深度强化学习:一场人工智能革命
需积分: 9 106 浏览量
更新于2024-09-02
收藏 4.99MB PDF 举报
"这篇论文是关于深度增强学习的综述,深入探讨了这一领域如何革新人工智能,并在构建具有更高层次视觉世界理解的自主系统中所起的作用。深度学习的应用使得强化学习能够解决以往难以处理的问题,例如直接从像素数据学习玩视频游戏。此外,它也被应用于机器人控制,使真实世界的摄像头输入可以直接学习到机器人的控制策略。论文概述了强化学习的基础,然后深入到基于价值和基于策略的方法的主要流派,涵盖了深度Q网络、信任区域策略优化和异步优势演员-评论家等核心算法,并突显了深度强化学习的独特优势和挑战。"
在深度强化学习(Deep Reinforcement Learning, DRL)这个领域,人工智能正经历着一场革命性的变化。DRL结合了深度学习的表征能力与强化学习的决策制定机制,使得智能体能够从高维度、复杂环境中学习有效的行为策略。在视觉任务中,DRL允许智能体直接从原始像素数据中学习,从而超越了传统的特征工程方法。
强化学习(Reinforcement Learning, RL)的基本框架包括环境、智能体和奖励信号。智能体通过与环境交互,执行动作并接收奖励,目标是通过学习最大化累计奖励。DRL的关键在于使用神经网络来近似值函数或策略函数,这使得它能够处理连续的、高维的状态和动作空间。
在价值基础方法中,深度Q网络(Deep Q-Network, DQN)是一个里程碑式的算法,它解决了Q学习中的经验回放缓冲区和目标网络问题,实现了在Atari游戏上的成功应用。而信任区域策略优化(Trust Region Policy Optimization, TRPO)则是一种策略梯度方法,通过约束策略更新的幅度以保持稳定性。
另一方面,基于策略的方法如异步优势演员-评论家(Asynchronous Advantage Actor-Critic, A3C)利用多线程并行执行来加速学习过程,同时改进了策略和价值函数的估计。A3C的优势在于其并行化特性,能够在实际应用中更快地收敛。
DRL在机器人控制领域的应用尤其引人注目,因为它可以训练智能体直接从现实世界的摄像头输入中学习控制策略,无需预先设计复杂的传感器系统。尽管DRL取得了显著的进步,但仍然面临许多挑战,如样本效率低、泛化能力差以及模型的不稳定性。未来的研究将继续关注这些问题,以推动DRL在更广泛的应用场景中发挥潜力。
TO APPEAR IN IEEE SIGNAL PROCESSING MAGAZINE, SPECIAL ISSUE ON DEEP LEARNING FOR IMAGE UNDERSTANDING 3
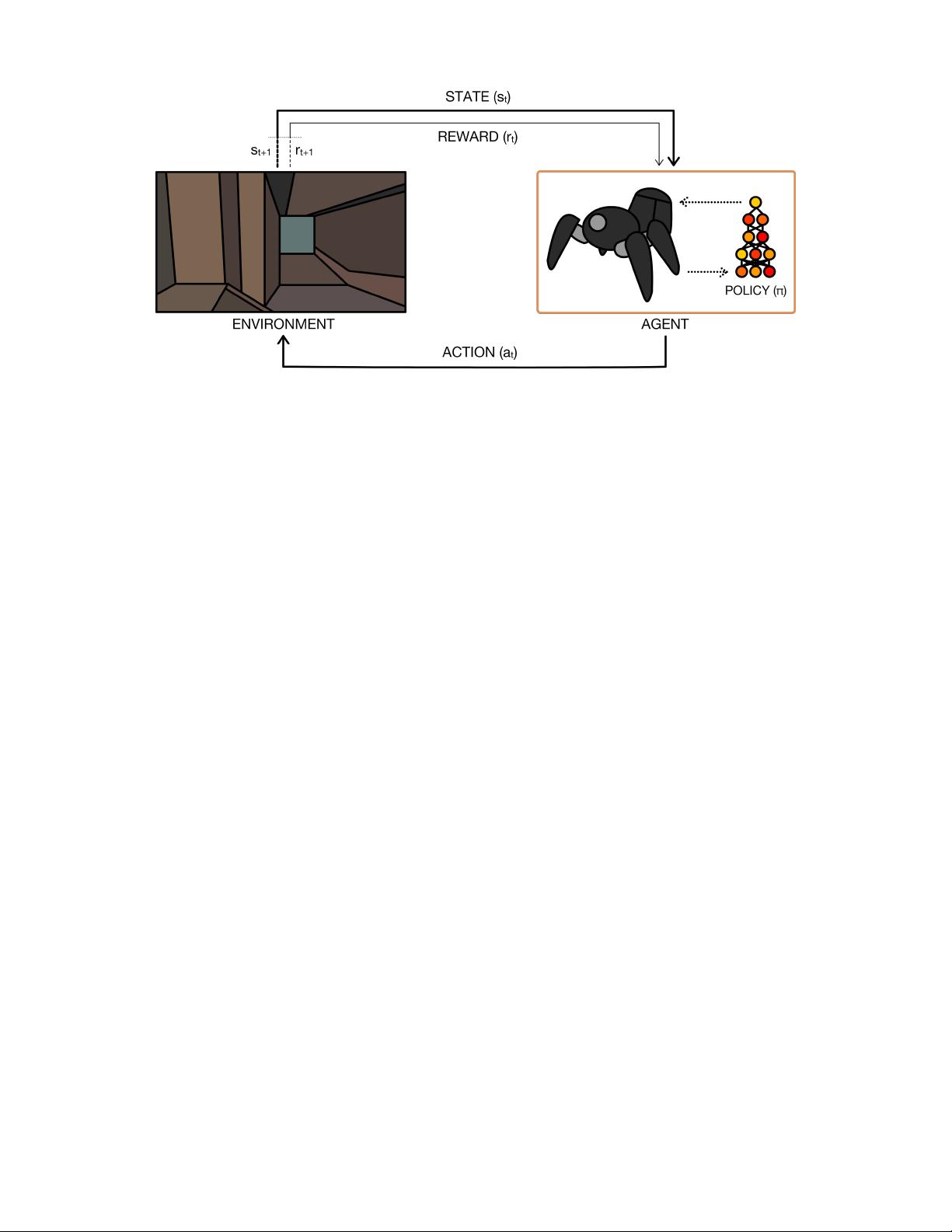
Fig. 2. The perception-action-learning loop. At time t, the agent receives state s
t
from the environment. The agent uses its policy to choose an action a
t
.
