机器学习与概率统计:神经网络基础
需积分: 5 3 浏览量
更新于2024-07-18
收藏 6.23MB PDF 举报
"神经网络之数理统计与参数估计,机器学习相关知识分享"
这篇资料主要探讨了神经网络和机器学习中的数理统计基础,旨在帮助学习者更好地理解和应用统计方法于机器学习项目中。作者龙老师是一名有多年互联网经验的专业人士,专注于机器学习和数据挖掘,并在某公司负责相关项目。
1. 明确目的
学习的重点是将概率统计知识应用于机器学习,而非深入研究概率统计本身。关键在于理解概率与统计如何与机器学习相互作用,以解决实际问题。机器学习关注的是如何通过特征和标签的模式来预测未知数据,包括监督学习、无监督学习和半监督学习。
1.1 机器学习的关注点
机器学习的核心是利用特征和已知的标签来构建模型,以便对未知标签的数据进行预测。监督学习是利用带标签的数据进行训练,然后进行预测;无监督学习则是在没有标签的情况下寻找数据的内在结构;半监督学习介于两者之间,利用少量的标签信息来提升模型的性能。
1.2 概率与统计的关注点
概率论通常从确定性出发,研究随机事件的概率性质,而统计学则是从观察数据出发,推断总体的特性。统计学可以看作是概率的逆向工程,从样本数据中推断总体参数。
1.3 概率统计与机器学习的关系
在机器学习中,概率统计起着至关重要的作用。例如,期望、方差、协方差和相关系数是评估数据分布和变量间关系的重要统计量;Jensen不等式用于凸函数的性质;契比雪夫不等式和大数定律提供了关于随机变量集中趋势的理论依据;中心极限定理解释了为什么在大样本情况下,样本均值的分布接近正态分布。这些工具在估计参数时非常有用,如矩估计和极大似然估计,它们分别通过样本矩和最大化数据似然性来估算总体参数。
这份资源强调了概率统计在机器学习中的核心地位,特别是对于理解模型的训练和预测过程,以及如何从数据中有效地提取信息。通过掌握这些基础知识,学习者能够更深入地理解神经网络和其他机器学习算法的内部工作原理,从而提高模型的准确性和泛化能力。
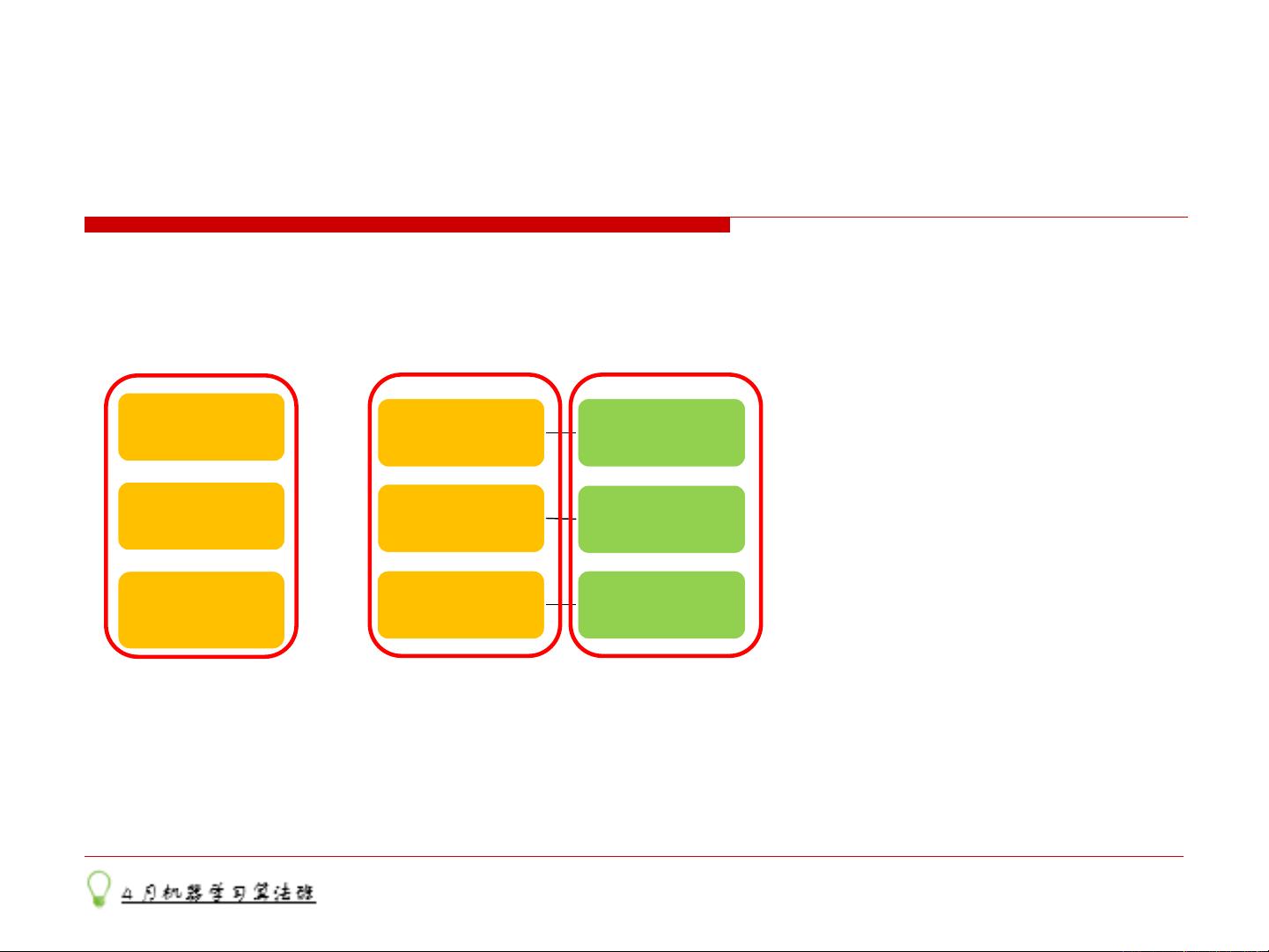
1.3概率统计与机器学习的关系
•julyedu.com
寒老师用心良苦
特征n 标签
特征n
标签
特征n 标签
特征1
特征1
特征1
……
……
……
分布X1
分布Xn
分布Y
可基于各个分布的特性来评估模型和样本
剩余60页未读,继续阅读
2018-04-06 上传
2013-08-30 上传
2024-04-08 上传
2023-10-25 上传
2023-02-06 上传
2023-10-24 上传
2023-04-03 上传
2023-10-31 上传

qq_66336876
- 粉丝: 0
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular程序高效加载与展示海量Excel数据技巧
- Argos客户端开发流程及Vue配置指南
- 基于源码的PHP Webshell审查工具介绍
- Mina任务部署Rpush教程与实践指南
- 密歇根大学主题新标签页壁纸与多功能扩展
- Golang编程入门:基础代码学习教程
- Aplysia吸引子分析MATLAB代码套件解读
- 程序性竞争问题解决实践指南
- lyra: Rust语言实现的特征提取POC功能
- Chrome扩展:NBA全明星新标签壁纸
- 探索通用Lisp用户空间文件系统clufs_0.7
- dheap: Haxe实现的高效D-ary堆算法
- 利用BladeRF实现简易VNA频率响应分析工具
- 深度解析Amazon SQS在C#中的应用实践
- 正义联盟计划管理系统:udemy-heroes-demo-09
- JavaScript语法jsonpointer替代实现介绍
