Tmsvm 1.0.0:基于SVM的文本挖掘系统详解与调用方法
需积分: 0 191 浏览量
更新于2024-06-30
收藏 1.04MB PDF 举报
Tmsvm是一款基于支持向量机(SVM)的文本挖掘系统,版本为1.0.0,由张知临开发并维护。该系统的目的是通过SVM技术处理文本数据,提供了一套全面的工具和接口,以解决文本分类、预测以及特征选择等问题。
**第1章简介**
- **主要特征**:Tmsvm的核心优势在于其支持多种功能,包括训练SVM模型、模型预测、多模型预测、结果分析、分词、特征选择等,适应于文本挖掘的各种场景。
- **利用此系统可以做什么**:用户可以利用它进行文本分类、内容分析,以及对LSA(Latent Semantic Analysis,隐含语义分析)模型的支持,有助于理解和处理大规模文本数据。
- **系统解决的问题**:Tmsvm旨在解决文本数据中的模式识别、文本分类任务,提升文本理解与挖掘效率。
- **程序文件说明**:文档详细介绍了如何使用不同程序进行训练(如`auto_train.py`、`train.py`)、预测,以及如何处理LSA模型的训练和预测。
- **调用方法**:提供了在程序中直接调用和在命令行界面操作的两种方式,方便用户根据需求灵活使用。
**第2章程序调用接口**
- **使用前必看**:这部分强调了在使用前了解系统要求和基本用法的重要性。
- **输入格式及输出**:明确了输入文本的格式和预期的输出结果,包括训练数据、预测结果和分析报告。
- **模型构建**:详细说明了如何训练SVM模型,涉及参数设置和模型优化过程。
**第3章技术细节**
- **LSA**:介绍了LSA在文本挖掘中的应用,作为预处理步骤,用于降低数据维度和增强语义表达。
- **特征选择**:讨论了如何从大量特征中选择最有效的特征组合,提高模型性能。
- **SVM参数选择**:涉及调优SVM模型的关键参数,如C值和核函数类型等。
- **Libsvm与liblinear**:对比了两个库在Tmsvm中的应用,可能涉及到不同算法的选择。
**第4章源码剖析**
- **文本格式转换**:展示了如何将原始文本转化为SVM模型所需的输入格式,以便系统处理。
- **批量处理**:讲解了如何处理大量文本数据,以便进行模型训练和分析。
