提升偏标记学习精度:改进特征引导消歧算法
版权申诉
48 浏览量
更新于2024-06-28
收藏 1.1MB DOCX 举报
本文档主要探讨了改进特征引导消歧的偏标记学习算法,一种针对弱监督条件下的机器学习方法。在监督学习中,数据通常附有明确的标记,但在现实世界中,由于标记成本高或难以获取,数据往往存在偏标记,即每个实例关联着一组候选标签,其中只有一部分是真实的。偏标记学习正是解决这类问题的关键,它通过处理有干扰的标签来训练分类模型,提高识别精度,避免了单纯依赖于精确标记的学习方法可能带来的性能损失。
1.1 特征引导消歧
文献中介绍的原始方法,借鉴了特征感知消歧的思想,将偏标记问题转化为多输出回归。该方法首先通过学习样本在特征空间中的流形结构,获取结构信息,然后利用这些信息为每个候选标签生成置信度得分,再通过正则化的多输出回归模型找出最具置信度的标签作为预测结果。这种方法利用了特征空间的信息,提高了消歧的准确性。
1.2 改进的特征引导消歧
传统方法存在不足,即过于依赖标签信息空间,未能充分利用样本特征间的相关性。为解决这个问题,文章提出了一种改进的策略,强调特征信息的重要性。它不再仅仅依靠最小二乘法计算样本间的关系权重,而是综合考虑多种相似度度量,以更全面的方式评估特征间的相关性。同时,借助集成学习技术,该方法对分类模型的生成进行了优化,旨在提升整体的泛化能力和性能。
改进特征引导消歧的偏标记学习算法的优势在于其能够有效地利用特征信息,增强模型的鲁棒性和准确性,尤其适用于那些标记噪声较多或难以获取真实标记的场景,如搜索引擎中的图片识别问题。在实际应用中,该算法已经在图像分类、医疗诊断、文本挖掘和医学图像处理等领域展现了良好的效果和广泛的应用潜力。
总结来说,本文的核心贡献在于提出了一种更加智能和全面的特征导向消歧策略,通过整合特征信息和多种相似度衡量,优化了偏标记学习过程,从而在处理复杂的真实世界问题时,提升了学习模型的性能和泛化能力。这对于推进弱监督学习的研究以及其实践应用具有重要意义。
