手把手教你安装Hadoop:从环境配置到集群搭建
需积分: 3 78 浏览量
更新于2024-09-13
收藏 293KB DOCX 举报
"这是关于在虚拟环境下安装Hadoop的详细步骤,包括硬件和软件配置,以及安装过程中的关键操作,如设置SSH互信和部署Hadoop文件。"
在安装Hadoop之前,首先要准备合适的硬件和软件环境。在这个例子中,硬件环境是一台配备I3处理器、8GB内存和500GB硬盘的笔记本。而软件环境是使用VirtualBox虚拟机,创建了三个Linux实例,每个虚拟机分配了1.5GB内存和20GB硬盘空间。网络配置方面,主节点(Master)配置了两块网卡,一块用于与物理主机通信,另一块用于集群内部通信;而其他两个节点(Node1和Node2)则各有一块网卡。
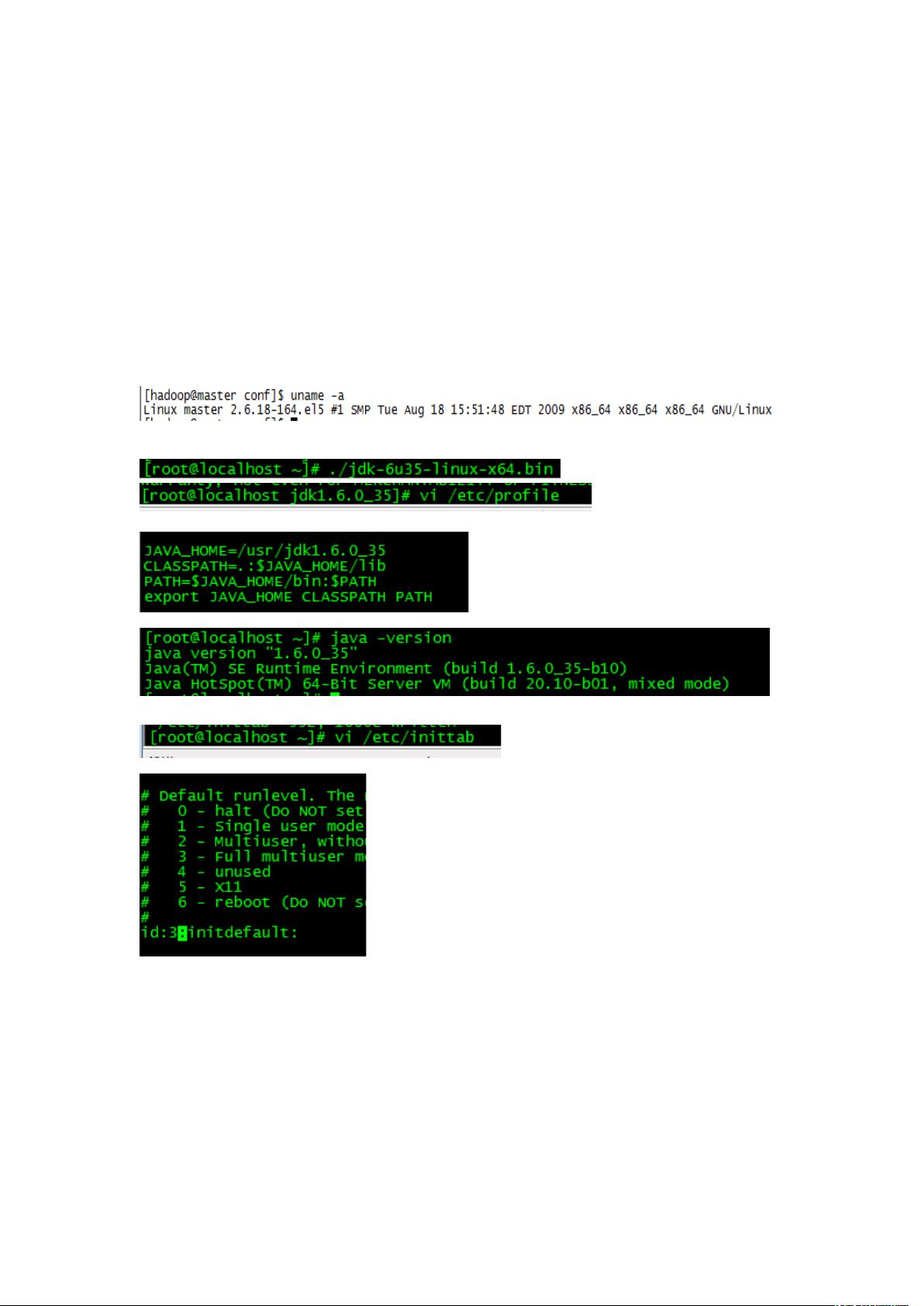
接下来是安装操作系统的步骤,这里选择了Red Hat Linux 5.4 x86_64。在操作系统安装完成后,需要安装JDK 1.6,并将启动模式改为文本模式以节省资源。接着,创建名为"hadoop"的新用户并设置密码。
为了构建Hadoop集群,需要在所有节点之间建立SSH无密码登录。首先,使用`ssh-keygen -t rsa`命令在每个节点上生成公钥文件,然后将公钥文件(id_rsa.pub)的内容复制到`authorized_keys`文件中。这可以通过`scp`命令将`authorized_keys`文件分发到其他节点,确保所有节点都信任彼此。最后,通过SSH尝试连接各个节点,确认无密码登录已经成功。
之后,通过网络工具将Hadoop的安装包上传到任意一个节点,例如Master。将其移动到`/home/hadoop`目录,并使用`chown`命令更改文件的所有者和组为"hadoop"。然后,切换到"hadoop"用户身份,使用`tar`命令解压缩Hadoop的安装包。
至此,Hadoop的准备工作基本完成。但为了使Hadoop能正常运行,还需要对配置文件进行适当的修改,包括设置Hadoop的环境变量,配置HDFS(分布式文件系统)和MapReduce的相关参数,以及集群的拓扑信息。这些配置通常位于`$HADOOP_HOME/conf`目录下的`core-site.xml`、`hdfs-site.xml`和`mapred-site.xml`文件中。
最后,启动Hadoop服务,包括DataNode、NameNode、TaskTracker和JobTracker。启动后,可以使用Hadoop自带的工具进行健康检查,比如`hadoop dfsadmin -report`和`jps`,以确保所有服务都在正常运行。至此,一个基本的Hadoop集群已经搭建完毕,可以开始进行数据处理和分析任务。
