优化HDFS小文件存储:Facebook Haystack与淘宝TFS实践
需积分: 50 187 浏览量
更新于2024-07-20
收藏 1.15MB DOCX 举报
HDFS小文件处理方案是针对Hadoop分布式文件系统(Hadoop Distributed File System, HDFS)在面对大量小文件存储和操作时遇到的问题进行的一种优化策略。HDFS最初设计是为了高效地存储和处理大规模的数据,其核心特性如流式读写、基于datanode的数据分片等并不适用于小文件场景。
小文件的特点,比如手机图片和电商网站的产品图片,由于用户频繁上传、下载和读取,数量庞大但文件大小通常在几KB到几十KB之间。这与HDFS的设计初衷——处理几百MB乃至TB级的大文件存在冲突。首先,HDFS的元数据存储在namenode的内存中,导致存储小文件数量受内存限制,百万级别的文件可能导致内存耗尽。其次,HDFS的流式读写和datanode间的跳跃读取降低了对小文件并发访问的效率。
HDFS的文件操作流程包括reading(读取)和writing(写入),这些操作在处理大量小文件时可能会变得低效。然而,HDFS也内置了一些小文件存储解决方案来应对这一挑战:
1. **HadoopArchive (bar.har)**:这是一种将多个小文件打包成一个大文件的方法,解决了文件分散存储的问题。然而,它存在以下缺点:
- 不自动删除源文件和目录,需要手动管理。
- 存档过程依赖MapReduce,对Hadoop环境要求较高。
- 不支持原生压缩,可能增加存储需求。
- 创建后不可修改,增删文件需重新创建存档。
- 生成存档文件会复制原始文件,占用额外磁盘空间。
2. **SequenceFile**:这是一种键值对格式的文件,适合存储结构化数据。它可以合并多个小文件,提高I/O效率,但同样需要Hadoop的支持。
3. **CombineFileInputFormat**:这是一种输入格式,能够合并多个小文件作为单个输入源,减少了网络I/O次数,提高了读取速度。这对于处理大量小文件的分析任务特别有用。
总结来说,HDFS小文件处理方案通过HadoopArchive等方式尝试合并或归档小文件,以克服其在存储和访问小文件方面的局限性。然而,这些方法并非万能,用户可能需要根据具体的应用场景和需求权衡利弊,或者考虑其他非HDFS的存储技术,如Amazon S3或Google Cloud Storage,它们在小文件存储方面有更好的优化。