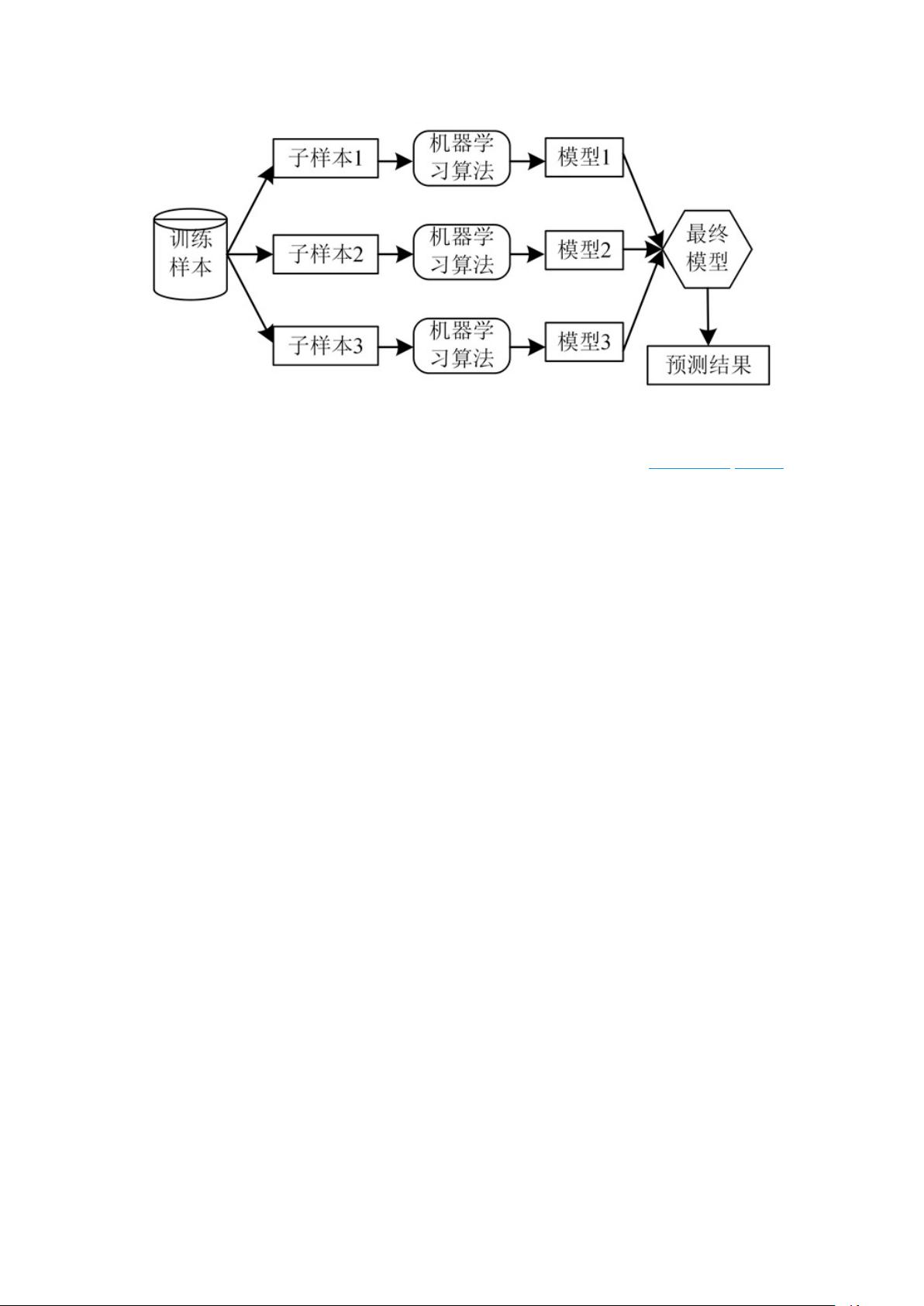
图 1 分类模型的流程示意图
下载: 全尺寸图片 幻灯片
根据 A 是否在某个结点处被划分为 2 个样本集合 D
1
和 D
2
,在特征 A 的条件下,集合
D 的基尼指数被定义为
。Gini(D,A)=|D1||D|Gini(D1)+|D2||D|Gini(D2) 。
(8)
如何确定叶子节点的预测值是构建 cart 树的关键,将决策树视为一个分段函数,分段
的依据是某个属性的基尼系数值,在节点处,根据每个叶子结点确定一个分段区间,叶子
节点的输出即为函数在该节点的值。
1.3 本算法流程
PL-FGD 算法被分为 2 个阶段,第一阶段是用改进的特征引导方法对偏标记数据进行
消歧处理;第二阶段是采用集成学习中的 bagging 策略构建分类模型,并使用 CART 决策
树作为单个分类器对划分后的数据子集进行训练。详细的过程如下:在消歧阶段,首先对
不同类别的示例采用最小二乘的方法进行权重计算;再采用更适用于多维空间的皮尔逊相
关系数计算标签之间的相似度,解决示例之间相似度计算中的单一性问题;最终得到迭代
后的置信度矩阵,实现对不同类别示例消歧的目的,并得到用于分类模型的输入数据。在
分类阶段,采用集成学习的方法预测真实标记,同时将 Cart 树作为弱分类器构成单个决策
树,对划分好的数据进行训练,将其与 bagging 算法结合。在 UCI 数据集和偏标记数据集
上的实验结果表明,本算法表现出更高的分类准确率。算法流程如算法 1 所示。
算法 1 PL-FGD 算法流程
输入:
D:输入样本训练集{x
i
, S
i
| 1≤i≤ m}
k: 近邻样本个数
λ, μ: 函数的模型参数
剩余15页未读,继续阅读
2023-02-23 上传
2022-12-15 上传

罗伯特之技术屋
- 粉丝: 4493
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
