Apache Kafka:分布式日志系统与消息中间件解析
需积分: 5 52 浏览量
更新于2024-07-15
收藏 4.35MB PDF 举报
"Kafka学习笔记.pdf"
Kafka是一个由LinkedIn最初开发的分布式消息系统,后来成为Apache基金会的顶级开源项目。它是一个分布式、分区、多副本的日志系统,同时也可作为消息中间件使用,主要用于日志收集和消息服务。Kafka的核心设计目标包括高效的消息持久化、高吞吐量、保持partition内消息顺序、支持离线和实时数据处理以及在线水平扩展。
1. **消息系统基础**
- **消息传递模式**:消息系统负责在应用间传递数据,提供异步通信。Kafka采用发布-订阅模式,不同于点对点模式,其中消息会被多个消费者消费,而点对点模式下消息只被一个消费者消费一次。
2. **Kafka的特点**
- **解耦**:Kafka通过中间消息层使得生产者和消费者之间不需要直接交互,降低了系统间的耦合度,允许系统独立扩展。
- **容错性**:通过多副本机制,Kafka能够在节点故障时自动切换,确保服务连续性。
- **高性能**:O(1)的消息持久化和高吞吐率使其在大数据处理场景中表现出色。
- **消息顺序保证**:每个partition内的消息按顺序存储和消费,确保特定业务场景下的数据一致性。
- **可扩展性**:Kafka集群可以通过添加更多服务器进行水平扩展,以应对更大的负载。
3. **发布-订阅模式**
- 在这种模式下,消息被发送到特定的主题(topic),订阅了该主题的消费者可以接收到消息。这允许一个消息可以被多个订阅者消费,提高了数据复用性。
4. **Kafka的使用场景**
- **日志收集**:Kafka可以高效地收集和分发来自各种源的日志数据,如web服务器日志、应用程序日志等。
- **流处理**:Kafka结合Spark Streaming或Flink等工具,实现数据的实时处理和分析。
- **事件驱动架构**:Kafka作为事件总线,连接各个系统,使得系统之间的通信更加灵活。
5. **Kafka组件**
- **Producer**:生产者负责发布消息到特定的主题。
