




深入理解Hadoop分布式文件系统HDFS
版权申诉
DOCX格式 | 698KB |
更新于2024-08-09
| 154 浏览量 | 举报
"Hadoop分布式文件系统详解文档详细阐述了Hadoop的架构以及其核心组件HDFS的体系结构,重点解析了NameNode的功能和运作机制,包括元数据信息、文件操作、副本策略以及心跳机制。"
在大数据处理领域,Hadoop是一个关键的开源框架,它设计用于处理和存储海量数据。Hadoop主要由三个模块构成:分布式存储系统Hadoop Distributed File System (HDFS),分布式计算模型MapReduce,以及资源调度引擎YARN。HDFS是Hadoop的基础,它以高可用性和容错性为目标,为大规模数据存储提供解决方案。
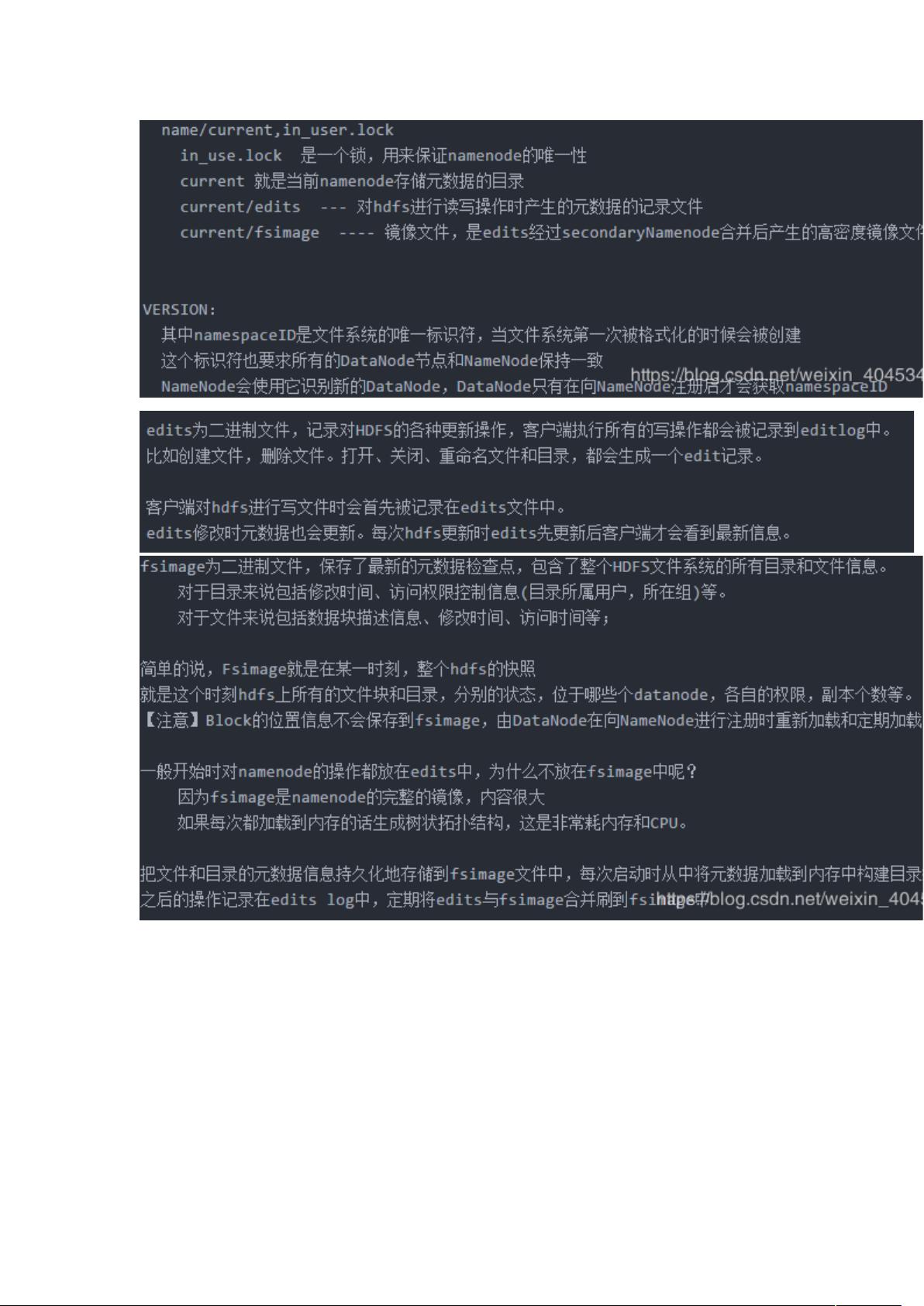
HDFS的体系架构中,NameNode扮演着至关重要的角色。NameNode是HDFS的主节点,负责整个文件系统的命名空间管理和文件元数据的维护。它保存了文件系统的目录结构,以及文件到数据块的映射和数据块到DataNode的映射。元数据信息包括文件名、文件的目录结构、文件属性(如生成时间、副本数量、权限)以及文件的块列表和块与DataNode的映射关系。这些信息存储在内存中,并定期保存到本地磁盘,但不持久化块的位置信息,这些信息在系统启动时由DataNodes在注册过程中重建并报告给NameNode。
NameNode执行文件元数据的操作,如创建、删除、重命名文件或目录,而实际的文件内容读写操作由DataNodes处理。当客户端请求读写文件时,NameNode指示客户端直接与相应的DataNode通信,数据流不通过NameNode,从而提高了效率。此外,NameNode还决定了文件数据块的副本位置,旨在优化数据访问速度和降低网络带宽消耗。
NameNode采用心跳机制来监控DataNodes的状态。DataNodes周期性地发送心跳信号和块的状态报告,表明它们还在正常工作。如果NameNode在一定时间内未收到某个DataNode的心跳,它将认为该DataNode故障,并开始重新复制其上的数据块,以确保数据的安全性和冗余。
Hadoop的NameNode是HDFS的核心组件,负责数据存储的逻辑布局和管理,确保了整个分布式文件系统的高效稳定运行。通过理解NameNode的工作原理,可以更好地理解和优化Hadoop集群的性能和可靠性。
下载后可阅读完整内容,剩余13页未读,立即下载
查看更多
相关推荐


jane9872
- 粉丝: 110
 我的内容管理
展开
我的内容管理
展开








最新资源
- Linux下nginx 1.12版本负载均衡的部署与应用
- Laravel微服务日志处理器:附加相关ID
- Nginx1.9.7与Keepalive1.3.2搭建高可用集群
- C++进阶课程全新讲义:深入理解与实践
- Java数据分析项目源代码详解
- 实现PDF跳转打印功能的pdfobject.js技术解析
- 最新Navicat for SQLite 12.0.26版本mac下载
- Qt框架下的QWidget进程间通信技术详解
- 保护隐私:U盘移动硬盘加密与解密工具
- Linux进程调度算法设计与性能比较
- JavaMail必备:javamail1_4_5和jaf-1_1_1 Jar包使用指南
- C#实现邮箱发送与验证的源代码解析
- PHP节假日公告网页开发与MySQL数据库整合
- LabVIEW控制安捷伦直流电源教程
- Linux网络驱动开发技术文档详解
- Java单点登录(SSO)系统开发全流程教程










