半监督学习对抗微博水军:Affinity Propagation算法应用
版权申诉
9 浏览量
更新于2024-07-03
收藏 589KB DOCX 举报
"基于Affinity Propagation算法的半监督微博水军识别"
本文探讨了如何利用Affinity Propagation(亲和传播)算法进行半监督学习,以识别微博中的水军账号。随着社交媒体的普及,微博数据的影响力日益增大,数据的真实性和准确性对网络环境和社会稳定至关重要。然而,网络水军的存在严重影响了这一目标,他们通过操纵信息,可能引发负面舆论,破坏网络秩序。
在有监督学习方法中,研究者通过设置多种特征,如粉丝关注比、发博数等,利用贝叶斯模型、遗传算法和决策树等算法提高水军识别的准确率。然而,这类方法依赖大量标注数据,而水军的标注工作既困难又昂贵。
无监督学习则尝试通过聚类和网络结构分析来检测水军,例如GAO等人利用文本相似性和URL聚类,QU等人借助网络表示学习和GCN算法。尽管这种方法无需标注数据,但其准确性和效率相对较弱。
半监督学习是介于有监督和无监督之间的一种方法,它能利用少量标注数据来训练模型,并从大量未标注数据中学习。文中提到的LI等人采用了Tri-Training模型,结合水军的动态行为特征,以增量学习的方式处理无标注数据,从而更有效地识别水军。
亲和传播算法是一种非中心化的聚类算法,不同于K-means等需要预先设定簇的数量,它能自适应地找到数据的最佳簇结构。在水军识别中,该算法可以基于用户间的交互和行为模式,自动识别出具有水军特征的群体,这对于处理大规模、未完全标注的微博数据尤其有用。
在实际应用中,Affinity Propagation通过计算数据点之间的相似度,形成传播过程,最终找到能够代表整个数据集的“样本”,即所谓的“解释簇”(exemplars)。这些解释簇可以被视为潜在的水军账号,从而帮助过滤和消除虚假信息的影响。
总结来说,文章研究了基于Affinity Propagation算法的半监督学习方法在微博水军识别中的应用,试图解决有监督学习的标注难题和无监督学习的准确性问题,提供了一种更为灵活和有效的解决方案。通过深入理解用户的行为模式和网络结构,该方法有助于维护网络空间的健康秩序,防止水军对公众舆论的不当影响。
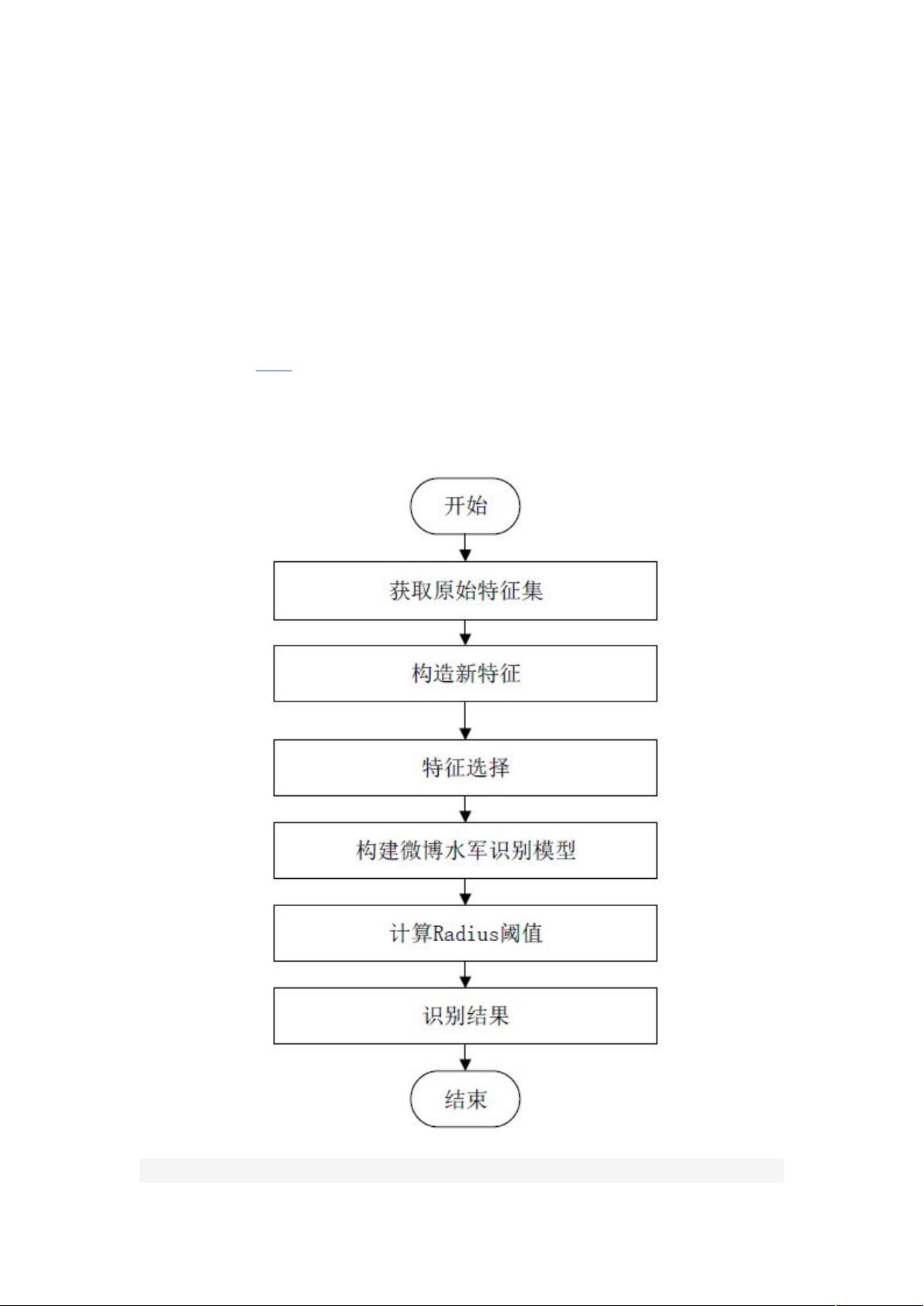
