CE-Net:深度学习医疗图像分割的创新上下文编码器
165 浏览量
更新于2024-08-28
收藏 2.99MB PDF 举报
本文档主要介绍了一篇名为"CE-Net:用于2D医学图像分割的上下文编码器网络"的研究论文,发表在《IEEE Transactions on Medical Imaging》的第38卷第10期,2019年10月刊。医学图像分割是医疗图像分析中的关键步骤,随着卷积神经网络(CNN)在图像处理领域的快速发展,深度学习已经在诸如视网膜盘分割、血管检测、肺部分割和细胞分割等任务中得到广泛应用。然而,传统的U-Net方法由于连续池化和步进卷积操作可能导致一些空间信息的丢失。
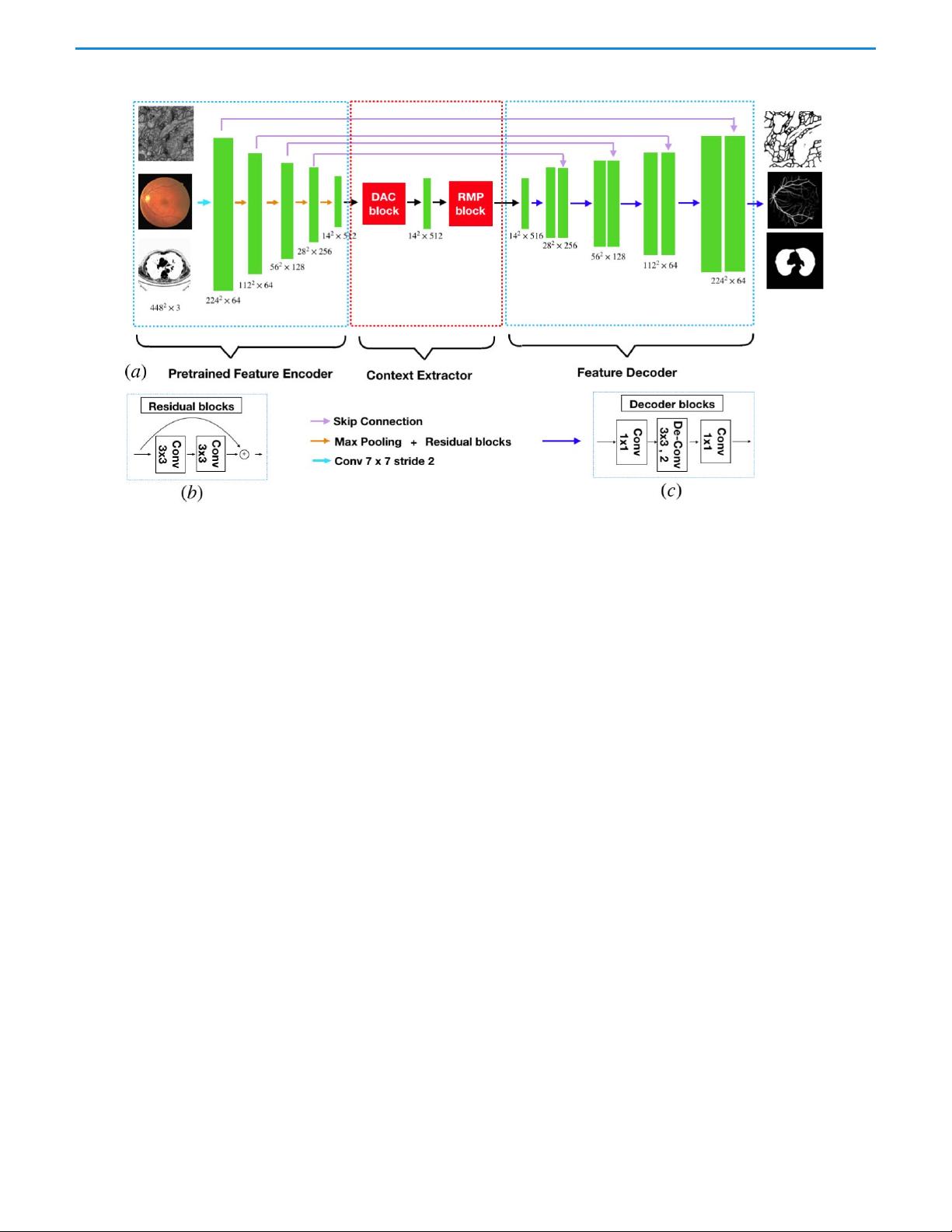
作者Zaiwang Gu、Jun Cheng、Huazhu Fu、Kang Zhou、Huaying Hao、Yitian Zhao、Tianyang Zhang、Shenghua Gao和Jiang Liu针对这一问题,提出了CE-Net,一个旨在捕捉更高级别信息并保留空间信息的上下文编码网络。CE-Net主要由三个核心组件构成:
1. 特征编码模块(Feature Encoder Module):这个部分使用预训练的ResNet块作为固定特征提取器,ResNet的深度学习结构能够提取出丰富的多层次特征,为后续处理提供高质量的基础。
2. 上下文提取器(Context Extractor):这是CE-Net的关键创新点,通过设计有效的架构,该模块能够增强对图像上下文的理解,避免了传统方法中信息的丢失,有助于保持图像的空间连贯性。
3. 特征解码模块(Feature Decoder Module):此模块负责将编码后的特征逐步解码回原始尺寸,同时结合上采样技术来恢复被压缩的空间细节,与编码过程形成互补,以实现更精确的分割结果。
CE-Net通过巧妙地结合上下文信息和空间分辨率的保持,改进了现有医学图像分割的性能,为2D医学图像的自动化分析提供了新的解决方案。这种方法不仅适用于眼科、血管和肺部等领域,还可能扩展到其他需要精细分割的应用场景,具有较高的实用价值和研究意义。
GU
et al.
