多视图深度学习描述子提升点云配准精度
153 浏览量
更新于2024-06-20
收藏 4.3MB PDF 举报
本文主要探讨了多视图描述子在点云配准中的重要应用。点云配准是3D数据处理中的核心任务,它旨在将来自不同视角或来源的3D数据融合到一个统一的坐标系统中,这对于诸如3D建模、SLAM(Simultaneous Localization And Mapping,同时定位与地图构建)以及机器人感知等领域至关重要。在解决点云配准中的关键对应性问题时,研究者们通常采用两种策略:一是设计3D局部描述符,以增强3D关键点的特征表达能力;二是开发鲁棒的匹配算法,以确保在存在噪声和不匹配的情况下仍能准确匹配。
本文贡献了一种创新的方法,首先提出了一种多视图局部描述符,这种描述符是通过对多个视角的图像进行学习而得到的,特别适合用来描述3D关键点。这种设计借鉴了2D CNN(Convolutional Neural Networks,卷积神经网络)在2D投影上的成功经验,强调了利用二维投影进行几何特征提取的重要性,同时结合了3D几何的局部信息。
其次,作者开发了一种强大的匹配策略,采用了基于信念传播的图形模型,该模型能够在排除离群匹配的基础上进行有效的推理。这种方法的目标是提高配准的准确性和鲁棒性,即使在数据集中存在噪声和复杂情况,也能有效地找到对应关系。
作者通过实证研究,展示了他们的方法在公共扫描和多视图立体数据集上的显著优势,通过与多种描述符和匹配算法的密集比较,验证了其优越的性能。因此,本文的工作不仅提升了点云配准的精度,还为3D关键点的描述和匹配提供了新的视角,对于推进点云处理技术的发展具有重要意义。
关键词:点云配准、3D描述符、鲁棒匹配、多视图描述子、3D关键点、信念传播、图形模型。
L. Zhou,S. Zhu,Z. Luo
等
人
4
……
Conv6
康卡特
康卡特
……
多个视图中的要素
地图
……
……
©
融合
查看池化
Conv7
Conv5-1
Conv5-2
Conv5-3
层
内核通道跨步激活
Conv5-1
3×3
32
1
ReLU
Conv5-2
1×3
32
1
ReLU
Conv5-3
3×1
32
1
ReLU
Conv6
1×1
-
1
ReLU
Conv7
3×3
-
2
-
(a)
融合
-ResNet
(
b
