手写HashMap:理解putVal()的5参数与哈希计算
需积分: 0 126 浏览量
更新于2024-08-04
收藏 346KB DOCX 举报
在Java编程中,HashMap是一种常用的数据结构,它内部采用数组和链表(在JDK 1.8及以上版本中,当链表长度超过8时,会转变为红黑树)的设计。本文主要介绍HashMap的`putVal()`方法及其相关的几个关键参数,以及它们在实现中的作用。
`putVal()`方法有五个参数,其中第一个参数是`hash`,这是通过计算键的哈希值来确定键值对在数组中的存储位置。哈希值的计算公式是 `(数组长度 - 1) & hash`,这里的`&`操作符表示按位与,将hashCode值与数组长度减一的结果进行位运算,目的是使结果落在数组的有效索引范围内。
第二个参数`onlyIfAbsent`是一个布尔值,表示如果目标位置不存在键值对(不存在或其值为null),则执行插入操作。如果该位置已有键值对,且键相同但值不等,HashMap会覆盖原有的值。
在理解HashMap内部的工作原理时,我们需要知道如何通过键(key)找到其在数组中的存储位置。首先,计算键的`hashCode`,如示例中的字符串"abcd"的`hashCode`为2987074。接下来,通过无符号右移运算(`>>>`)去除hashCode的低16位,补零后得到新的散列值,如2987074右移16位后变为45。
接着,使用按位异或(`^`)运算,将键的原始`hashCode`与散列值进行操作,以进一步分散键值对的分布。例如,与"abcd"的原始`hashCode`进行异或后,得到2987119。
在实际应用中,为了优化查找效率,HashMap需要均匀地将键值对分布在数组中,避免过多的散列冲突。理想情况下,每个数组元素对应一个链表,存储若干个键值对。如果键值对过多导致冲突严重,可能会导致查询性能下降,此时就需要通过调整数组大小或者使用更高效的哈希策略来改善。
总结来说,理解HashMap的`putVal()`方法和其内部的哈希过程对于掌握这种数据结构的关键操作至关重要,特别是对于处理大规模数据时,合理利用这些算法技巧能显著提升程序的性能。在实际开发中,开发者需根据应用场景选择合适的哈希函数和负载因子,以达到最佳的数据存储和查询效率。
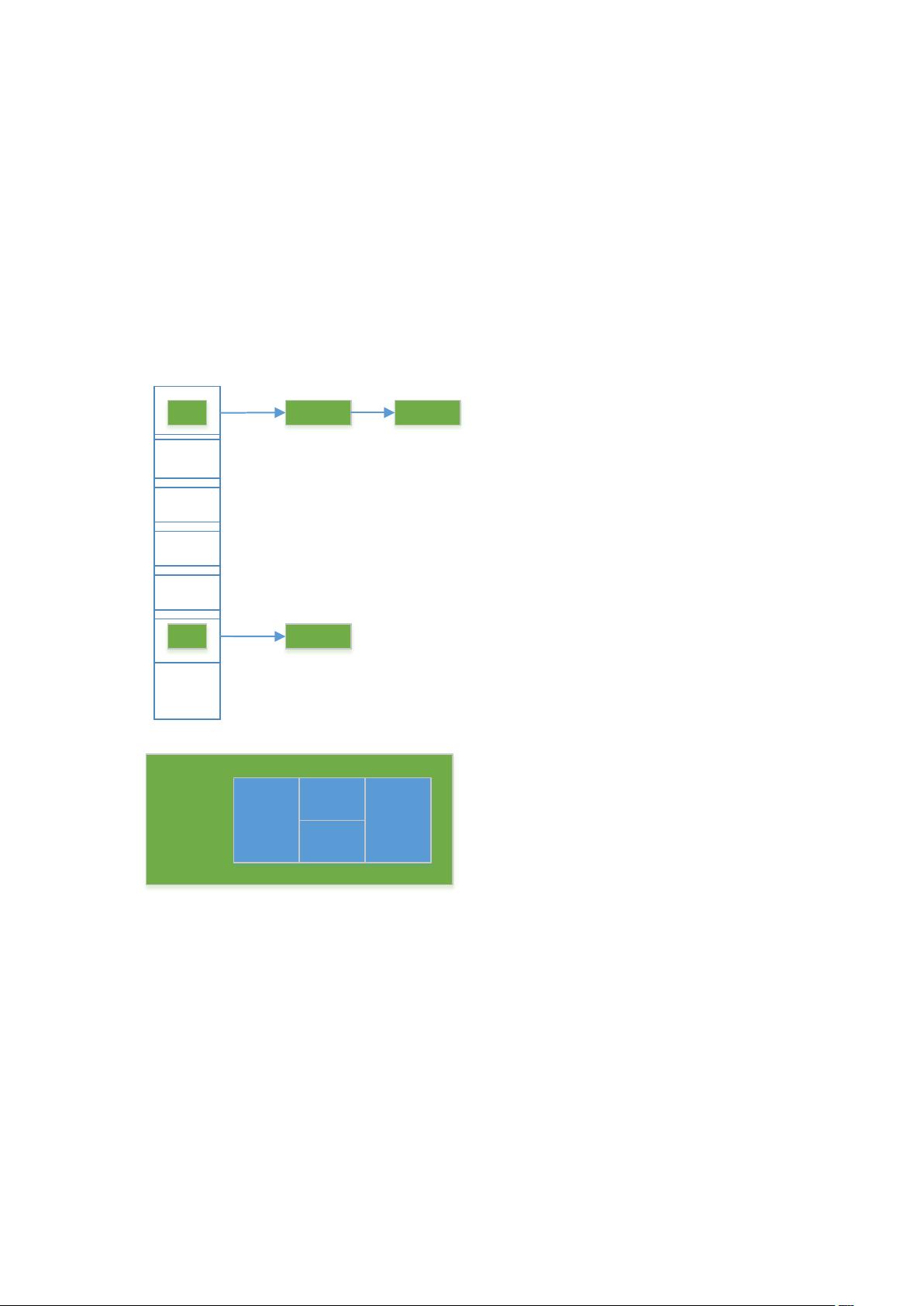
Java 知识点 手写 HashMap
结构
HashMap 是数组+链表(在 JDK1.8 中,如果链表长度大于 8,则改为红黑树)。
如图:
数组
链表
HashMap 里存的都是 Node 对象,Node 的组成如图:
Hash
Node
Next
Key
Value
背景知识点
如何通过 key,获取存储位置
首先通过 key 的 hashCode 值,然后无符号右移运算、按位异或运算。
无符号右移
例:10>>>2=2
下载后可阅读完整内容,剩余7页未读,立即下载
183 浏览量
点击了解资源详情
点击了解资源详情
138 浏览量
104 浏览量
2019-07-13 上传
342 浏览量
126 浏览量
2019-07-27 上传

马李灵珊
- 粉丝: 41
- 资源: 297
 我的内容管理
展开
我的内容管理
展开







最新资源
- ASP_NET的十大技巧
- Gimp中文经典入门实用教程
- DOS批处理高级教程精选合编
- 鸟哥的linux详细教程
- Java 极限编程PDF
- HPUX系统优化简述-公众第一版
- Symbian C++入门
- PXI Express技术一本通
- 单片机学习-编程基础
- LCD1602的驱动
- IBM Redbook - 商务智能认证指导 (Business Intelligence Certification Guide)
- Minimum[1].unix.commands.for.DBAs.pdf
- aaaaaaaaaaaaaaaaaaaaaa
- Fusioncharts报表工具帮助
- 基于C_的高校图书资料管理系统的设计
- python核心编程