- **Broker**:Kafka服务器,存储和转发消息。
- **Consumer**:消费者订阅主题,处理消息。
- **Zookeeper**:协调Kafka集群,管理元数据和集群状态。
6. **Kafka的消费者组**
- 消费者通过加入消费者组来共享主题中的消息,每个分区只能被组内的一个消费者消费,确保无重复处理。
7. **Kafka的数据保留策略**
- Kafka可以根据时间或大小设置数据保留策略,超出范围的数据将被自动删除。
8. **Kafka的API**
- Kafka提供了Java、Scala和C++等多种语言的API,方便不同平台和语言的应用集成。
Kafka的这些特性使其在大数据、实时处理和微服务架构中广泛应用,为系统提供了高效、可靠的实时数据流转能力。
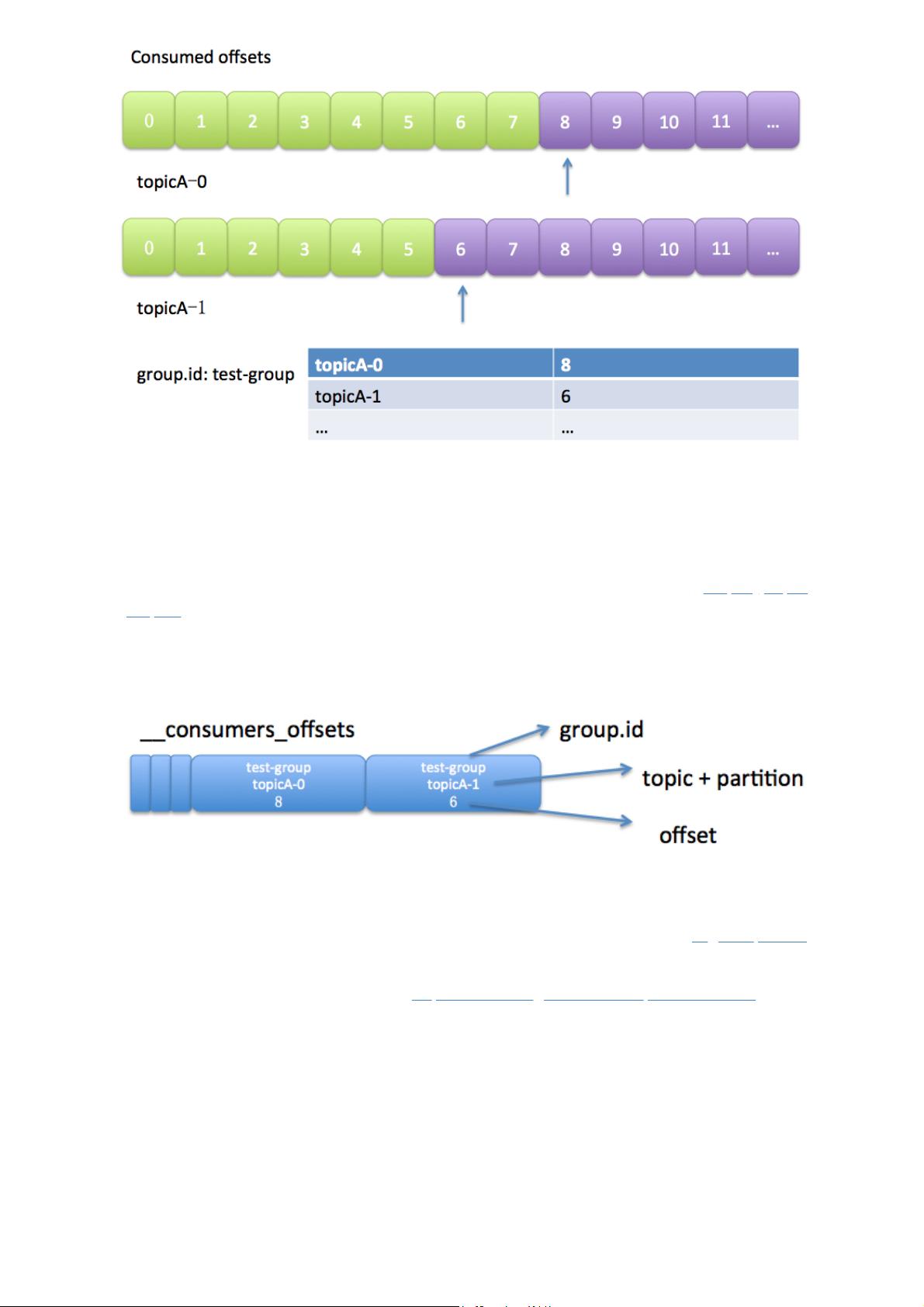
上图中表明了test-group这个组当前的消费情况。
3.2 位移提交
老版本的位移是提交到zookeeper中的,图就不画了,总之目录结构是:/consumers/[group.id](http://
group.id/)/offsets//,但是zookeeper其实并不适合进行大批量的读写操作,尤其是写操作。因此kafka
提供了另一种解决方案:增加consumeroffsets topic,将offset信息写入这个topic,摆脱对
zookeeper的依赖(指保存offset这件事情)。consumer_offsets中的消息保存了每个consumer group
某一时刻提交的offset信息。依然以上图中的consumer group为例,格式大概如下:
__consumers_offsets topic配置了compact策略,使得它总是能够保存最新的位移信息,既控制了该
topic总体的日志容量,也能实现保存最新offset的目的。compact的具体原理请参见:Log Compaction
至于每个group保存到consumers_offsets的哪个分区,如何查看的问题请参见这篇文章:[Kafka 如何
