基于电影数据的票房预测与个性化推荐算法研究
 已收录资源合集
已收录资源合集
需积分: 0 199 浏览量
更新于2024-08-05
收藏 1.3MB PDF 举报
电影数据分析1是一个旨在通过电影数据集进行深入探索和应用的项目。该研究主要关注电影特征分析、票房预测以及个性化电影推荐算法的设计与实现。项目的核心目标是利用电影的简介、关键词、预算、票房、用户评分等多维度信息,对电影进行量化分析。
实验使用的主要数据集包括TheMovieDatabase (TMDB)的7398条电影信息,这些数据提供了如电影ID、预算、票房、语言、时长、评分和受欢迎程度等特征,用于票房预测竞赛,该项目在比赛中取得了前6.8%的优秀成绩。另一个数据集是TMDB5000电影数据集和MovieLens的一部分数据,提供了电影内容描述、关键词和用户评分矩阵,用于推荐算法的开发。
在实验过程中,对电影特征进行了可视化分析,如票房与预算、受欢迎程度、戏剧性的相关性,结果显示这三者与票房有较强的正相关。此外,还研究了电影语言与票房的关系以及预算与上映年份的关联,发现语言因素可能对票房有影响,但上映年份的影响相对较小。
推荐算法部分是项目的重要组成部分,研究者设计并实现了九种不同的电影推荐算法,包括基于统计学的推荐、基于内容的推荐算法、KNN协同过滤算法以及融合了奇异值分解、集成学习等多种技术的推荐方法。这些算法都旨在提供更加精准和个性化的电影推荐,以提升用户体验。
总结来说,电影数据分析1项目通过深度挖掘和分析电影数据,不仅揭示了电影票房背后的规律,还为电影推荐系统提供了科学依据,为娱乐行业的决策制定和用户体验优化提供了有价值的数据支持。
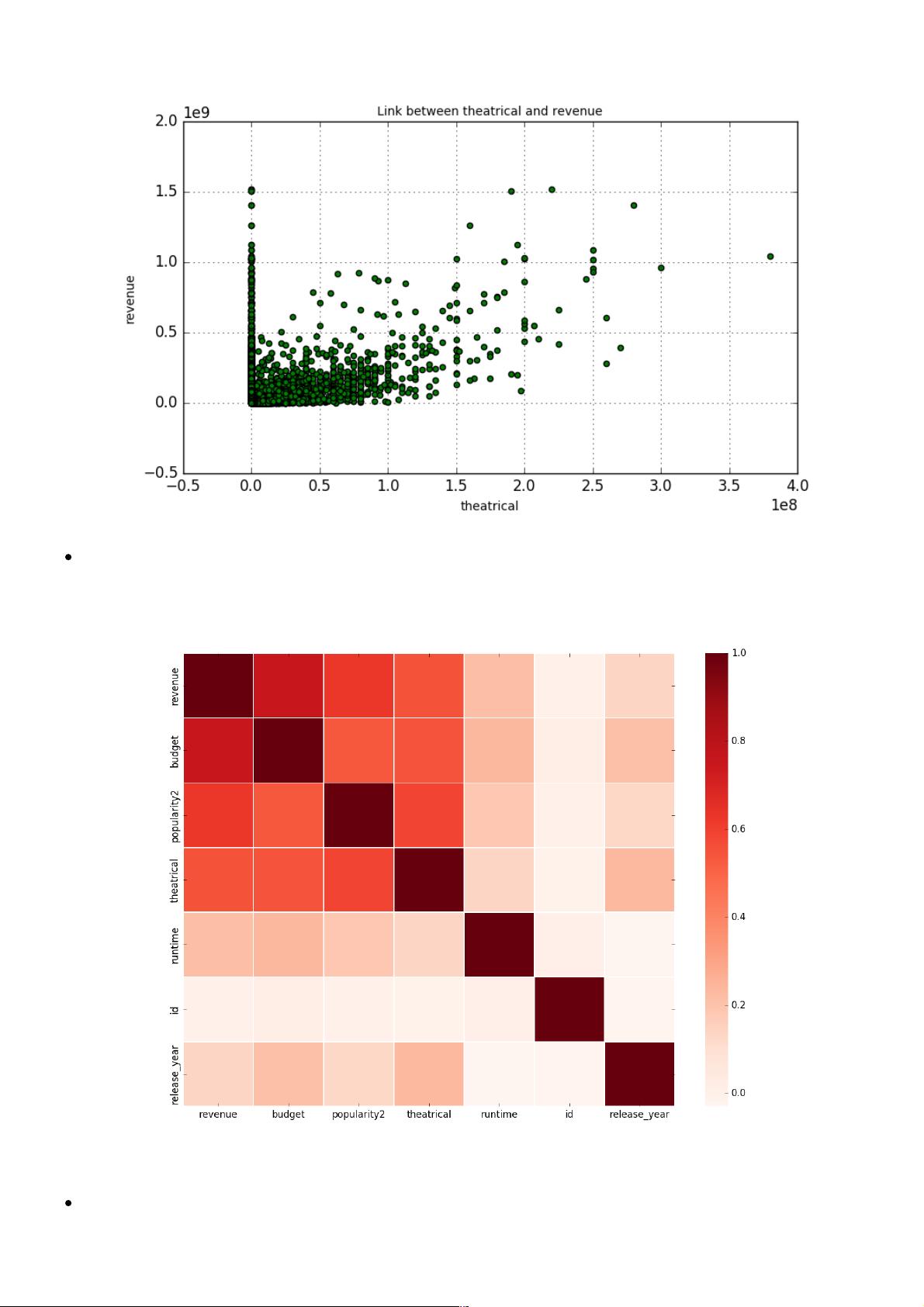
从图中可以看出,这三个特征与票房之间存在着较强的相关关系,于是我选取票房、预算、受欢迎
程度、戏剧性、放映时间、id、上映份7个特征,绘制它们之间的相关关系图,如下图所示:
图中颜越深代表相关关系越强,可以看出电影票房与预算、受欢迎程度、戏剧性三个特征有着很强的
剩余11页未读,继续阅读
1093 浏览量
2955 浏览量
2021-09-30 上传
1219 浏览量
2025 浏览量
552 浏览量
2025-01-08 上传
2024-02-15 上传

小小二-yan
- 粉丝: 33
- 资源: 299
 我的内容管理
展开
我的内容管理
展开







最新资源
- 顶部导航菜单下拉,左侧分类切换
- XX公司企业文化职能战略规划PPT
- torch_cluster-1.5.6-cp37-cp37m-win_amd64whl.zip
- 使用WPF表单的AC#系统托盘应用程序
- Color-Transfer-between-Images:这是开源工具Erik Reinhard,Michael Ashikhmin,Bruce Gooch和Peter Shirley撰写的论文“图像之间的颜色转移”
- log4net工具包与配置文件.rar
- 企业文化案例(8个文件)
- PokemonGo-CalcyIV-Renamer:使用adb将假冒的点击事件发送到您的手机,以及Calcy IV一起自动重命名所有宠物小精灵
- torch_sparse-0.6.5-cp36-cp36m-win_amd64whl.zip
- cd2021
- Angel网络工作室报名网站管理系统v1.0
- CssWebResposive:罪过的评论
- 导航条宽度随二级菜单宽度变化的
- 系统温湿度检测与控制 1-源程序注释.rar
- iicTets.zip
- QAServer:基于质量检查服务器的中文CQA网站
