搭建Hadoop 2.6.0+Hbase 1.12+mahout 0.9 集群教程
"Hadoop 2.6.0+Hbase1.12+mahout0.9 集群搭建"
在大数据处理领域,Hadoop是一个开源的分布式计算框架,而HBase是一个基于Hadoop的分布式数据库,适用于大规模数据存储。Mahout则是一个机器学习库,用于构建数据挖掘和分析的算法。这篇摘要描述了如何在一个集群中安装和配置这些组件,特别是针对Hadoop 2.6.0、Hbase 1.12和Mahout 0.9的版本。
首先,为了构建一个集群,通常建议使用至少三台机器,这里提到可以配置一台然后克隆两台,以便于快速部署。每台机器的hostname需要根据实际需求进行配置,例如通过修改`/etc/hostname`。
接着,为了安全地管理用户权限,需要创建一个名为`hadoop`的用户组和同名的用户。在Ubuntu或类似Linux系统中,可以使用`sudo addgroup hadoop`创建用户组,然后使用`sudo adduser -ingroup hadoop hadoop`创建用户。为了使`hadoop`用户能够执行`sudo`命令,需要编辑`/etc/sudoers`文件,在`root ALL=(ALL) ALL`行下添加`ALL=(ALL:ALL) ALL`。
配置Java Development Kit (JDK)是必要的,因为Hadoop、HBase和Mahout都需要Java环境。这里假设已经下载了JDK 1.7.0_45,将其移动到`/home/hadoop/tools`目录,并设置相应的环境变量。在用户的`.bashrc`文件中,添加关于Hadoop路径的变量以及Java_HOME,这样每次登录时都会自动加载这些设置。
对于Hadoop的配置,需要设置HADOOP_PREFIX指向Hadoop安装目录,并添加相关路径到PATH变量中。同时,还需要配置Hadoop的其他环境变量,如HADOOP_COMMON_HOME、HADOOP_HDFS_HOME、HADOOP_MAPRED_HOME和HADOOP_YARN_HOME,确保它们都指向Hadoop的安装位置。
