尚硅谷大数据教程:HDFS HA高可用解析
 已收录资源合集
已收录资源合集
需积分: 0 134 浏览量
更新于2024-08-05
收藏 469KB PDF 举报
"尚硅谷大数据技术教程,讲解了HDFS高可用(HA)的概念、工作机制以及环境准备和集群规划。"
在Hadoop生态系统中,高可用性(High Availability, HA)是一个至关重要的特性,确保服务能够持续运行,避免单点故障(Single Point of Failure, SPOF)对业务造成影响。在Hadoop 2.0之前,NameNode作为HDFS的核心组件,一旦出现故障,整个集群的服务就会中断,这限制了系统的可用性和可靠性。为了解决这个问题,Hadoop引入了HDFS HA,通过配置Active/Standby两个NameNodes来实现NameNode的热备份。
**8.1 HA概述**
1. HA的目标是提供7*24小时不间断的服务,确保业务连续性。
2. 高可用性策略的关键是消除可能成为系统瓶颈的单点故障。
3. 在HDFS中,HA主要关注NameNode的HA,因为NameNode负责管理文件系统的元数据,它的故障会导致整个HDFS集群不可用。
4. HDFSHA功能通过Active和Standby NameNode的组合,使得在NameNode出现故障或需要维护时,能够快速切换到备用节点,从而避免服务中断。
**8.2 HDFS-HA工作机制**
1. **双NameNode模式**:配置两个NameNode,一个处于Active状态,处理客户端请求;另一个处于Standby状态,同步Active NameNode的元数据,时刻准备接管服务。
2. **元数据管理**:两个NameNode在内存中分别保存元数据副本,Active NameNode写入Edits日志,而两个NameNode都能读取Edits。共享的Edits日志通常存储在Quorum Journal Manager (QJM)或Network File System (NFS)中。
3. **状态管理**:ZKFailoverController(ZKFC)作为监控模块,每个NameNode节点上都有一个,利用ZooKeeper进行状态同步和切换控制,防止大脑分裂(Brainsplit)情况,即两个NameNode同时认为自己是Active状态。
4. **隔离机制**:为了确保任何时候只有一个NameNode提供服务,系统需要实现一种隔离策略,如SSH无密码登录,便于状态切换时的通信。
**8.2.2 HDFS-HA自动故障转移工作机制**
1. 当Active NameNode出现问题时,ZKFC检测到这一状态变化,通过ZooKeeper协调,触发故障转移。
2. Standby NameNode接收到转换指令后,会尝试获取锁并开始服务,同时,旧的Active NameNode会被隔离,防止其继续服务。
3. 故障转移过程中,ZKFC确保数据一致性,防止在切换期间的数据丢失或冲突。
**8.3 环境准备与集群规划**
1. **环境准备**:部署前需要准备好支持HA的硬件环境,包括多台NameNode服务器,以及ZooKeeper集群,确保网络连通性和安全性。
2. **规划集群**:考虑HDFS的扩展性、容错性以及性能需求,合理规划NameNode、DataNode、ZooKeeper节点的数量和分布,以及共享存储的配置。
实施HDFS HA不仅涉及到技术层面的配置,还需要综合考虑业务需求、运维流程和监控体系,以确保在提高可用性的同时,也能保证数据的安全性和一致性。在实际生产环境中,理解并掌握这些机制对于确保Hadoop集群的稳定运行至关重要。
尚硅谷大数据技术之 Hadoop(HFDS 文件系统)
—————————————————————————————
