Python爬取3032个美食菜谱:数据清洗与分析实战
126 浏览量
更新于2024-06-16
收藏 4.09MB DOCX 举报
本文主要介绍了如何利用Python编程语言进行美食信息的网络抓取和数据分析,以实现成为一个合格的“吃货”。作者首先从豆果美食网抓取了3032个菜谱,这些菜谱涵盖了川菜、粤菜、湘菜等八大中国菜系,包括菜谱名称、链接、所需材料、评分以及图片等关键信息。数据获取部分,作者分享了使用Python的简洁代码,通过构建URL模板和递归爬取多页来实现数据抓取。
在数据清洗阶段,作者强调了数据预处理的重要性。他们使用了Pandas库,这是一个强大的数据处理工具,对数据进行了去重(删除重复的菜谱)、处理缺失值(剔除含有缺失数据的记录)以及评分字段的规范化(将评分字段中的字符串转化为数字以便于后续的统计和分析)。通过删除重复项和处理缺失值,确保了数据的质量和可用性。
主函数`main()`定义了一个动态URL生成器,用于指定菜系和页码,通过`time.sleep()`函数随机增加等待时间以避免过于频繁的请求被识别为机器人。循环结构遍历了所有中国菜系,并爬取了每种菜系的多页数据,展示了灵活的爬虫设计。
整个过程不仅涉及到了网络爬虫技术,还运用了Python编程的基础知识,如字符串操作、函数定义和异常处理,以及数据科学中的数据清洗和预处理。通过分析这些抓取的菜谱数据,作者可以进一步探索菜谱的受欢迎程度、地域分布、评分趋势等,从而为读者提供个性化的美食推荐或进行深入的美食研究。
本文对于想要学习Python网络爬虫或对美食爱好者来说,提供了实用的技巧和示例,有助于提升数据处理能力,并帮助他们在享受美食的同时,也能从数据中发现乐趣和洞察。
1818 title_opts=opts.TitleOpts(title="菜谱评分分布"
1919 ),
2020 legend_opts=opts.LegendOpts(
2121 orient="vertical", pos_top="5%", pos_left="2%"
,textstyle_opts=opts.TextStyleOpts(font_size=14)# 左⾯⽐例尺
2222 ),
2323
2424
2525 )
2626 .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%",font_size=18),
2727 )
2828 )
2929c.render_notebook()
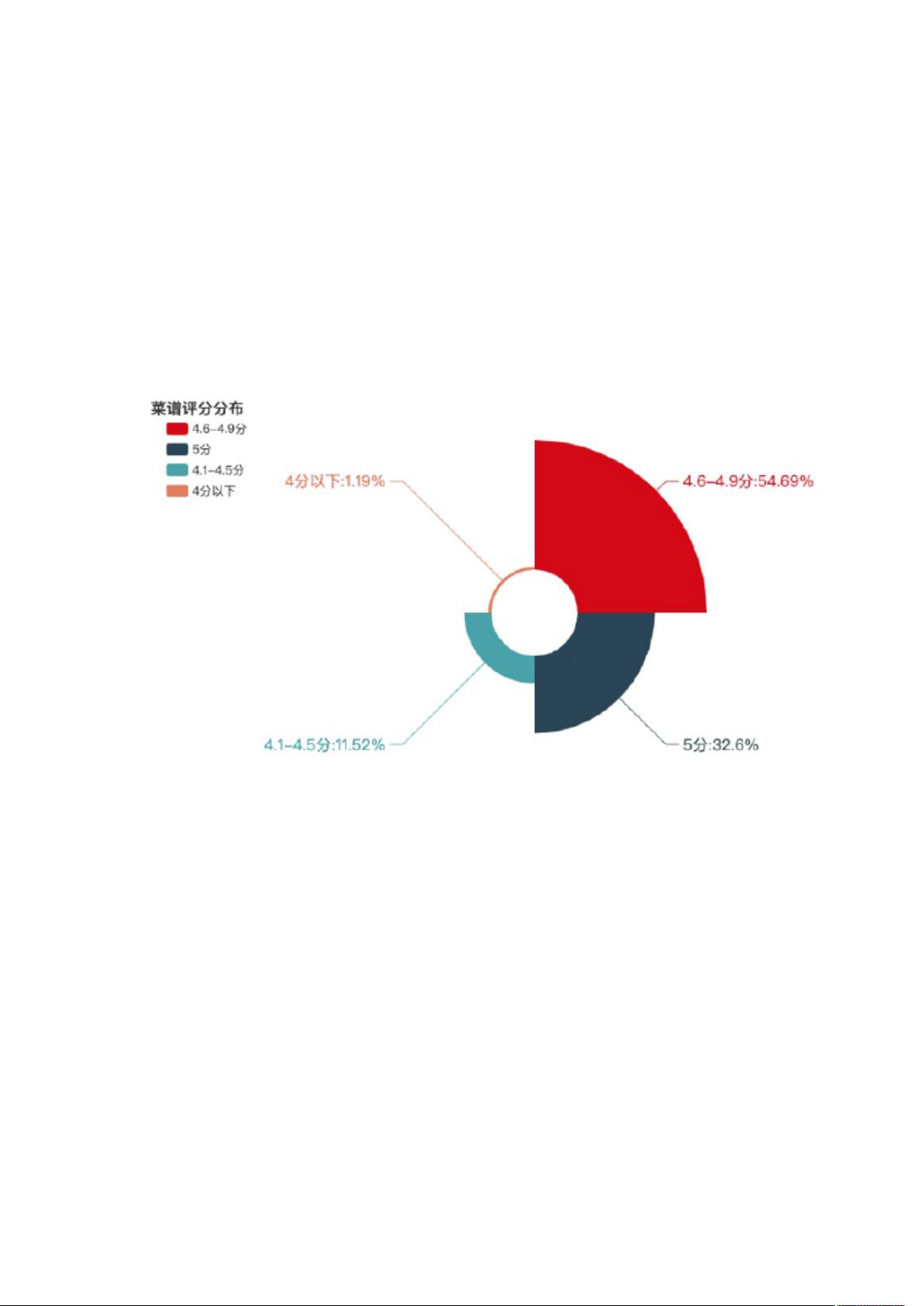
⾖果美⾷⽹菜谱评分实⾏5分制。由上图可知,4分以下的菜谱占⽐不到2%,满分菜谱