安装HBase时,将其解压缩并移动到适当的位置,然后同样需要配置环境变量。对于HBase,可能还需要配置`hbase-site.xml`以指定HBase的主节点(Master)和数据节点(RegionServer)。
至于Mahout,它依赖于Hadoop和Java环境,因此在安装Hadoop和配置好Java后,只需将Mahout的源码或预编译的二进制包放置在适当的目录,并设置相应的环境变量,如MAHOUT_HOME。
集群搭建完成后,还需要进行格式化NameNode、启动Hadoop服务、启动HBase服务等步骤。此外,还需要确保防火墙设置允许所有节点之间的通信,并且配置SSH无密码登录,以简化集群管理和任务调度。
在测试集群功能时,可以运行一些基本的Hadoop MapReduce作业和HBase操作,以验证集群是否正确配置和运行。对于Mahout,可以尝试训练和应用一些简单的推荐系统模型,以检查其工作是否正常。
搭建这样的集群涉及多个步骤,包括操作系统级别的用户和权限管理、软件安装、环境变量配置、集群配置文件的调整,以及最后的服务启动和测试。这是一个复杂但关键的过程,对于任何想要利用Hadoop、HBase和Mahout处理大规模数据的组织来说都是必不可少的。
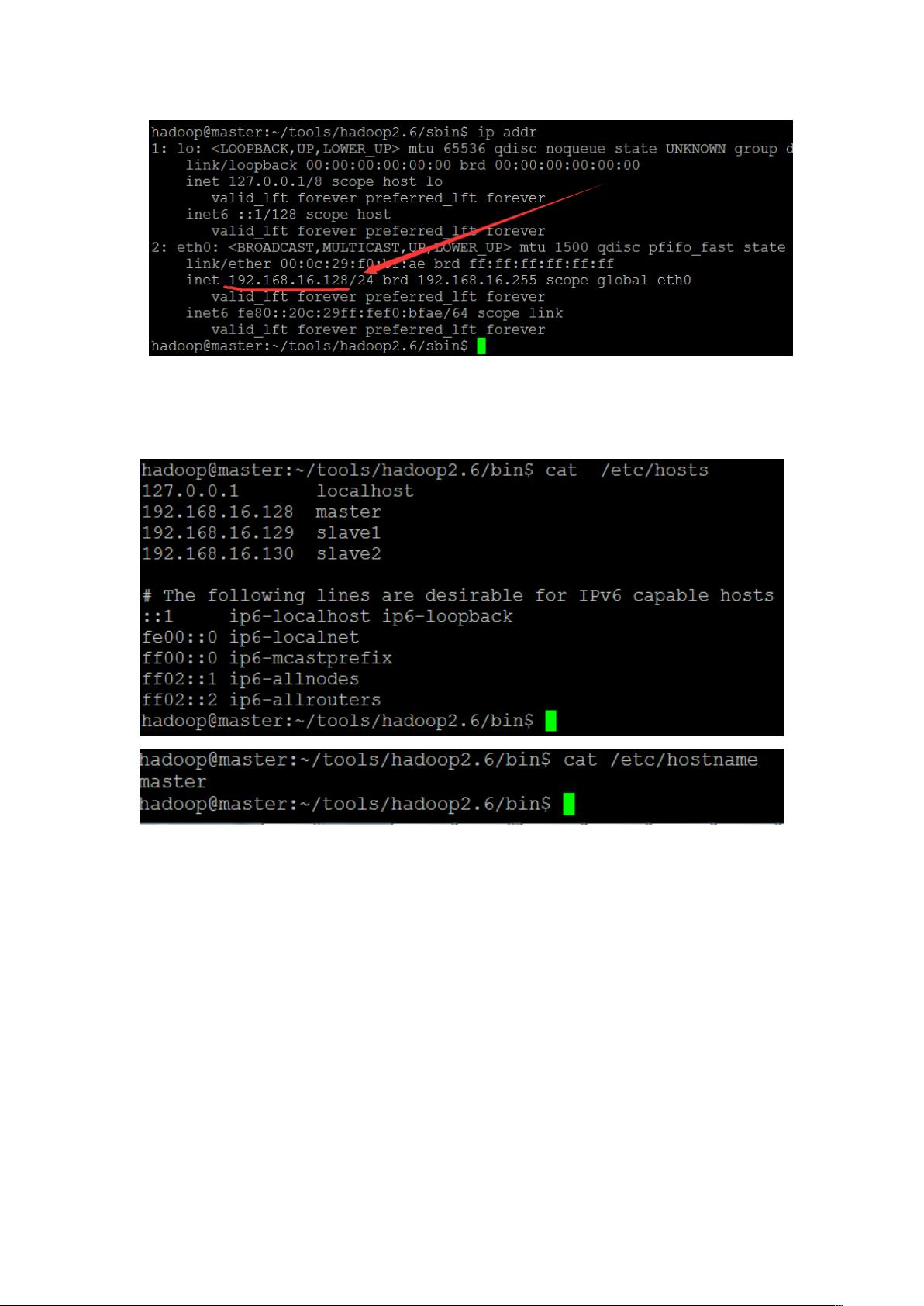
在三台主机上分别设置:/etc/hosts 和/etc/hostname
hosts 这个文件用于定义主机名和 IP 地址之间的映射关系。
(修改 hostname 后重启虚拟机生效)
4.关闭防火墙
sudo ufw disable (关闭防火墙重启虚拟机生效)
5.换源
若出现 ssh 等软件无法安装,进行换源操作
1、首先备份 Ubuntu14.04 源列表
剩余16页未读,继续阅读
2015-02-04 上传
2018-11-10 上传
2021-05-18 上传
2019-08-13 上传
2014-08-21 上传
2024-04-13 上传

deywós
- 粉丝: 216
- 资源: 68
 我的内容管理
展开
我的内容管理
展开