硬件环境为笔记本一台
配置为 I3 8G 内存 500G 硬盘
软件环境为 vmbox 虚拟机,在虚拟机上虚拟出三台 Linux(虚拟机配置每台服务器使用内存
为 1.5G、硬盘容量为 20G 、master 配置 2 块网卡 1 块作为实体机与虚拟机访问另外一块作
为 3 个节点内部访问网络、其余两台机器只有一块网卡)
Master 10.10.10.2 255.255.255.0 192.168.1.100 255.255.255.0
Node1 10.10.10.3 255.255.255.0
Node2 10.10.10.4 255.255.255.0
以下是安装步骤
1、 在虚拟机上安装 linux,我使用的是 redhat linux 5.4 x86_64
2、安装好操作系统后,在系统上安装 JDK1.6;
3、 修改启动模式为文本模式以降低资源;
4、 为机器添加帐号并设置密码;
Useradd hadoop
Passwd hadoop
下载后可阅读完整内容,剩余7页未读,立即下载
2013-07-08 上传
2018-12-26 上传
2019-10-14 上传
2019-08-03 上传
2014-04-16 上传
2020-04-22 上传
2019-03-13 上传

wspsky
- 粉丝: 8
- 资源: 15
 我的内容管理
展开
我的内容管理
展开







最新资源
- NIST REFPROP问题反馈与解决方案存储库
- 掌握LeetCode习题的系统开源答案
- ctop:实现汉字按首字母拼音分类排序的PHP工具
- 微信小程序课程学习——投资融资类产品说明
- Matlab犯罪模拟器开发:探索《当蛮力失败》犯罪惩罚模型
- Java网上招聘系统实战项目源码及部署教程
- OneSky APIPHP5库:PHP5.1及以上版本的API集成
- 实时监控MySQL导入进度的bash脚本技巧
- 使用MATLAB开发交流电压脉冲生成控制系统
- ESP32安全OTA更新:原生API与WebSocket加密传输
- Sonic-Sharp: 基于《刺猬索尼克》的开源C#游戏引擎
- Java文章发布系统源码及部署教程
- CQUPT Python课程代码资源完整分享
- 易语言实现获取目录尺寸的Scripting.FileSystemObject对象方法
- Excel宾果卡生成器:自定义和打印多张卡片
- 使用HALCON实现图像二维码自动读取与解码
