NebulaGraph负载均衡与数据迁移:Balance与BALANCEDATA操作详解
23 浏览量
更新于2024-08-27
收藏 880KB PDF 举报
在图数据库NebulaGraph的设计实践中,负载均衡和数据迁移是关键环节,以确保系统的高效运行和数据的一致性。Balance命令在Nebula中主要关注Leader节点和partition的调整,其目标是使这些关键组件在集群中的分布更加均匀,但不涉及增加或减少Leader和partition的数量。当需要扩展存储容量时,比如新增机器,首先需启动对应的服务,存储系统会自动与meta元数据服务进行交互。
在这个过程中,Meta服务会根据新机器的加入计算出新的partition分配策略,通过执行BALANCEDATA命令来进行数据迁移。这通常是一个耗时的操作,因为涉及数据在多个存储节点间的复制和调整。BALANCEDATA命令主要负责数据和副本在机器之间的均衡分布,但它并不直接影响Leader的负载,因为Leader的角色和负载是固定的。
为了进一步平衡负载,可能需要使用BALANCELEADER命令,该命令同样是通过Meta服务来执行,目的是调整 Leader 节点的位置,确保在各空间(类似于MySQL中的数据库)内的负载均衡。在进行大规模数据迁移时,例如从3个副本扩展到8个副本,需要先准备阶段,包括部署满足需求的存储实例、Metad和至少一个图形服务,然后通过SHOWHOSTS命令检查集群状态,确认所有实例的在线情况以及空间、分区的分布。
示例步骤包括:
1. 准备工作:部署3副本的存储服务,一个图形服务和一个Metad服务。此时,存储实例处于未装载状态,没有数据。
2. 检查现有状态:使用SHOWHOSTS命令查看集群的节点状态、领导者分布、分区分布等信息,确认它们为空。
3. 创建图空间:在准备好基础设施后,可以开始创建图空间,为后续的数据迁移做准备。
通过这些步骤,可以逐步实现图数据库NebulaGraph的负载均衡和数据迁移,确保在集群扩展时,数据能够无缝地在新添加的机器上分布,同时保持系统的稳定性和性能。在操作过程中,理解并正确运用Balance和Balancer相关的命令至关重要,以避免不必要的数据中断和性能下降。
图数据库设计实践图数据库设计实践|存储服务的负载均衡和数据迁移存储服务的负载均衡和数据迁移
平衡主体浅析
在图数据库Nebula Graph中,Balance主要用于balance Leader和partition,只涉及Leader和partition在机器之间转移,不会增
