Eclipse连接Hadoop详细配置教程
下载需积分: 10 | DOCX格式 | 796KB |
更新于2024-09-10
| 38 浏览量 | 举报
"eclipse连接hadoop的详细配置教程指南,适用于hadoop初学者。"
在进行Eclipse连接Hadoop的配置过程中,我们需要确保系统已经安装了Hadoop并且配置了相应的环境。以下是一份详细的步骤指南:
首先,我们需要有一个运行在Linux上的Hadoop集群。在这个例子中,我们使用的版本是Hadoop 3.2.7。这个版本的Hadoop应该已经被下载并存放在Linux的磁盘中。为了能够在Eclipse中进行开发和测试,我们需要将Hadoop的Java库引入到我们的开发环境中。
配置Eclipse插件:
1. 找到Hadoop安装目录下的`bin`目录,其中包含了一些与操作Hadoop相关的动态链接库(`.dll`文件)。这些文件需要被复制到操作系统的`system32`目录中。对于Windows系统,通常是`C:\Windows\System32`。
2. 接下来,我们需要将Hadoop的相关`jar`包复制到Eclipse的插件目录。通常,这个目录位于Eclipse的安装路径下的`plugins`文件夹内。这样做的目的是为了让Eclipse识别Hadoop的相关类库,以便于编写和调试Hadoop程序。
配置环境变量:
1. 添加Hadoop的安装目录到系统的`PATH`环境变量中,这样在命令行中就可以直接运行Hadoop的命令了。
2. 设置`HADOOP_HOME`环境变量,指向Hadoop的根目录,例如 `/usr/local/hadoop`。
3. 更新`JAVA_HOME`环境变量,确保它指向的是你的Java JDK安装路径,因为Hadoop依赖Java运行。
接下来,我们需要配置本地主机文件,以便Eclipse能够正确地与Hadoop集群通信。打开`C:\Windows\System32\drivers\etc\hosts`文件,并添加Hadoop集群中NameNode节点的IP地址和主机名映射,例如:
```
192.168.1.100 namenode.example.com
```
这里,`192.168.1.100`是NameNode的IP地址,`namenode.example.com`是其主机名。
最后,如果需要清理Hadoop的文件系统,可以使用Hadoop的命令行工具。例如,`hadoop fs -rmr /home/mm/lily2`会删除指定的目录。请确保你的PATH环境变量已经包含了Hadoop的`bin`目录,并且Hadoop服务已经启动,这样这个命令才能执行成功。
通过以上步骤,Eclipse就成功配置好连接Hadoop的环境,可以开始编写MapReduce程序或Spark作业,并在Eclipse中进行调试和测试了。这对于初学者来说是一个很好的起点,能够方便地进行Hadoop开发工作。
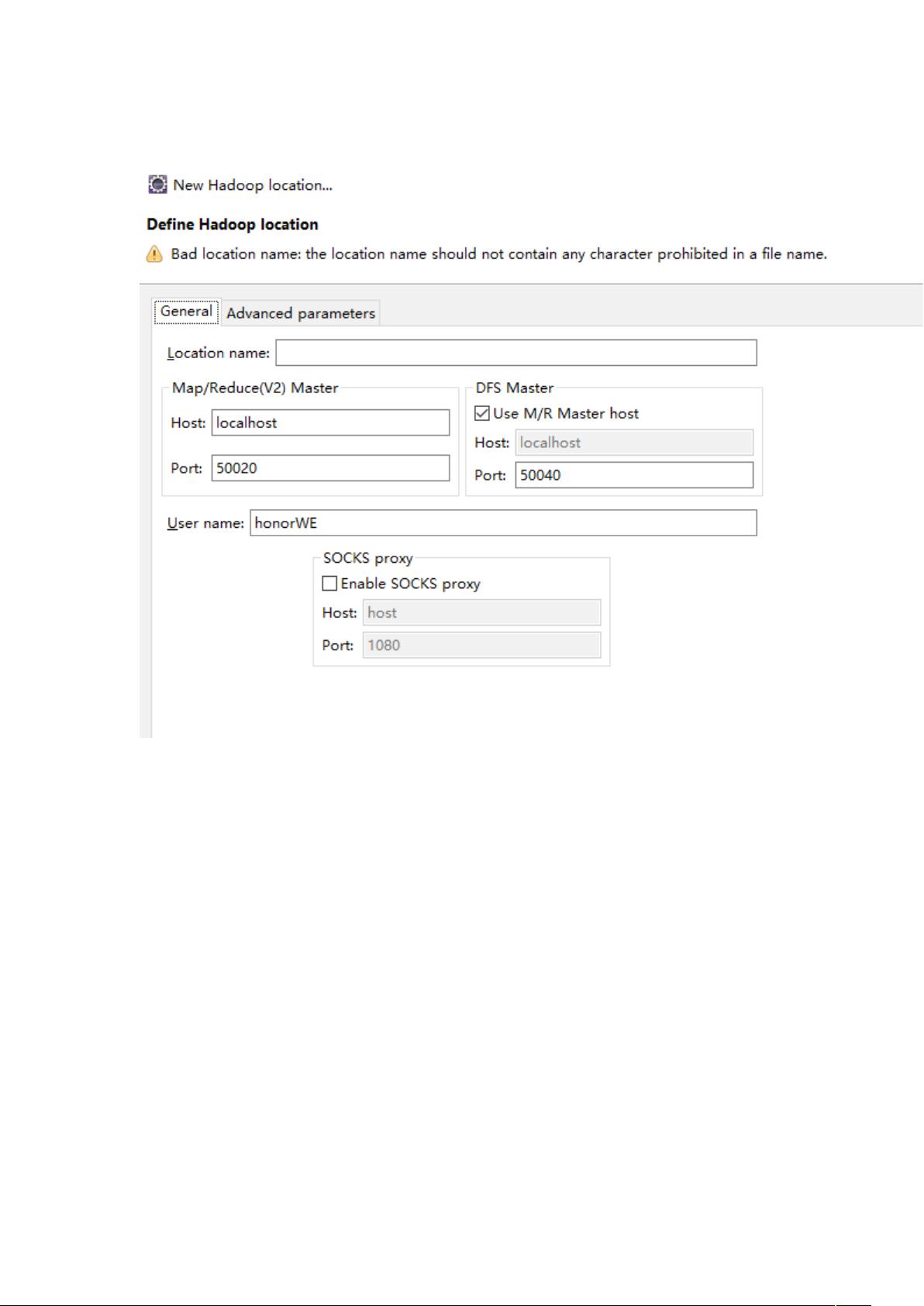
Hadoop 小象 hdfs 连接:
下载后可阅读完整内容,剩余7页未读,立即下载
相关推荐





fendou人
- 粉丝: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- QT平台下多线程TCP服务器的开发与实现
- Axure RP PRO原型设计模板资源包
- React构建的git命令Web应用:简化学习与使用体验
- 德克萨斯算法优化指南与实践详解
- Ethereal-Page项目概览:探索空页的秘密
- VB版日历壁纸制作工具源码公开
- 实现Java数据到PHP格式的序列化转换技术
- Paragon NTFS v15.8.243:Mac系统读写NTFS文件工具
- Wii游戏备份管理工具WiiBackupManager0.38发布
- Async-http-client:便捷高效的HTTP通信库
- vev:轻松构建Python简单HTTP服务器
- 杭州盈控SP610硬件安装与选型指南
- 在VS2008中如何修改MFC ListCtrl的文字颜色
- DE2-115平台FLASH写读实验指南
- IE11浏览器官方版介绍及特性解析
- 2022知识图谱研究精选:论文、应用与趋势