法,而现有的机器学习方法在面对多类别水军时,无法较好地在保证高精确率和高
召回率的同时解决水军标注困难的问题。
结合微博水军定义给出一个能准确反映水军之间的相似性和水军与正常用
户之间的差异性的特征集,引入 Affinity Propagation 聚类算法,通过刻画用户与
用户之间的相似性,结合同一类别水军高度相似的特点和 Affinity Propagation 聚
类算法无需选择固定质心的特点,解决对多类别水军的适应性问题,再通过引入一
个合适的欧氏距离阈值 Radius,将阈值内所有未标注账户标注为其所属质心的标
签,从而解决标注困难问题。再将扩充后的标注集通过支持向量机算法进行分类
模型训练,从而实现在保证高精确率和高召回率的同时解决多类别水军标注困难
问题,其流程如图
1
所示。
图 1
图 1水军识别方法流程
剩余18页未读,继续阅读
146 浏览量
2023-03-11 上传
2022-07-03 上传
2022-10-26 上传
2022-07-06 上传
2023-03-11 上传
2019-08-24 上传
2023-03-03 上传

罗伯特之技术屋
- 粉丝: 4461
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- WordPress作为新闻管理面板的实现指南
- NPC_Generator:使用Ruby打造的游戏角色生成器
- MATLAB实现变邻域搜索算法源码解析
- 探索C++并行编程:使用INTEL TBB的项目实践
- 玫枫跟打器:网页版五笔打字工具,提升macOS打字效率
- 萨尔塔·阿萨尔·希塔斯:SATINDER项目解析
- 掌握变邻域搜索算法:MATLAB代码实践
- saaraansh: 简化法律文档,打破语言障碍的智能应用
- 探索牛角交友盲盒系统:PHP开源交友平台的新选择
- 探索Nullfactory-SSRSExtensions: 强化SQL Server报告服务
- Lotide:一套JavaScript实用工具库的深度解析
- 利用Aurelia 2脚手架搭建新项目的快速指南
- 变邻域搜索算法Matlab实现教程
- 实战指南:构建高效ES+Redis+MySQL架构解决方案
- GitHub Pages入门模板快速启动指南
- NeonClock遗产版:包名更迭与应用更新