: CE-NET FOR 2D MEDICAL IMAGE SEGMENTATION 2283
Fig. 1. Illustration of the proposed CE-Net. Firstly, the images are fed into a feature encoder module, where the ResNet-34 block pretrained from
ImageNet is used to replace the original U-Net encoder block. The context extractor is proposed to generate more high-level semantic feature maps.
It contains a dense atrous convolution (DAC) block and a residual multi-kernel pooling (RMP) block. Finally, the extracted features are fed into the
feature decoder module. In this paper, we adopt a decoder block to enlarge the feature size, replacing the original up-sampling operation. T he
decoder block contains 1×1 convolution and 3×3 deconvolution operations. Based on skip connection and the decoder block, we obtain the mask
as the segmentation prediction map.
from spatial pyramid pooling [55]. The RMP block fur-
ther encodes the multi-scale context features of the object
extracted from the DAC module by employing various size
pooling operations, without the extra learning weights. In
summary, the DAC block is proposed to extract enriched
feature representations with multi-scale atrous convolutions,
followed by the RMP block for further context information
with multi-scale pooling operations. Integrating the newly
proposed DAC block and the RMP block with the backbone
encoder-decoder structure, we propose a novel context encoder
network named as CE-Net. It relies on the DAC block and the
RMP block to get more abstract features and preserve more
spatial information to boost the performance of medical image
segmentation.
The main contributions of this work are summarized as
follows:
1) We propose a DAC block and RMP block to capture
more high-level features and preserve more spatial infor-
mation.
2) We integrate the proposed DAC block and RMP block
with encoder-decoder structure for medical image seg-
mentation.
3) We apply the proposed method in different tasks includ-
ing optic disc segmentation, retinal vessel detection,
lung segmentation, cell contour segmentation and retinal
OCT layer segmentation. Results show that the proposed
method outperforms the state-of-the-art methods in these
different tasks.
The remainder of this paper is organized as follows.
Section II introduces the proposed method in details.
Section III presents the experimental results and discussions.
In Section IV, we draw some conclusions.
II. M
ETHOD
The proposed CE-Net consists of three major parts: the
feature encoder module, the context extractor module, and the
feature decoder module, as shown in Fig. 1.
A. Feature Encoder Module
In U-Net architecture, each block of encoder contains two
convolution layers and one max pooling layer. In the proposed
method, we replace it with the pretrained ResNet-34 [53]
in the feature encoder module, which retains the first four
feature extracting blocks without the average pooling layer
and the fully connected layers. Compared with the original
block, ResNet adds shortcut mechanism to avoid the gradient
vanishing and accelerate the network convergence, as shown
in Fig. 1(b). For convenience, we use the modified U-net with
pretrained ResNet as backbone approach.
B. Conte xt Extractor Module
The context extractor module is a newly proposed module,
consisting of the DAC block and the RMP block. This module
extracts context semantic information and generates more
high-level feature maps.
剩余11页未读,继续阅读
1310 浏览量
359 浏览量
139 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38697557
- 粉丝: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现ART与SART算法在医学CT重建中的应用
- S2SH整合版:快速搭建Struts2+Spring+Hibernate开发环境
- 托奇卡项目团队成员介绍
- 提升外链发布效率的SEO推广神器——搜易达网络推广大师v2.035
- C#打造简易记事本应用详细教程
- 探索虚拟现实地图VR的奥秘
- iOS模拟器屏幕截图新工具
- 深入解析JavaScript在生活应用开发中的运用
- STM32F10x函数库3.5中文版详解与应用
- 猎豹浏览器v6.0.114.13396 r1:安全防护与网购敢赔
- 掌握JS for循环输出的最简洁代码技巧
- Java入门教程:TranslationFileGenerator快速指南
- OpenDDS3.9源码解析及最新文档指南
- JavaScript提示框插件:鼠标滑过显示文章摘要
- MaskRCNN气球数据集:优质图像识别资源
- Laravel日志查看器:实现Apache多站点日志统一管理