读取offset topic内容 (consumer_offsets)](http://www.cnblogs.com/huxi2b/p/6061110.html)
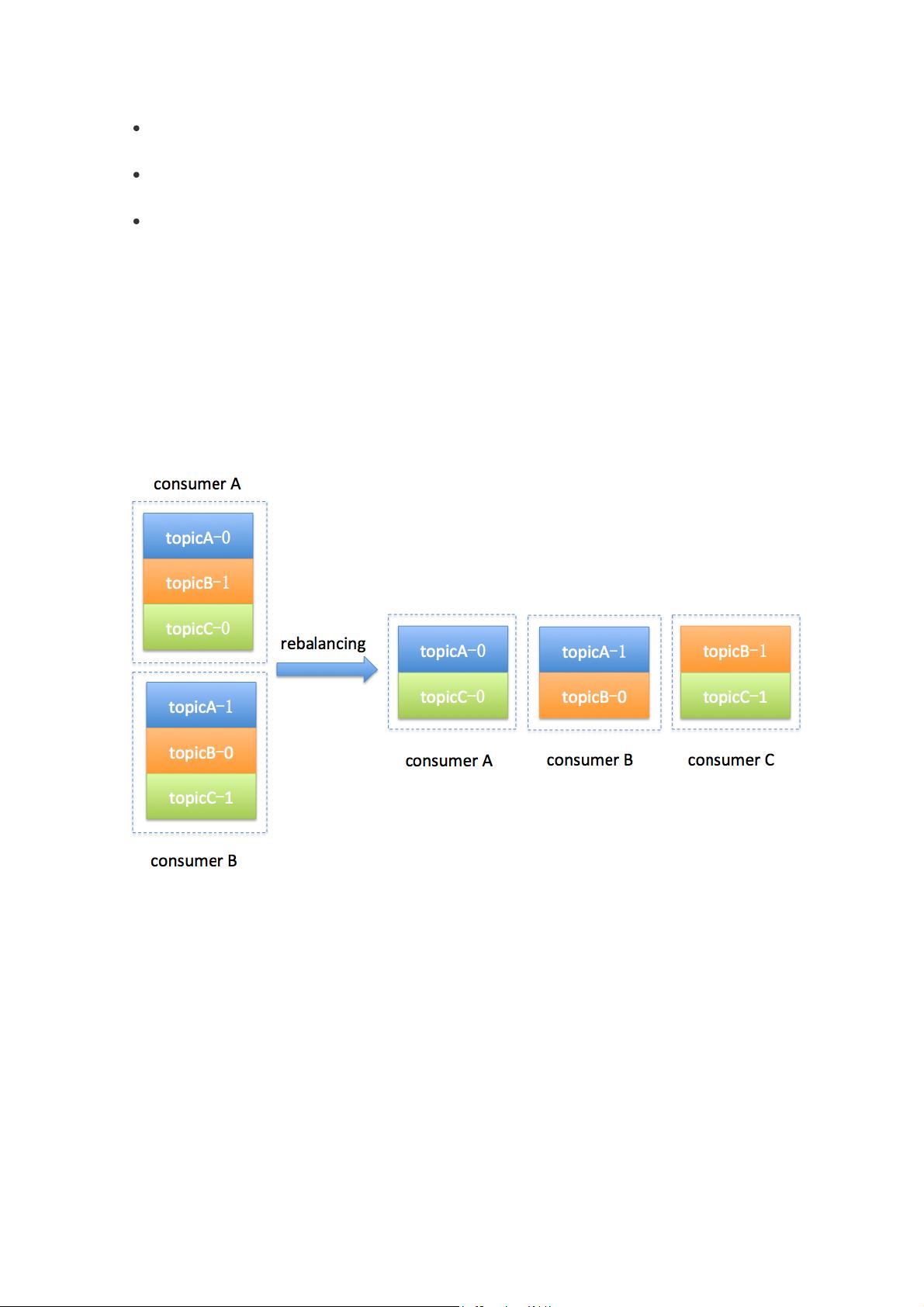
4 Rebalance
4.1 什么是rebalance?
rebalance本质上是一种协议,规定了一个consumer group下的所有consumer如何达成一致来分配订
阅topic的每个分区。比如某个group下有20个consumer,它订阅了一个具有100个分区的topic。正常
情况下,Kafka平均会为每个consumer分配5个分区。这个分配的过程就叫rebalance。
剩余37页未读,继续阅读
2024-03-21 上传
2023-06-06 上传
2021-08-17 上传
2020-06-28 上传
2021-09-14 上传
2016-11-03 上传

YMY6666
- 粉丝: 10
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- pomodoro-backbone:解决
- 响应卡:带有HTMLCSS的响应卡
- nest-serve:nest.js 开发的管理后台服务接口
- Python库 | gudhi-3.4.1-cp39-cp39-manylinux2014_x86_64.whl
- 材质101:做与不做-项目开发
- 飞机大战-Python-黑马项目演练.zip
- node-module-context
- 002-英语语法word版.rar
- python实现屏幕录制,可以当做录屏小工具
- i18n-browserify:i18n作为浏览器转换的示例
- coursera-test:coursera存储库
- atcrowdfundingNew
- grunt-sass-demo
- 401reading:https:salehmmasri.github.io401reading
- CsSelfstudy:做一个更好的人
- Parallel Toolbox-开源