Tmsvm是一款功能强大的文本挖掘工具,结合了SVM和LSA技术,提供了丰富的接口和细节说明,帮助用户高效地进行文本分类、特征选择和模型训练。通过阅读这份文档,用户可以掌握如何利用Tmsvm进行文本处理,以及如何根据具体需求调整和优化模型。
Tmsvm- Text Mining System based on SVM
6
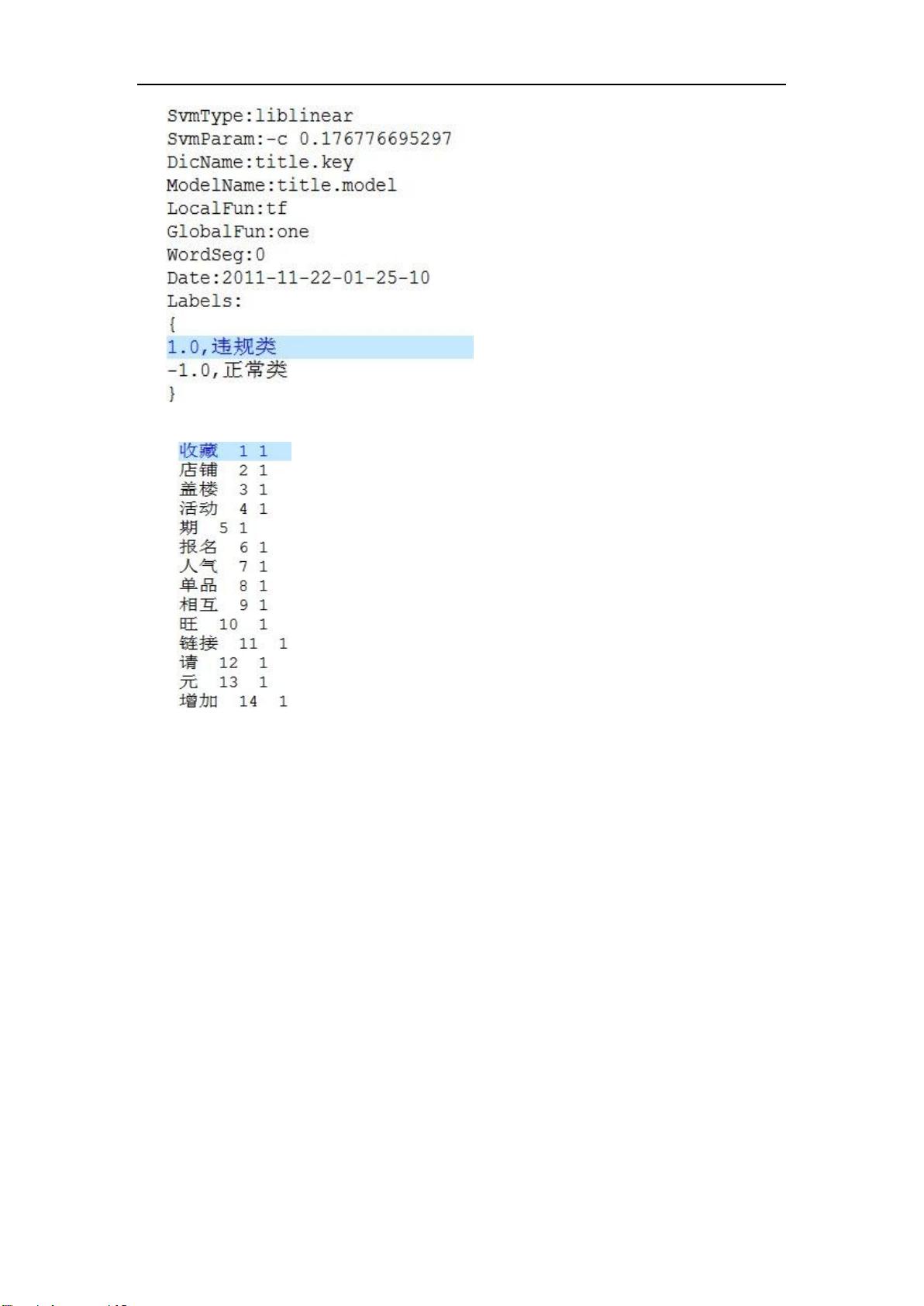
SvmType: 指 代 选 择 的 是 libsvm 还是
liblinear
SvmParam:指代训练模型的参数。
DicName:词典存储的名称
ModelName:模型存储的名称.
LocalFun:特征权重中局部函数
GlobalFun:特征权重中全局因子
WordSeg:训练样本使用的分词工具
Labels:训练样本的各个类标签以及解释
dic.key 是模型的词典。
词典包括 3 列:第一列为 term,第二列为 id,第三列
位 global weight,因为在计算特征向量每个 term 的权重
时,全局因子部分至于词有关,所以可以直接根据训练样本
计算出来放置在词典中,方便使用。
tms.model 就是最终的 SVM 模型,或者是 libsvm 的模型或者是 liblinear 的模型。

剩余38页未读,继续阅读
2022-08-08 上传
2022-08-08 上传
2022-12-14 上传

阿汝娜老师
- 粉丝: 32
- 资源: 309
 我的内容管理
展开
我的内容管理
展开







最新资源
- 多步表单
- ADcontroller.rar_VHDL/FPGA/Verilog_VHDL_
- 适用于WebMessage客户端的iOS调整伴侣-Swift开发
- symhx-backstage
- pika:Pure Python RabbitMQAMQP 0-9-1客户端库
- SynchQt-开源
- wp的Web服务编程案例
- 你好,世界
- tic-tac-toe.rar_棋牌游戏_Java_
- typescript-api:使用打字稿制作的REST API服务器
- 金字塔:金字塔-一个Python网络框架
- transfer-.meta-to-.pb:把模型的ckpt文件和meta文件转化成pb文件
- Tabs To Batch-crx插件
- Swift的XML / HTML解析器-Swift开发
- index.php_QQ浏览器压缩包.zip
- 参考资料-FR-NK0115资金审批单(加编号).zip
