Spark源码解析:构建插件与源码结构详解
需积分: 12 154 浏览量
更新于2024-09-08
收藏 164KB DOCX 举报
"Spark源码解析,包括源码结构、主要包的功能说明及插件开发基础"
Spark是一个高性能、通用的分布式计算系统,其源码结构对于深入理解其工作原理和进行二次开发至关重要。源码提供了丰富的信息,帮助开发者了解Spark如何处理数据并优化计算任务。以下是关于Spark源码结构及其组件的详细说明:
1. **Spark源码结构**
Spark源码主要分为几个主要部分,包括核心库、SQL模块、MLlib机器学习库、Streaming模块、图形处理库GraphX以及与Hadoop的交互接口等。这些部分通常分布在不同的模块下,例如`core`, `sql`, `mllib`, `streaming`, `graphx`等。
2. **javaswing UI**
Spark的用户界面(UI)部分使用Java Swing构建,提供了一个图形化的方式监控Spark作业的执行状态。在源码中,这部分代码位于相关的UI包内,例如`org.apache.spark.ui`。
3. **插件开发**
Spark支持插件扩展,允许开发者添加自定义功能。在`Build`目录下,有一个`ExamplePlugin`类,展示了如何编写Spark插件。每个插件需要实现`Plugin`接口,包含`initialize()`, `shutdown()`, `canShutDown()`, 和 `uninstall()`等方法。此外,`ExamplePreference`类用于定义插件的属性,如名称、图标和提示信息。
4. **源码包结构**
- **org.jivesoftware**: 这个包主要包含了Spark的基础组件,特别是与Openfire集成的部分。Openfire是Spark使用的XMPP服务器,这部分代码负责与Openfire的交互,如用户认证、消息传递等。
- **org.apache.spark**: 这是Spark的核心包,包含了调度器、存储、执行器、 Shuffle管理等关键组件。例如,`org.apache.spark.scheduler`包下的类定义了作业调度策略,`org.apache.spark.storage`包涉及数据缓存和持久化。
- **org.apache.spark.sql**: SQL模块提供了对结构化数据的支持,包括DataFrame和DataSet操作,以及SQL查询引擎。这里包含`DataFrameReader`和`DataFrameWriter`等类,用于数据导入导出。
