PyTorch显存优化策略:Inplace与减少中间结果
需积分: 0 96 浏览量
更新于2024-08-05
收藏 1.19MB PDF 举报
PyTorch是一种广泛使用的深度学习框架,其在处理大型神经网络时可能会遇到显存限制问题。本文主要关注在不降低输入图像尺寸或减小BatchSize的前提下,通过优化网络模型和计算过程来节约显存的技术。
首先,网络模型本身占据了大部分显存。卷积层、全连接层以及批量归一化(BN)层中的参数是显存的主要消耗者。这些层的权重和激活都需要存储在内存中。相反,诸如ReLU激活函数、池化层和Dropout等非参数操作虽然对模型功能至关重要,但并不占用显存。
在模型计算过程中,显存开销还包括优化器的状态(如梯度累积),以及中间计算结果。例如,特征图在前向传播和反向传播过程中会被生成,这些临时数据会占用显存。此外,反向传播过程中产生的梯度更新也会消耗一部分显存。
PyTorch提供了Inplace操作作为一种节省内存的方法。Inplace操作允许在原地修改张量的值,而不是创建新的副本,从而减少内存分配。大部分PyTorch内置函数(如tensor.add_()、tensor.scatter_())和一些运算符(如+=、*=)支持Inplace操作,使用这些特性可以显著降低内存占用。然而,必须确保在使用Inplace操作时梯度计算正确无误,因为错误的使用可能导致意外结果。
其次,避免不必要的中间结果生成也对显存优化至关重要。在编写代码时,应尽可能减少张量的复制和不必要的计算。例如,通过使用Python的赋值语句(如x += y)而不是创建新张量(如x = x + y)可以减少内存占用。
在实际应用中,开发者还可以考虑使用更轻量级的数据结构,比如量化(quantization)、低秩分解(low-rank factorization)或剪枝技术来减少模型的参数数量。另外,动态图模式(Eager Execution)相比于编译模式(Graph Execution)可能更节省内存,因为它允许在运行时决定哪些部分不保存计算图。
总结来说,节约PyTorch显存的关键在于理解哪些部分消耗最大,并针对性地采取措施。通过利用Inplace操作、避免不必要的中间结果、选择适当的模型架构和数据处理方式,可以在保证模型性能的同时,有效地管理GPU的显存。在实践中,持续监控和调整这些优化策略将有助于在有限的资源内实现高效的深度学习训练。
