Python乳腺癌数据集:逻辑回归与KNN模型对比分析
本资源主要介绍如何使用Python的scikit-learn库处理乳腺癌数据集,并通过实例展示如何进行数据分析、模型构建和性能评估。首先,我们从`sklearn.datasets`模块导入`load_breast_cancer`函数来加载预定义的乳腺癌数据集。
步骤一:数据划分与预处理
将数据集划分为训练集和测试集,通常采用70%的数据用于训练,30%用于测试。使用逻辑回归和K-近邻(KNN)算法进行建模前,对数据进行标准化操作,以便提高模型的稳定性和性能。
步骤二:模型训练与性能评估
对于逻辑回归模型,不指定参数直接建模,然后计算测试集的混淆矩阵,包括准确率(Accuracy)、查全率(Sensitivity或Recall)和假正率(False Positive Rate)。对于KNN算法,探索性地调整主要参数,如n_neighbors(最近邻数量)、algorithm(计算方法)、p(距离度量)、以及weights(权重类型),以找到最优参数。
步骤三:参数优化
通过网格搜索技术确定逻辑回归和KNN模型的最佳参数,这有助于提高模型的预测性能。在优化过程中,需关注算法的速度与模型性能之间的平衡。
步骤四:交叉验证
使用K折交叉验证(k=2到10)对整个数据集进行模型训练,分别用逻辑回归和KNN模型,并使用优化后的参数。通过比较不同k值下分类准确率的变化,可以评估模型的稳健性。
代码示例部分展示了如何导入必要的库,加载数据,执行预处理,以及执行上述分析流程。最后,通过可视化工具(如matplotlib)展示分类准确率随k值变化的趋势,帮助我们直观地了解两种算法在不同k值下的表现。
总结来说,这个资源提供了一个实际操作案例,展示了如何在Python中使用scikit-learn处理乳腺癌数据集,包括数据预处理、模型选择、参数调优和评估性能的方法,这对于理解和实践机器学习算法具有很高的参考价值。
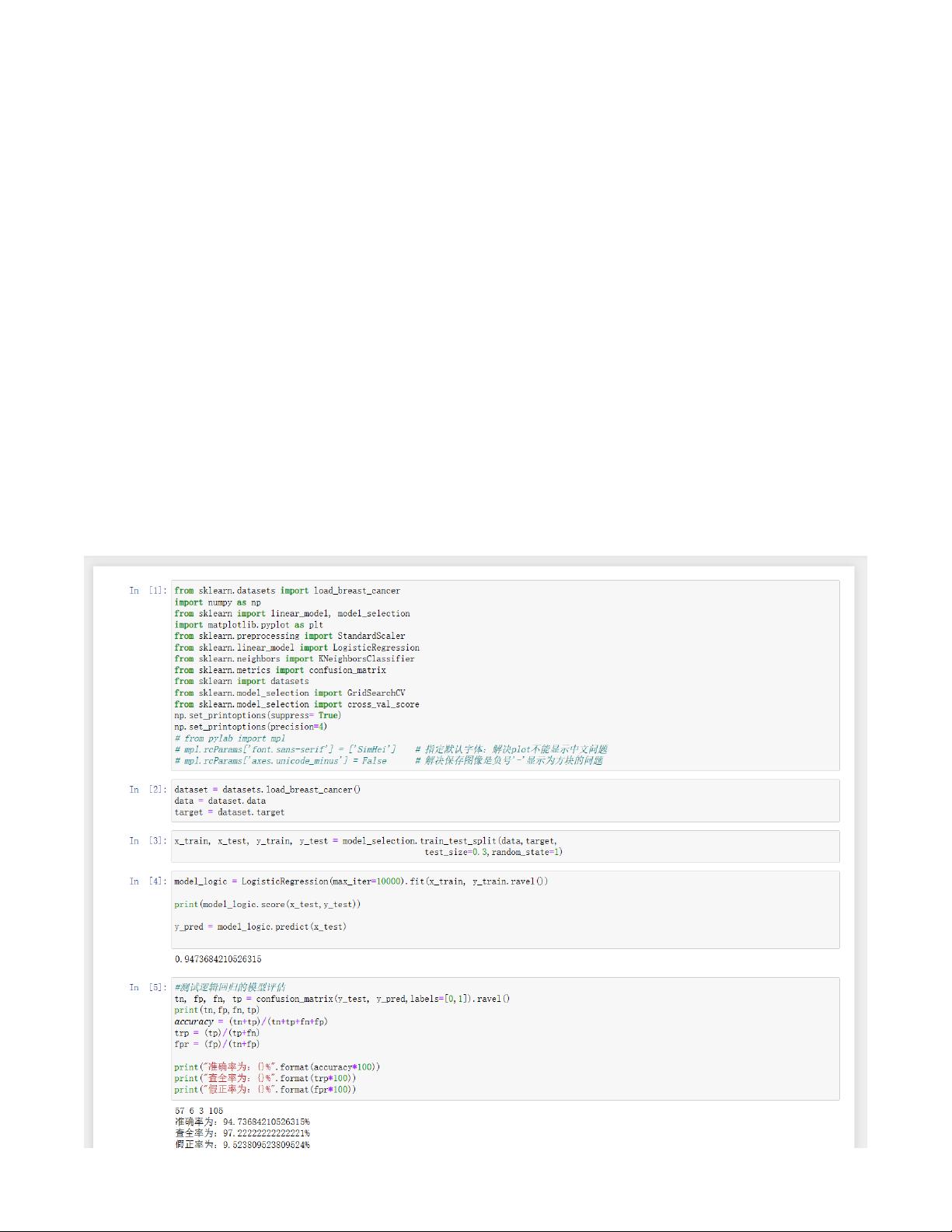
数据集:乳腺癌数据集(from sklearn.datasets import load_breast_cancer)。
(1)将样本集划分为70%的训练集,30%作为测试集,分别用逻辑回归算法和KNN算法(需要先对数据进行标准化)
建模(不指定参数),输出其测试结果的混淆矩阵,计算其准确率、查全率和假正率。
(2)利用搜索网格,分别确定逻辑回归及KNN模型的最优参数。