⾼达32.6%,可见⽤户对中国菜系菜谱评价普遍较⾼。
各菜系菜谱数量对⽐
1
21from pyecharts import options as opts
3 2from pyecharts.charts import Page, Pie
4 3df2 = df.groupby('菜系')['评分'].count() #按菜系分组,对评分计数
5 4df2 = df2.sort_values(ascending=False) #降序
6 5print(df2)
7 6c = (
8 7 Pie()
9 8 .add("", [list(z) for z in zip(df2.index.to_list(),df2.to_list())])
10 9
.set_global_opts(title_opts=opts.TitleOpts(title="各菜系菜谱数量占⽐",subtitle="数据来源
:⾖果美⾷"))
1110 .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
1211 )
1312c.render_notebook()
剩余15页未读,继续阅读
1302 浏览量
2024-02-10 上传
223 浏览量
2024-07-11 上传
2017-05-04 上传
196 浏览量
143 浏览量
2022-05-15 上传


zz_ll9023one
- 粉丝: 916
 我的内容管理
展开
我的内容管理
展开







最新资源
- PixelBuilder:小型Java绘图程序源码解析
- 深入理解JavaScript中的Map和Set ES模块特性
- 3D展厅模型设计:展示模型设计的新趋势
- 深入浅出嵌入式QT编程技术指南
- 提升浏览体验:冰王主题4K高清壁纸crx插件
- 探索C语言实战项目案例:源码网站推荐与项目源码分享
- si702stara项目分析及Jupyter Notebook应用
- C#开发者挑战:Xero发票处理解决方案
- Ruby开发中Elasticsearch的集成与应用
- 高清壁纸扩展:个性化新标签页体验
- PixeliumJava源码解析:Android多功能绘图应用实现
- 前端开发项目EKSAMEN:构建与部署流程详解
- WordPress智能next/prev按钮插件发布,全面兼容Classic和Gutenberg!
- 实现图片拖拽到指定位置的JavaScript方法
- C语言实战项目:录音机与赛车游戏源码解析
- TempleSignUp项目1的C#开发实践
