KSQL:Apache Kafka的实时流处理SQL工具
157 浏览量
更新于2024-08-28
收藏 331KB PDF 举报
"KSQL是Apache Kafka的开源流式SQL引擎,旨在简化流处理,提供交互式的SQL接口,使得无需编程即可处理Kafka中的数据。KSQL具备开源、分布式、可扩展、可靠和实时的特性,支持聚合、连接、窗口、会话等多种流处理操作。与传统的SQL数据库不同,KSQL专注于连续转换而非查找,适用于实时监控和实时分析。通过KSQL,用户可以定义实时的业务指标,监控应用程序的正确性,从事件流中提取定制信息,而不仅仅局限于性能统计。"
KSQL的核心功能和优势在于它的流处理能力。通过使用SQL语法,用户可以轻松地对流入Kafka的主题数据执行复杂的操作,如窗口化聚合(如TUMBLING窗口)来计算实时指标,例如在特定时间窗口内的错误计数。这种实时分析的能力使得KSQL在实时监控、异常检测和快速响应场景中非常有用。
例如,在上述示例中,`CREATE TABLE error_counts AS SELECT error_code, count(*) FROM monitoring_stream WINDOW TUMBLING (SIZE 1 MINUTE) WHERE type='ERROR'` 这条命令创建了一个表,实时统计每分钟内监测流中的错误次数。这种实时监控的能力对于快速识别和解决问题至关重要,因为它可以立即通知用户系统中可能出现的问题。
KSQL的另一个优点是其灵活性。它可以连接不同的数据流和静态表,使用户能够实时地融合和分析数据。这种能力在现代微服务架构中尤为关键,因为数据通常在多个服务之间流动,KSQL能帮助确保这些服务之间的数据一致性。
此外,KSQL的分布式特性使其能够处理大规模的数据流,同时保持高可用性和容错性。由于它是建立在Kafka之上,因此它继承了Kafka的持久性和可扩展性,可以轻松处理大量并发写入和读取操作。
KSQL作为Apache Kafka的一部分,极大地降低了流处理的复杂性,使开发人员和数据分析师能够通过熟悉的SQL语法来处理实时数据流,从而实现更高效的数据洞察和决策制定。这对于那些需要实时分析和监控的业务场景,如金融交易、物联网(IoT)数据处理、网络日志分析等,具有极大的价值。
KSQL::ApacheKafka的开源流式的开源流式SQL
KSQL是一个用于Apache katkatm的流式SQL引擎。KSQL降低了进入流处理的门槛,提供了一个简单的、完全交互式的SQL
接口,用于处理Kafka的数据。你不再需要用Java或Python这样的编程语言编写代码了!KSQL是开源的(Apache 2.0许可)、
分布式的、可扩展的、可靠的和实时的。它支持广泛的强大的流处理操作,包括聚合、连接、窗口、会话,等等。
一个简单的例子
查询流数据是什么意思,这与SQL数据库有什么区别呢?
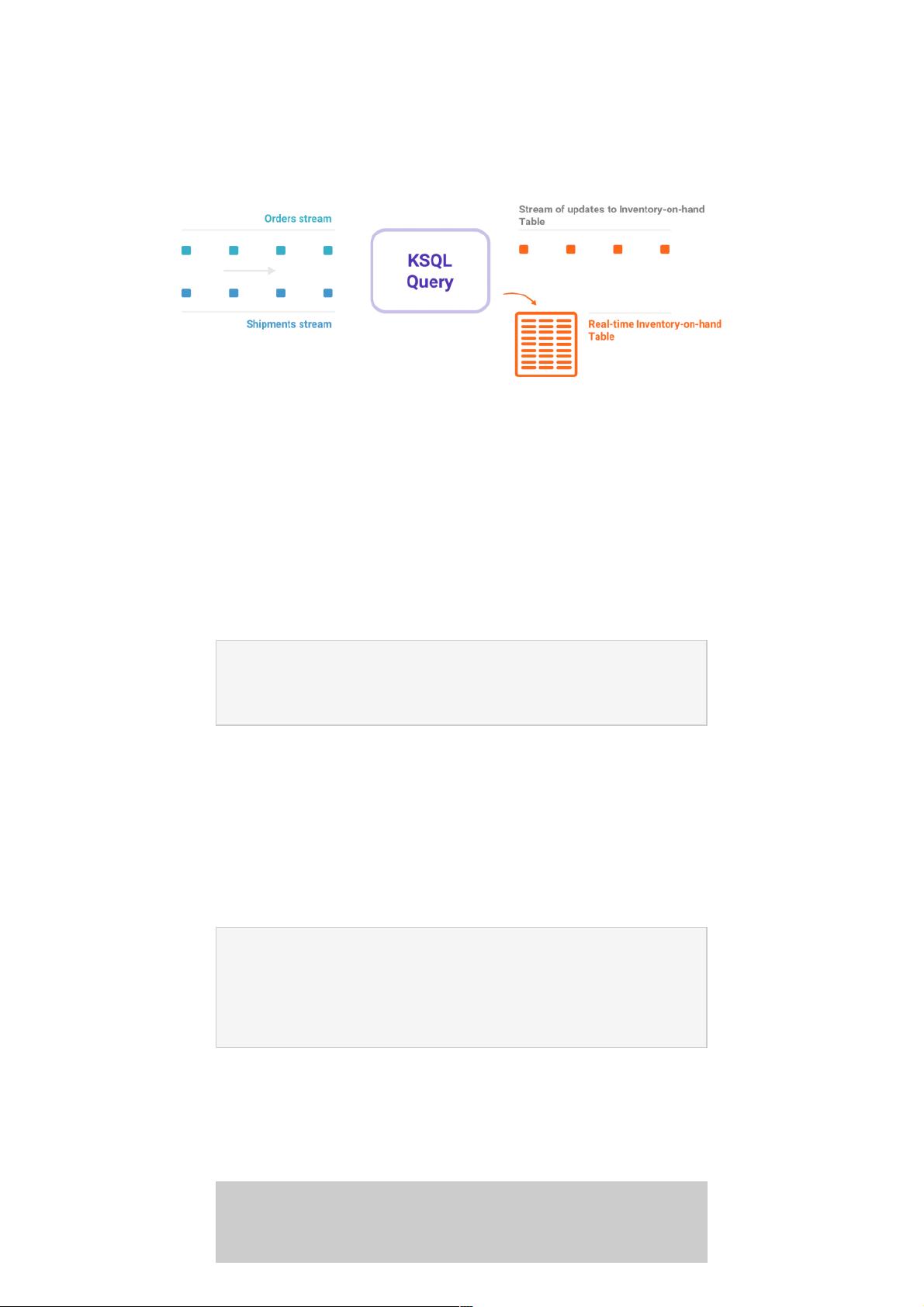
实际上,它与SQL数据库有很大的不同。大多数数据库都用于对存储数据进行按需查找和修改。KSQL不进行查找(但是),它
所做的是连续的转换——也就是,流处理。例如,假设我有一个来自用户的点击流,以及一个关于这些用户不断更新的帐户信
息的表。KSQL允许我对这一串单击和用户表进行建模,并将两者结合在一起。即使这两件事之一是无限的。
因此,KSQL所运行的是连续查询——在Kafka主题的数据流中,连续不断地运行新数据。相反,传统数据库对关系数据库的
查询是一次性查询——在数据库中运行一次SELECT语句获取有限行的数据集。
KSQL的好处是什么?
很好,所以你可以不断地查询无限的数据流。这有什么好处?