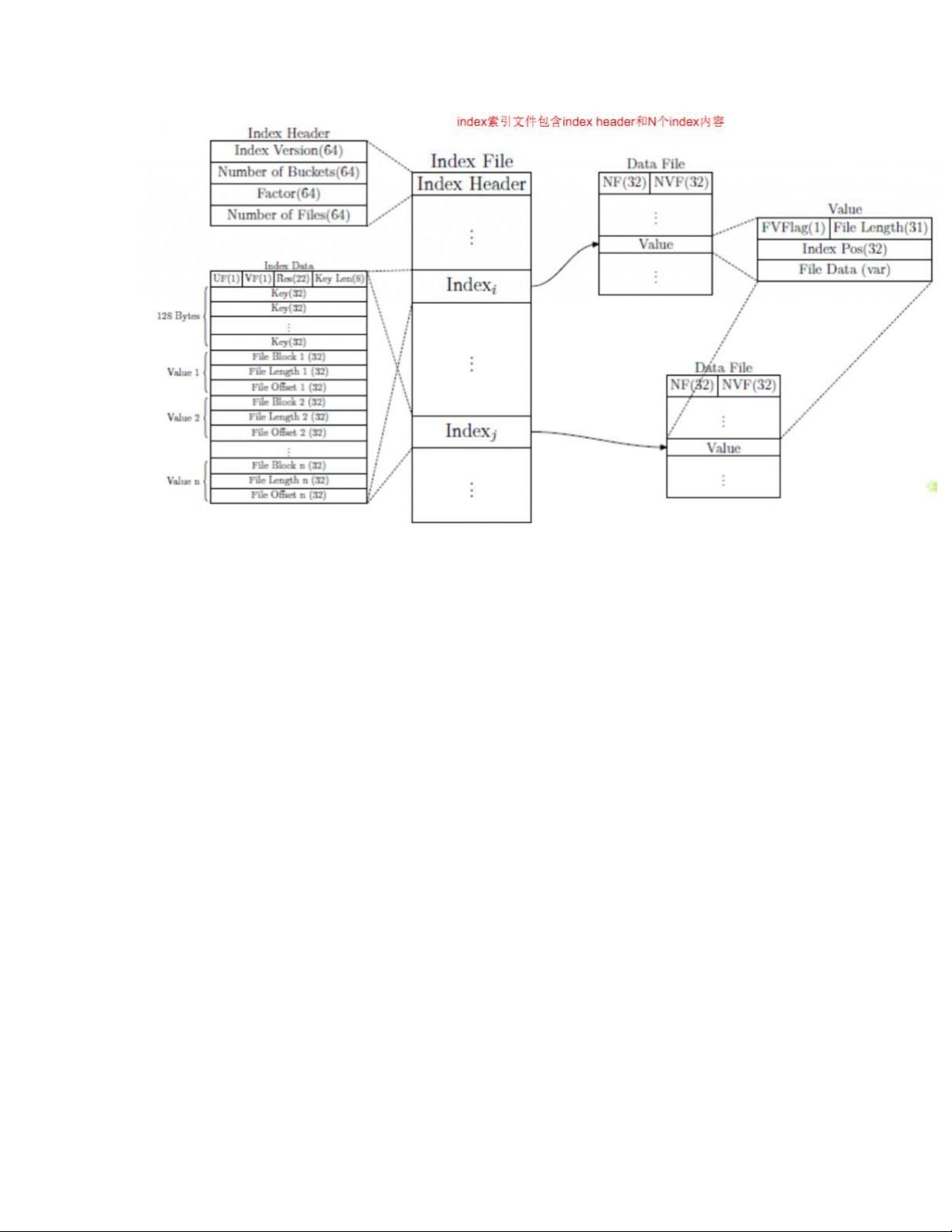
从以上索引结构和文件存储方式可以看出,index 是一般的定长 hash 索引,并且采用的是存储全局
index 文件的方式
read 的过程是将小文件 append 到下文件后边,然后更新索引的过程
delete 文件的过程采用 lazy 模式,更改的是 FVFlag,在空间重新分配的过程中,才会根据该 flag 删
除文件。
五、BlueSky 解决方案概述
BlueSky 是中国电子教学共享系统,主要存放的教学所用的 ppt 文件和视频文件,存放的载体为 HD
FS 分布式存储系统。在用户上传 PPT 文件的N同时,系统还会存储一些文件的快照,作为用户请求
ppt 时可以先看到这些快照,以决定是否继续浏览,用户对文件的请求具有很强的关联性,当用户
浏览 pptN时,其他相关的 ppt 和文件也会在短时间内被访问,因而文件的访问具有相关性和本地性。
paper 主要提出了两个基本观点:
(1)NNNNNN将属于同一课件的小文件合并成一个大文件,从而减轻 namenode 的压力,提高小文件
的存储效率
(2)NNNNNN提出了一种两级预取机制以提高小文件的读取效率,(索引文件预取和数据文件预取)
索引文件预取是指当用户访问某个文件时,该文件所在的 block 对应的索引文件被加载到内存中,
剩余27页未读,继续阅读
308 浏览量
186 浏览量
120 浏览量
58051 浏览量
279 浏览量
315 浏览量
点击了解资源详情
298 浏览量

灿明00
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 远程过程调用协议规范 RFC1050
- 7天搞定C#.pdf
- 电信基础知识和智能网原理
- 关于马尔可夫随机场的一篇较好的综述
- 三层架构 数据访问层
- TDMSExcelAddin.pdf
- Asterisk,电话未来之路CHN2
- Google搜索引擎排名因素打分详解 排名 seo排名
- FME2008中文教程
- Using OpenGL in Visual C++
- MySQL_Optimize_CU_bj.pdf
- 谭浩强 C程序设计(第二版)
- oracle 1000问
- Struts初级入门
- The Object-Oriented Thought Process (3rd Edition)
- A Semantic Web Primer 2nd Edition