引
⾔
Out Of Memory,
⼀个
炼
丹
师
们
熟
悉
得
不
能
再
熟
悉
的
异
常
,
其
解
决
⽅
法
也
很
简
单
,
减
少
输
⼊
图
像
的
尺⼨
或
者
Batch Size
就
好
了
。
但
是
,
且不
说
输
⼊
尺⼨对
模
型
精
度
的
影
响
,
当
BatchSize
过
⼩
的
时
候
⽹
络
甚
⾄
⽆
法
收敛
的
。
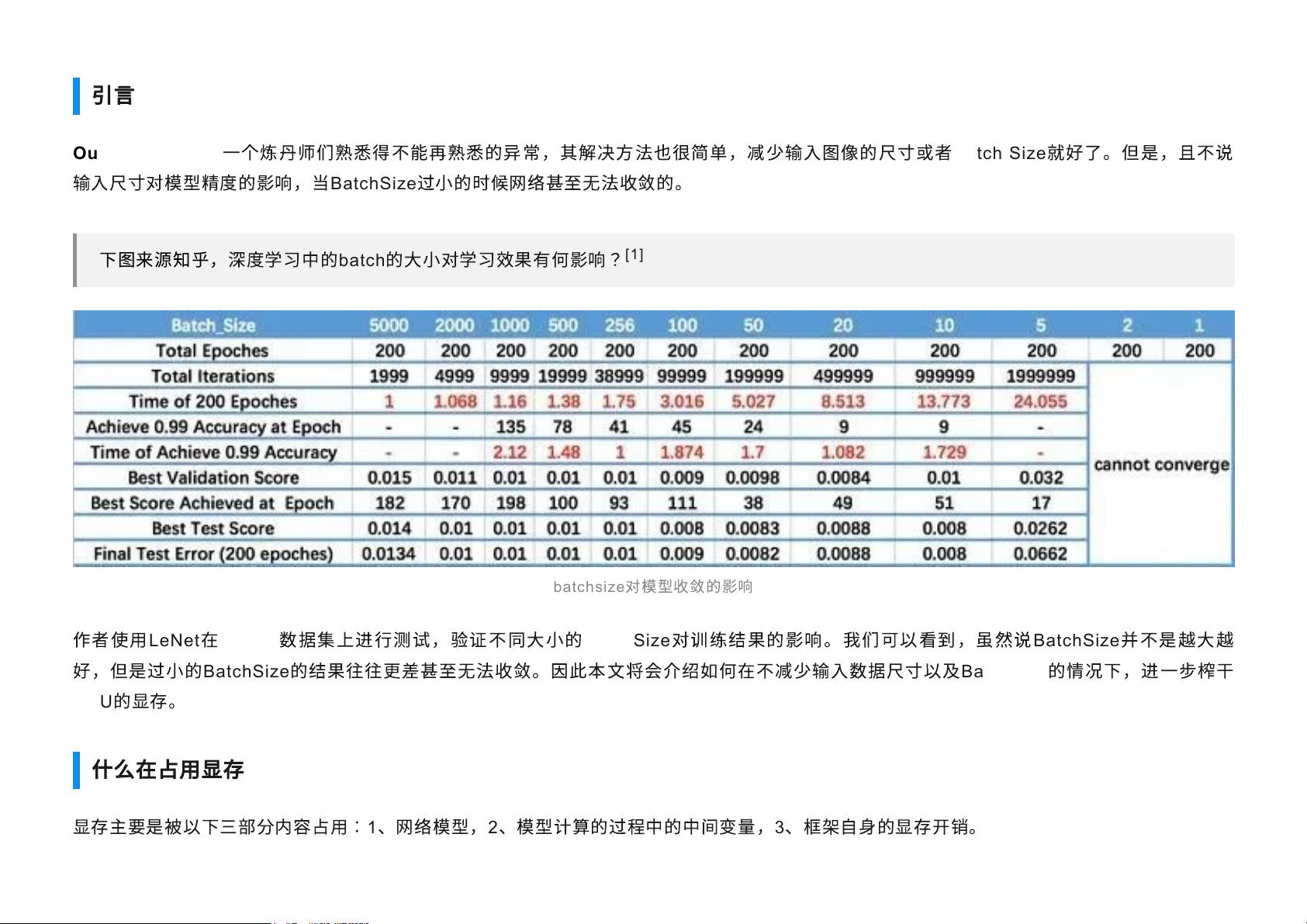
下
图
来
源
知
乎
,
深
度
学
习中
的
batch
的
⼤
⼩对
学
习
效
果
有
何
影
响
?
[1]
batchsize
对
模
型
收敛
的
影
响
作
者
使
⽤
LeNet
在
MNIST
数
据
集
上
进
⾏
测
试
,
验
证
不
同
⼤
⼩
的
BatchSize
对
训
练结
果
的
影
响
。
我
们
可
以
看
到
,
虽
然
说
BatchSize
并
不
是
越
⼤
越
好
,
但
是
过
⼩
的
BatchSize
的
结
果
往往
更
差
甚
⾄
⽆
法
收敛
。
因
此
本
⽂
将
会介
绍
如
何
在
不
减
少
输
⼊
数
据
尺⼨
以
及
BatchSize
的
情
况
下
,
进
⼀
步
榨
⼲
GPU
的
显
存
。
什
么
在
占
⽤
显
存
显
存
主
要
是
被
以
下三
部
分
内
容
占
⽤
:
1
、
⽹
络
模
型
,
2
、
模
型
计
算
的
过
程
中
的
中
间
变
量
,
3
、
框
架
⾃
⾝
的
显
存
开
销
。
下载后可阅读完整内容,剩余7页未读,立即下载
2024-07-02 上传
2020-12-23 上传
2021-05-28 上传
2020-09-18 上传
2020-12-23 上传
2021-05-28 上传
2021-04-13 上传
2020-07-11 上传
2024-04-20 上传

牛站长
- 粉丝: 31
- 资源: 299
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