- **org.apache.spark.mllib**: MLlib是Spark的机器学习库,包含各种算法实现,如分类、回归、聚类等。
- **org.apache.spark.streaming**: Streaming模块处理实时数据流,定义了DStream(Discrete Stream)概念,以及DStream操作和转换。
- **org.apache.spark.graphx**: GraphX提供了图形处理功能,支持图的创建、查询和算法应用。
5. **其他组件**
Spark还包含了其他组件,如`repl`(交互式编程环境),`network`(网络通信),`utils`(通用工具类)等,它们共同构成了Spark的强大功能。
通过深入了解Spark源码结构,开发者不仅可以定制Spark的功能,还可以优化性能,解决特定场景下的问题,甚至贡献新的特性到开源社区。这需要对Java、Scala(Spark的主要编程语言)和分布式计算有深入理解。
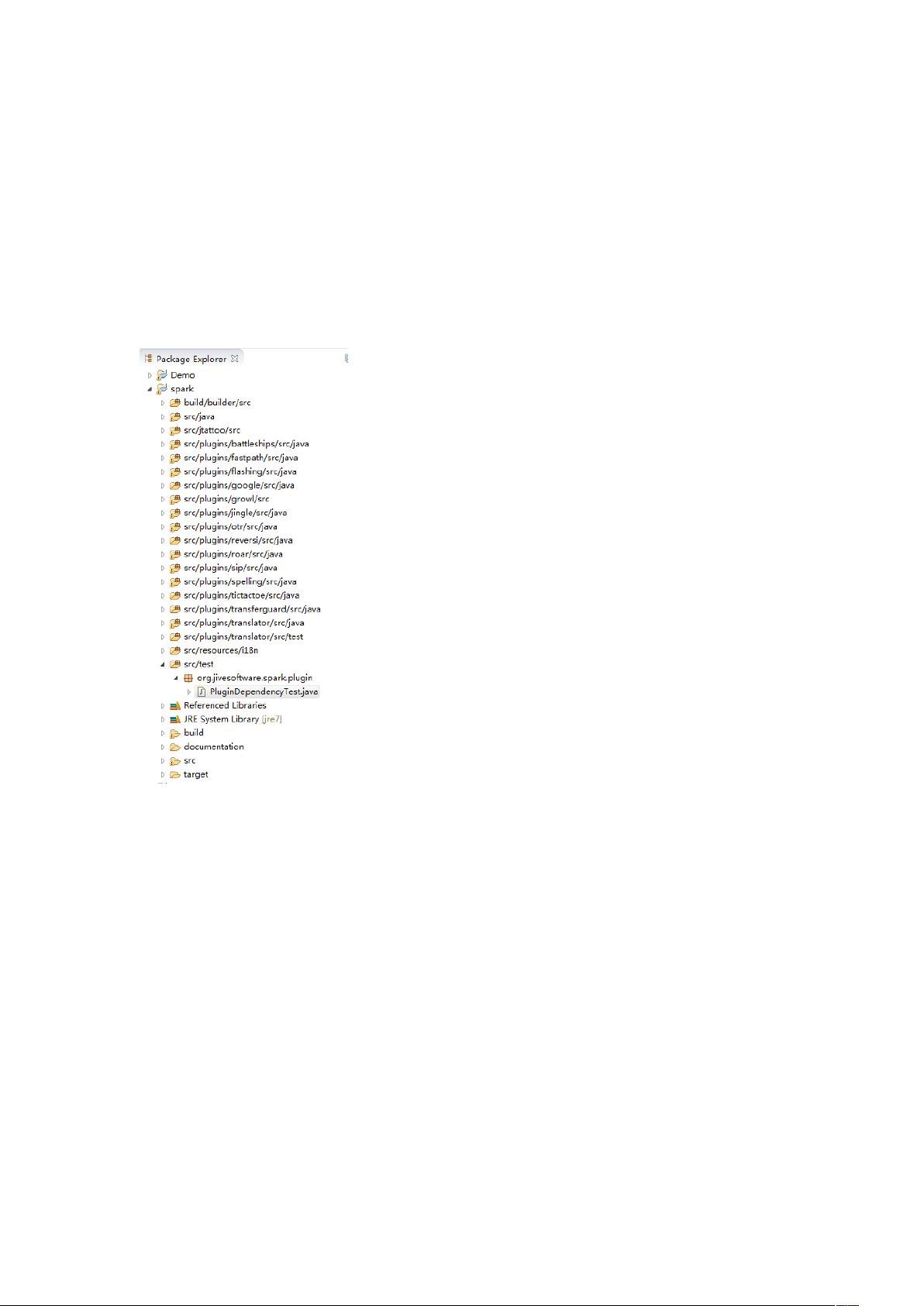
openfire-spark 二次开发-源码系统总览
一、spark
spark 的 UI 是使用 java swing 做
1、结构总图
源码环境配置好以后,eclispe 的项目树会是这样子的... ...
这是 Package 视图
可以切换到 Project 视图,那么是这样子的+
下载后可阅读完整内容,剩余5页未读,立即下载
2017-10-31 上传
2019-01-03 上传
2019-02-24 上传
2011-09-13 上传
2019-01-25 上传
2018-11-18 上传

蓝天1111
- 粉丝: 0
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- windows hive cmd 下载
- MongoUniversityProj:该存储库包含我的Mongo M101J认证分配解决方案
- cron_kernel_builder:用于构建内核的Cron脚本
- EHFS Raid Indexer-开源
- bigwork
- 机械工业常用材料数据库.zip
- SM2258H-B0KB-Q0125A
- c# 屏幕水印源码 显示电脑名,用户名,当前时间
- DependencyInjection:了解依赖注入
- ChessJavaFX
- hw1
- matlab归零码功率谱源码-physionet:卷积神经网络从单导联心电图检测心房颤动
- Easy Site Install-开源
- Secret:它将帮助您秘密地隐藏您的照片和视频
- F5-101考试准备:F5 101考试准备
- 幸福感-数据集