)融合
(
c
)参数
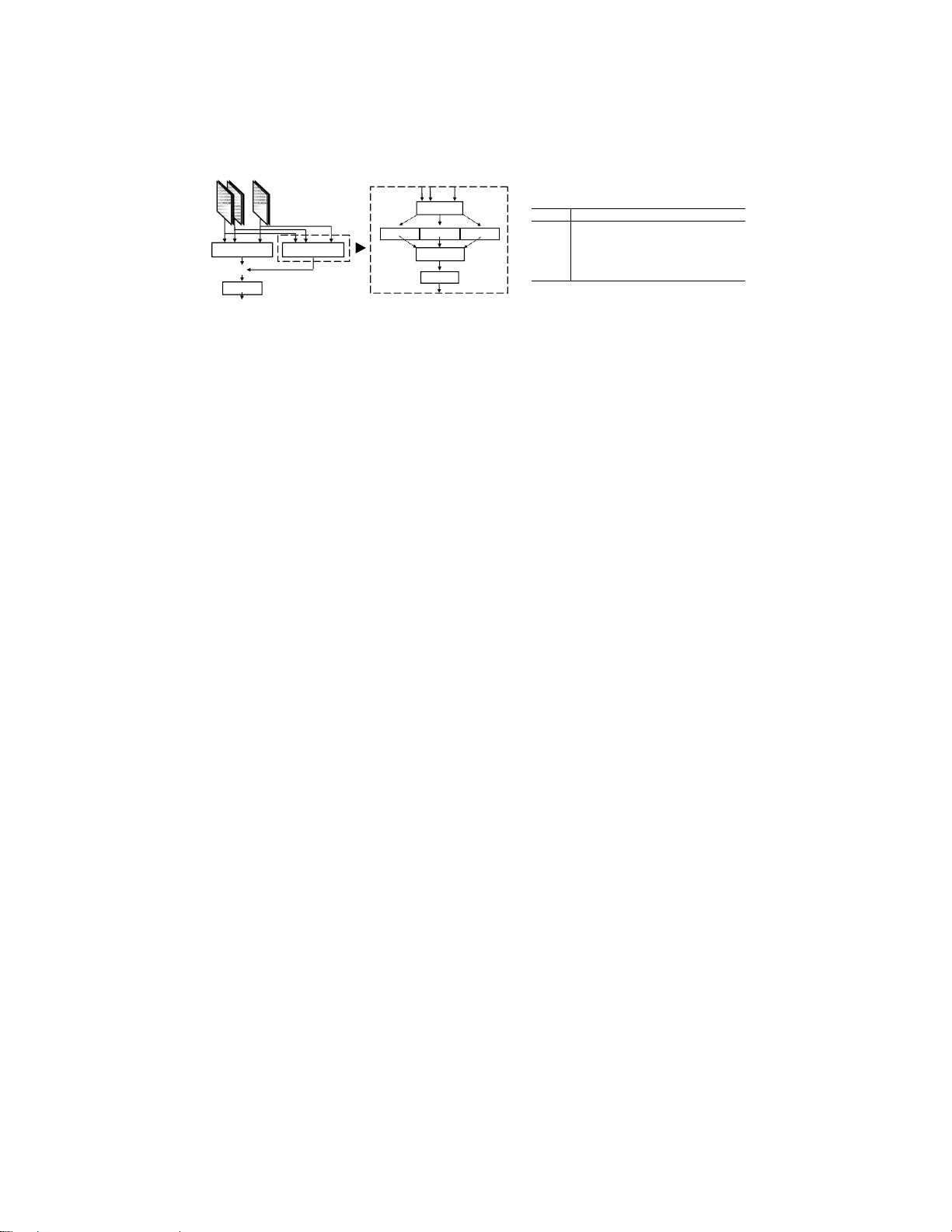
图1:所提出的融合-ResNet(FRN)的概述。(a)融合多视图特征图的FRN
架构。由视图池化分支作为快捷连接支持,(b)融合分支负责学习残差
映射。(c)列出了卷积层的参数
池化作为快捷连接,并添加了一个名为
Fuseption
的兄弟分支,负责学
习底层的残差映射。
融合如图1(b)所示,Fuseption是一个Inception风格的[49,50]架构,
覆盖在多视图特征图之上。首先,遵循inception模块的结构[49,50],
采用具有不同内核大小的三个轻量级交叉空间滤波器,3×3,1×3和
3×1,以提取不同类型的特征。其次,在连接的特征图上使用的1×1卷
积Conv6负责合并通道间的相关统计和降维,如[ 49,51]所建议的。
融合-ResNet(FRN)。灵感来自于跳过连接的有效性 在ResNet [48]
中,除了Fuseption,我们还将视图池作为一种快捷方式 如图1(a)
所示。与负责跨视图提取最强响应的视图池分支相反[31],融合分支
负责学习底层残差映射。两个接合的分支在准确性和收敛速度方面相
互加强。一方面,与仅使用视图池相比,残差分支Fuseption不会保证
更差的准确性。这是因为如果视图池化是最佳的,则残差可以在训练
期间容易地被拉到零。另一方面,快捷分支视图池极大地加速了学习
MVDesc的收敛直观地,由于视图池化分支已经提取了跨视图的基本
最强响应,因此融合分支更容易仅学习残差映射。
3.2
学习MVDesc
网络通过将所提出的FRN置于多个并行特征网络之上来构建用于学习
MVDesc的网络。我们使用MatchNet [45]的特征网络作为基础,其中去
除了瓶颈层和度量网络多个视图的特征网络共享对应卷积层的相同参
数Conv6的通道号设置为
剩余17页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-10-29 上传
2024-05-04 上传
2021-06-03 上传
2022-08-03 上传
点击了解资源详情
2024-10-29 上传

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