Once the action is executed, the environment transitions a step, providing the next state s
t+1
as well as feedback in the form of a reward r
t+1
. The agent
uses knowledge of state transitions, of the form (s
t
, a
t
, s
t+1
, r
t+1
), in order to learn and improve its policy.
learning loop is illustrated in Figure 2.
A. Markov Decision Processes
Formally, RL can be described as a Markov decision process
(MDP), which consists of:
• A set of states S, plus a distribution of starting states
p(s
0
).
• A set of actions A.
• Transition dynamics T (s
t+1
|s
t
, a
t
) that map a state-
action pair at time t onto a distribution of states at time
t + 1.
• An immediate/instantaneous reward function
R(s
t
, a
t
, s
t+1
).
• A discount factor γ ∈ [0, 1], where lower values place
more emphasis on immediate rewards.
In general, the policy π is a mapping from states to a
probability distribution over actions: π : S → p(A = a|S). If
the MDP is episodic, i.e., the state is reset after each episode of
length T , then the sequence of states, actions and rewards in an
episode constitutes a trajectory or rollout of the policy. Every
rollout of a policy accumulates rewards from the environment,
resulting in the return R =
P
T −1
t=0
γ
t
r
t+1
. The goal of RL is
to find an optimal policy, π
∗
, which achieves the maximum
expected return from all states:
π
∗
= argmax
π
E[R|π] (1)
It is also possible to consider non-episodic MDPs, where
T = ∞. In this situation, γ < 1 prevents an infinite sum
of rewards from being accumulated. Furthermore, methods
that rely on complete trajectories are no longer applicable,
but those that use a finite set of transitions still are.
A key concept underlying RL is the Markov property,
i.e., only the current state affects the next state, or in other
words, the future is conditionally independent of the past given
the present state. This means that any decisions made at s
t
can be based solely on s
t−1
, rather than {s
0
, s
1
, . . . , s
t−1
}.
Although this assumption is held by the majority of RL
algorithms, it is somewhat unrealistic, as it requires the states
to be fully observable. A generalisation of MDPs are partially
observable MDPs (POMDPs), in which the agent receives an
observation o
t
∈ Ω, where the distribution of the observation
p(o
t+1
|s
t+1
, a
t
) is dependent on the current state and the
previous action [45]. In a control and signal processing con-
text, the observation would be described by a measurement/
observation mapping in a state-space-model that depends on
the current state and the previously applied action.
POMDP algorithms typically maintain a belief over the
current state given the previous belief state, the action taken
and the current observation. A more common approach in
deep learning is to utilise recurrent neural networks (RNNs)
[138, 35, 36, 72, 82], which, unlike feedforward neural
networks, are dynamical systems. This approach to solving
POMDPs is related to other problems using dynamical systems
and state space models, where the true state can only be
estimated [12].
B. Challenges in RL
It is instructive to emphasise some challenges faced in RL:
• The optimal policy must be inferred by trial-and-error
interaction with the environment. The only learning signal
the agent receives is the reward.
• The observations of the agent depend on its actions and
can contain strong temporal correlations.
• Agents must deal with long-range time dependencies:
Often the consequences of an action only materialise after
many transitions of the environment. This is known as the
(temporal) credit assignment problem [115].
We will illustrate these challenges in the context of an
indoor robotic visual navigation task: if the goal location is
specified, we may be able to estimate the distance remaining
(and use it as a reward signal), but it is unlikely that we will
know exactly what series of actions the robot needs to take
to reach the goal. As the robot must choose where to go as it
剩余13页未读,继续阅读
613 浏览量
2023-08-28 上传
250 浏览量
215 浏览量
244 浏览量
2023-12-11 上传
270 浏览量
122 浏览量

欧美噶
- 粉丝: 36
 我的内容管理
展开
我的内容管理
展开







最新资源
- 久度免费文件代存系统 v1.0:全技术领域源码分享
- 深入解析caseyjpaul.github.io的HTML结构
- HTML5视频播放器的实现与应用
- SSD7练习9完整答案解析
- 迅捷PDF完美转PPT技术:深度识别PDF内容
- 批量截取子网页工具:Python源码分享与使用指南
- Kotlin4You: 探索设计模式与架构概念
- 古典风格茶园茶叶酿制企业网站模板
- 多功能轻量级jquery tab选项卡插件使用教程
- 实现快速增量更新的jar包解决方案
- RabbitMQ消息队列安装及应用实战教程
- 简化操作:一键脚本调用截图工具使用指南
- XSJ流量积算仪控制与数显功能介绍
- Android平台下的AES加密与解密技术应用研究
- Место-响应式单页网站的项目实践
- Android完整聊天客户端演示与实践
