Python爬虫实战:抓取豆瓣Top250电影信息
需积分: 22 42 浏览量
更新于2024-08-04
收藏 758KB PDF 举报
"本资源提供了一个完整的Python爬虫示例,用于爬取豆瓣电影Top250的电影信息,包括电影链接、图片、标题、评分、评价人数和简介。"
在Python爬虫开发中,首先要做的是进行准备工作,确保Python环境已经安装了必要的库。在这个示例中,用到的库包括`bs4`(BeautifulSoup)用于解析HTML,`re`(正则表达式)用于提取数据,`urllib.request`和`urllib.error`用于处理HTTP请求和错误,以及`xlwt`用于将数据写入Excel文件。
接下来是代码示例部分,主要包含两个函数:`main()`和`getData()`。`main()`函数是整个程序的入口点,它调用`getData()`函数来获取数据,并将结果保存到Excel文件中。`getData()`函数负责实际的网络请求和数据解析工作。
1. `getData()`函数:
- 使用`baseurl`作为起始URL,通过增加`start`参数遍历豆瓣Top250的每一页。每页有25部电影,因此循环10次即可获取全部250部电影。
- 对于每个URL,`askURL(url)`函数负责发送HTTP请求获取HTML内容。
- 解析HTML内容时,使用BeautifulSoup创建一个解析器对象`soup`。
- 使用`find_all('div', class_="item")`找到包含每部电影信息的`div`元素。
- 遍历这些元素,对每个元素进行正则表达式匹配,提取出电影的链接、图片、标题、评分、评价人数和简介。
2. 正则表达式的作用:
- `findLink`用于查找电影详情页的链接。
- `findImgsrc`用于查找电影海报的图片源。
- `findTitle`用于获取电影的名称。
- `findRating`用于提取电影的平均评分。
- `findNum`用于找出评价人数。
- `findInq`用于抓取电影的短评。
- `findBd`用于获取电影的简介内容。
3. 数据存储:
- 收集到的数据以列表形式存储在`datalist`中,每个列表元素代表一部电影的所有信息。
- `saveData(datalist, savepath)`函数将`datalist`中的数据写入Excel文件,路径由`savepath`指定。
通过这个示例,我们可以学习如何使用Python进行网页抓取,包括发送HTTP请求、解析HTML、使用正则表达式提取信息以及数据的存储。同时,这也展示了如何处理分页问题,以及在实际项目中如何组织和结构化代码。对于初学者来说,这是一个很好的实践项目,有助于理解和掌握Python爬虫的基本流程。
爬虫 | python爬虫示例代码
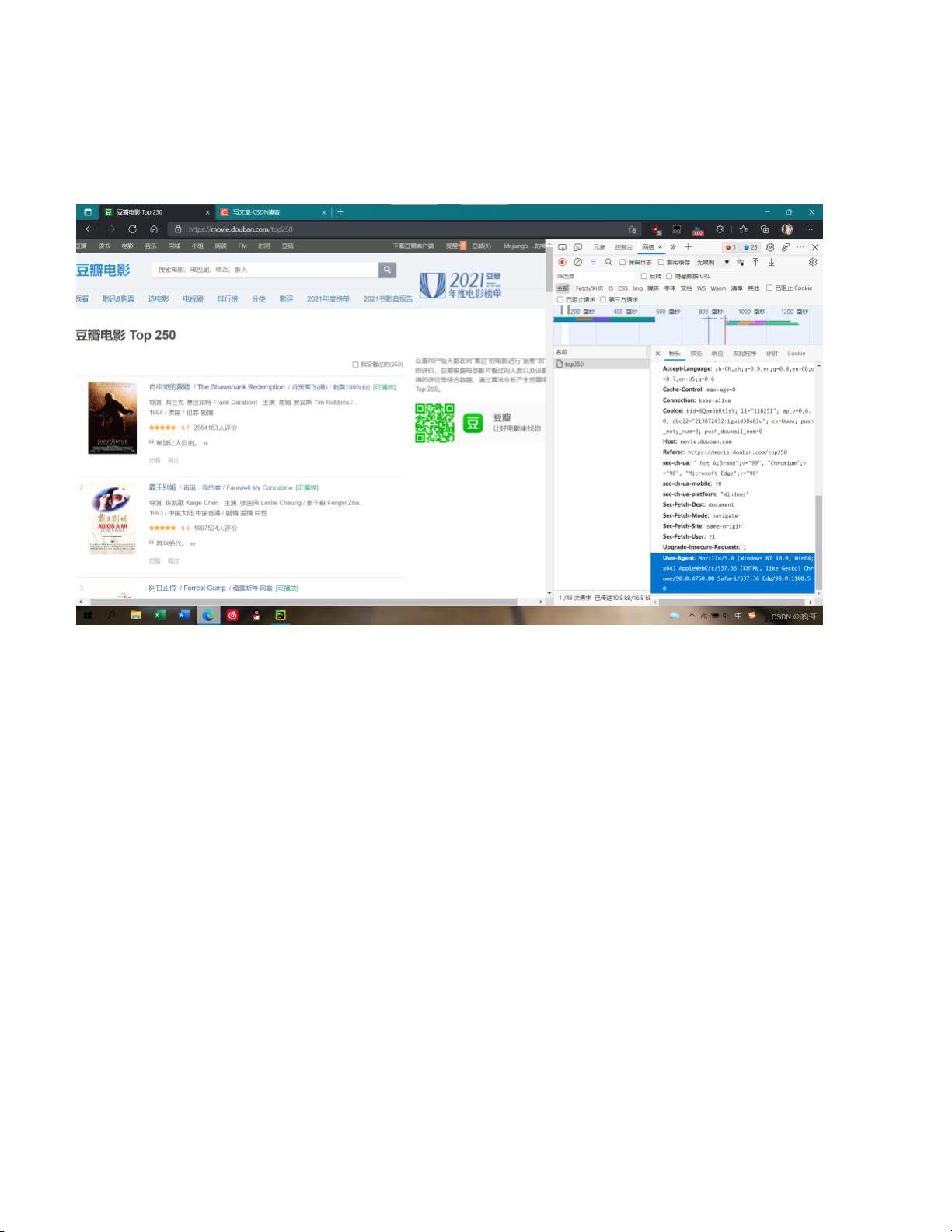
准备工作
找到自己的User-Agent,用于爬虫的伪装
查看自己的Python是否安装了所需库,没有安装的可以直接在该页面点+号搜索安装
下载后可阅读完整内容,剩余4页未读,立即下载
2023-08-17 上传
2023-03-08 上传
2023-07-15 上传
2023-05-29 上传
2023-06-01 上传
2023-07-17 上传
2023-04-18 上传

极智视界
- 粉丝: 3w+
- 资源: 1769
 我的内容管理
展开
我的内容管理
展开







