻域搜索算法:MATLAB代码实践
- saaraansh: 简化法律文档,打破语言障碍的智能应用
- 探索牛角交友盲盒系统:PHP开源交友平台的新选择
- 探索Nullfactory-SSRSExtensions: 强化SQL Server报告服务
- Lotide:一套JavaScript实用工具库的深度解析
- 利用Aurelia 2脚手架搭建新项目的快速指南
- 变邻域搜索算法Matlab实现教程
- 实战指南:构建高效ES+Redis+MySQL架构解决方案
- GitHub Pages入门模板快速启动指南
- NeonClock遗产版:包名更迭与应用更新