1 实时监控实时分析
CREATE TABLE error_counts AS
SELECT error_code, count(*)FROM monitoring_stream
WINDOW TUMBLING (SIZE 1 MINUTE)
WHERE type = 'ERROR'
其中的一个用途是定义定制的业务级度量,这些度量是实时计算的,您可以监视和警报,就像您的CPU负载一样。另一个用
途是在KSQL中定义应用程序的正确性的概念,并检查它在生产过程中是否会遇到这个问题。通常,当我们想到监控时,我们
会想到计数器和仪表跟踪低水平的性能统计。这些类型的测量器通常可以告诉你CPU负载很高,但是它们不能真正告诉你你
的应用程序是否在做它应该做的事情。KSQL允许从应用程序生成的原始事件流中定义定制指标,无论它们是日志事件、数据
库更新还是其他类型的事件。
例如,一个web应用程序可能需要检查,每次新客户注册一个受欢迎的电子邮件,创建一个新的用户记录,并且他们的信用卡
被计费。这些功能可能分布在不同的服务或应用程序中,您可能希望监视每个新客户在SLA中发生的每一件事,比如30秒。
2 安全性和异常检测
CREATE STREAM possible_fraud AS
SELECT card_number, count(*)
FROM authorization_attempts
WINDOW TUMBLING (SIZE 5 SECONDS)
GROUP BY card_number
HAVING count(*) > 3;
这是您在上面的演示中看到的一个简单的版本:KSQL查询,它将事件流转换为数值时间序列,使用Kafka-Elastic连接器将其注
入到弹性中,并在Grafana UI中可视化。安全用例通常看起来很像监视和分析。而不是监视应用程序的行为或业务行为,您正
在寻找欺诈、滥用、垃圾邮件、入侵或其他不良行为的模式。KSQL提供了一种简单、复杂和实时的方式来定义这些模式和查
询实时流。
3 在线数据集成
下载后可阅读完整内容,剩余3页未读,立即下载
2019-08-08 上传
2021-05-09 上传
2020-07-30 上传
2024-03-14 上传
2024-08-14 上传
2024-11-15 上传
2023-09-20 上传
2023-11-22 上传
2024-09-28 上传

weixin_38628429
- 粉丝: 7
- 资源: 913
 我的内容管理
展开
我的内容管理
展开







最新资源
- nashornexamples:Nashorn 应用程序和示例
- blog
- Qt使用鼠标钩子Hook(支持判断按下、弹起、滚轮方向)
- DIY制作——基于STM32F103RC的电子相册(原理图、PCB源文件、程序源码及制作)-电路方案
- phook - Pluggable run-time code injector-开源
- timeless
- 管理系统系列--医院信息管理系统.zip
- Uber:React Native,Typescrip和AWS Amplify上的Mobile&Web Uber App
- pf.github.io
- 【毕业设计(论文)】基于单片机STM32控制、Android显示的便携式数字示波器电路原理图、源代码和毕业论文-电路方案
- AgroShop
- project1:laravel前练习
- 1004DB
- launch-countdown-timer-css:这是我的前端向导解决方案-启动倒数计时器(挑战)
- 基于 Mini51 开发板应用实例(附高速ADC数字示波器、正弦信号发生器、等精度频率计等)-电路方案
- Symfony