更多 Java –大数据 –前端 –python 人工智能资料下载,可百度访问:尚硅谷官网
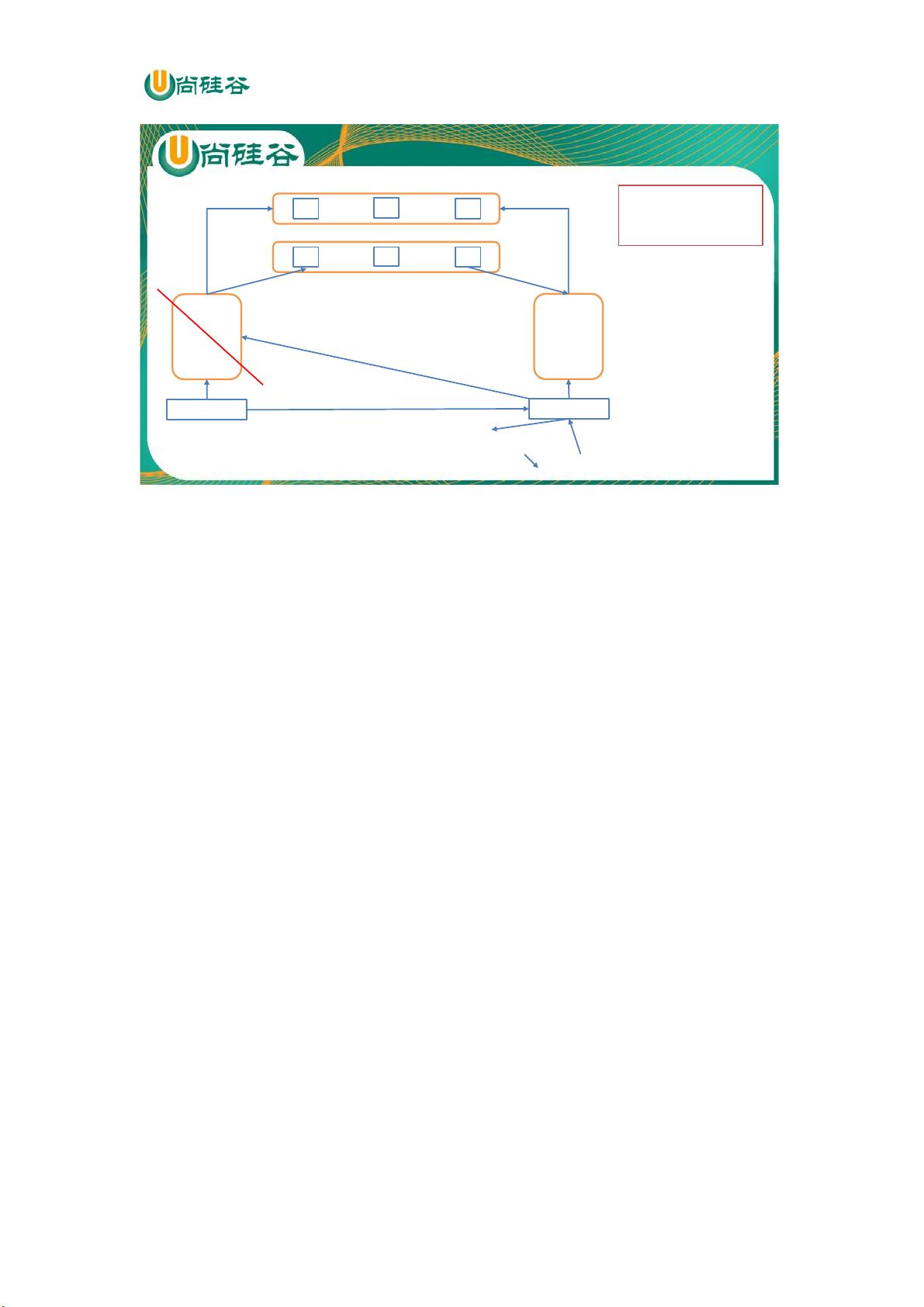
HDFS-HA故障转移机制
Name node
Name node
active
standby
内存中的元数据
内存中的元数据
fsimage fsimage
edits edits
edits
edits edits
zk1
zk2
zk3
Zkfc
Failover controller
Zkfc
Failover controller
Zookeeper服务端
Edits文件管理系统:qjournal
5 如果ssh补
刀失败则调用
用户自定义脚
本程序
6 获取命令运
行结果
/home/atguigu/kill/
poweroff.sh
1 假死
2 检测到假死
3 通知另一台NameNode的zkfc
4 强行杀死namenode,防止脑裂
ssh kill -9 namenode进程号
7 激活本台namenode,切换为Active
同时出现两个Active状态
namenode的术语叫脑裂brain split。
防止脑裂的两种方式:
1)ssh发送kill指令
2)调用用户自定义脚本程序
Zookeeper客户端
Zookeeper客户端
写
读
8.3 HDFS-HA
集群配置
8.3.1
环境准备
1)修改 IP
2)修改主机名及主机名和 IP 地址的映射
3)关闭防火墙
4)ssh 免密登录
5)安装 JDK,配置环境变量等
8.3.2
规划集群
hadoop102 hadoop103 hadoop104
NameNode NameNode
JournalNode JournalNode JournalNode
DataNode DataNode DataNode
ZK ZK ZK
ResourceManager
NodeManager NodeManager NodeManager
8.3.3
配置
Zookeeper
集群
0)集群规划
在 hadoop102、hadoop103 和 hadoop104 三个节点上部署 Zookeeper。
剩余13页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-08-03 上传
2022-08-04 上传
2022-08-03 上传
2022-08-03 上传
2022-08-03 上传
2022-08-08 上传

设计师马丁
- 粉丝: 21
- 资源: 299
 我的内容管理
展开
我的内容管理
展开







最新资源
- Raspberry Pi OpenCL驱动程序安装与QEMU仿真指南
- Apache RocketMQ Go客户端:全面支持与消息处理功能
- WStage平台:无线传感器网络阶段数据交互技术
- 基于Java SpringBoot和微信小程序的ssm智能仓储系统开发
- CorrectMe项目:自动更正与建议API的开发与应用
- IdeaBiz请求处理程序JAVA:自动化API调用与令牌管理
- 墨西哥面包店研讨会:介绍关键业绩指标(KPI)与评估标准
- 2014年Android音乐播放器源码学习分享
- CleverRecyclerView扩展库:滑动效果与特性增强
- 利用Python和SURF特征识别斑点猫图像
- Wurpr开源PHP MySQL包装器:安全易用且高效
- Scratch少儿编程:Kanon妹系闹钟音效素材包
- 食品分享社交应用的开发教程与功能介绍
- Cookies by lfj.io: 浏览数据智能管理与同步工具
- 掌握SSH框架与SpringMVC Hibernate集成教程
- C语言实现FFT算法及互相关性能优化指南