加或减少Leader and partition的数量。
上线新机器并启动相应的Nebula服务后,存储会自动向metametameta。Meta会计算出一个新的partition分布,然后通过删除
partition 和add partition将数据从老机器搬迁到新的机器上。这个过程所对应的命令是BALANCE DATA ,通常数据搬迁是个
比较漫长的过程。
但BALANCE DATA仅改变了数据和副本在机器之间的均衡分布,leader(和对应的负载)是不会改变的,因此还需要通过命
令BALANCE LEADER来实现负载的均衡。这个过程也是通过meta实现的。
大规模数据迁移
举例以下说明BALANCE DATA的使用方式本。译文将从3个实例(进程)扩展到8个实例(进程):
步骤1:准备工作
部署一个3副本的副本,1个图形,1个metad,3个存储(具体部署方式请参考部署部署文:https
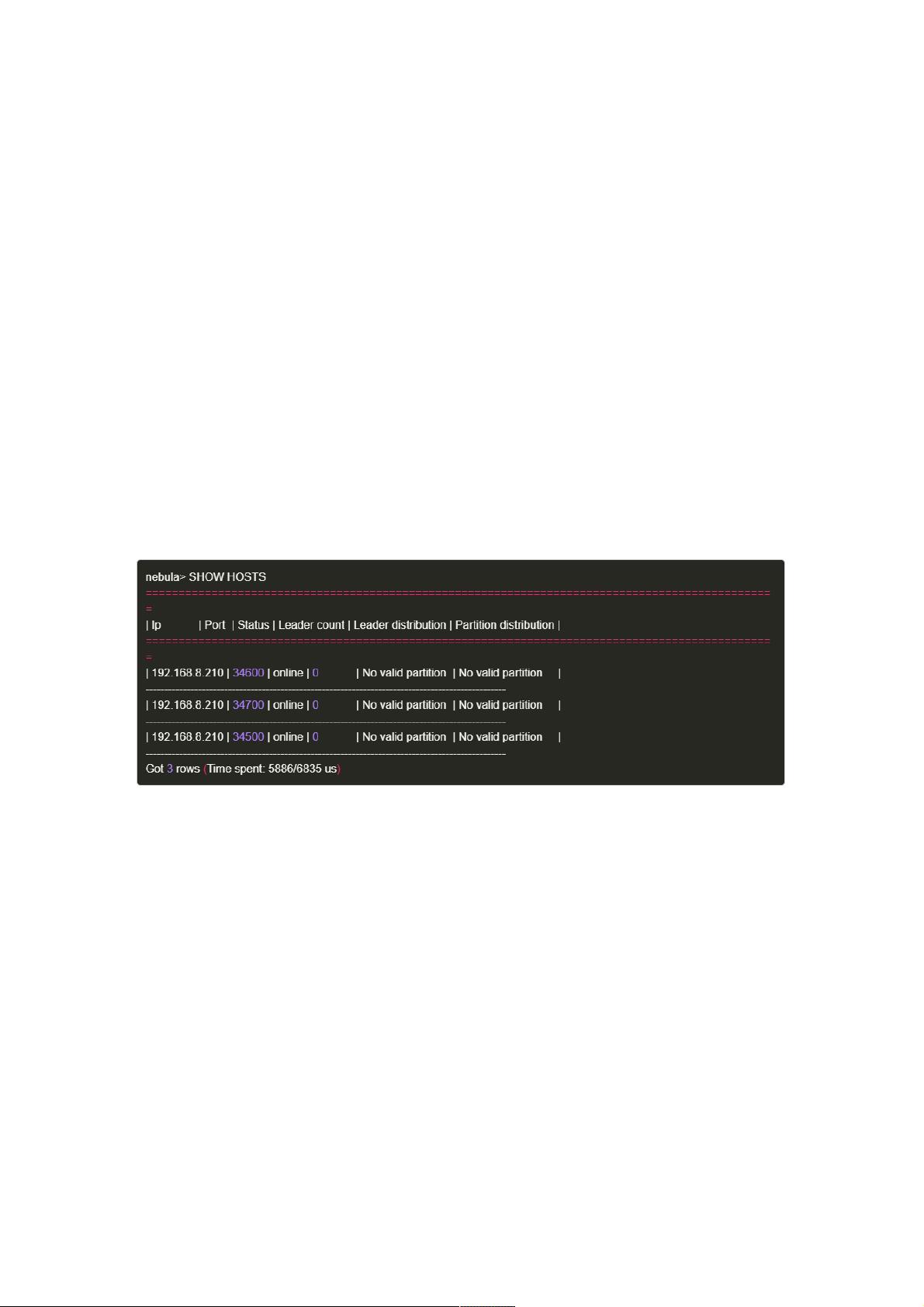
://zhuanlan.zhihu.com/p/80335605 ),通过SHOW HOSTS 命令可以看到重新的状态信息:
步骤1.1查看现有状态
按照部署部署文档部署好3副本合并之后,用SHOW HOSTS 命令查看下现在可用情况:
SHOW HOSTS 返回结果解释:
IP,端口表示当前的存储实例。这个最大化启动了3个storaged服务,并且还没有任何数据。
(192.168.8.210:34600,192.168.8.210:34700,192.168.8.210:34500)
状态表示当前实例的状态,目前有在线/离线两种。当机器下线以后(metad在一段间隔内收不到其心跳),将其更改为离线。
这个时间间隔可以在启动metad的时候通过设置expired_threshold_sec来修改,当前默认值是10分钟。
领导人数:表示当前实例
领导者分布:表示当前领导者在每个空间上的分布,目前尚未创建任何空间。(space可以理解为一个独立的数据空间,类似
MySQL的数据库)
分区分布:不同空间中分区的数量。
下载后可阅读完整内容,剩余6页未读,立即下载
2011-12-21 上传
点击了解资源详情
2022-07-13 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38724154
- 粉丝: 8
- 资源: 895
 我的内容管理
展开
我的内容管理
展开