KNN算法的主要参数提示:
①n_neighbors(最近邻个数)
取值一般为奇数。
②algorithm(用于计算最近邻的算法)
取值有‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’等,默认为‘auto’。注意:算法选择不影响KNN的最终结果,只影响模型的性能
(计算的快慢程度)。
③p(Minkowski距离的指标参数)
默认取p=2,即欧氏距离。而p=1为曼哈顿距离。如果需要使用非明氏距离的其它指标,应修改metric参数的值。
④weights(权重)
预测中使用的权重函数。可能的取值:‘uniform’:统一权重,即每个邻域中的所有点均被加权。 ‘distance’:权重点与其
距离的倒数,在这种情况下,查询点的近邻比远处的近邻具有更大的影响力。
(3)对整个数据集使用K折交叉验证方式(k=2,3,4,5,6,7,8,9,10),分别用逻辑回归和KNN建模(用上一步确定的最优
参数),绘图对比两种模型在k取不同值下的的分类准确率。
下载后可阅读完整内容,剩余5页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-05-22 上传
2023-04-20 上传
2023-03-22 上传
2024-09-27 上传
2023-05-18 上传
2023-06-01 上传
2023-06-01 上传

快乐无限出发
- 粉丝: 1211
- 资源: 7395
 我的内容管理
展开
我的内容管理
展开







最新资源
- 网站绐终显示app_offline.htm的解决方法
- SQL2005常见错误排除
- wince教程wince教程
- SQL2005的数据类型详解
- Asp.net常用函数集锦
- linux下shell编程
- Windows应用程序捆绑核心编程
- Oracle 10g 的闪回恢复区 (PDF)
- 如何解决Oracle 常见错误 ORA-04031(PDF)
- 基于ASP_NET的在线考试系统的设计与实现.pdf
- 基于ASP_NET的网上购物系统的设计与实现.pdf
- 《Google搜索引擎优化指南》中英文电子版.pdf
- 学生成绩管理系统论文
- C C++常用算法实例.doc
- 很有实用价值的神奇代码 只要你在IE浏览器任意打开一个网站 就可以……
- linux+内核完全注释+修正版本v3.0.pdf(即linux内核完全刨析基于0.12内核)
