Hive入门:函数详解与数据操作指南
需积分: 12 173 浏览量
更新于2024-07-18
收藏 442KB DOCX 举报
Hive入门教程深入解析
在Hive的世界里,掌握基础知识至关重要。Hive是Apache Hadoop的数据仓库工具,它允许用户通过SQL查询大规模数据存储系统。本篇文章旨在介绍Hive的核心概念、语法和常用函数,帮助读者快速上手。
首先,让我们了解一下Hive的层次结构。当你连接到Hive服务器(例如通过网关机172.16.213.223),通过Hive CLI命令行工具,你可以轻松地管理Hive数据库和表。通过`show databases`命令查看所有可用的数据库,然后使用`use database_name`切换到特定业务数据库。
在数据库中,查看表是数据操作的基础。使用`show tables`命令获取当前数据库中的所有表,而`desc [table_name]`和`desc formatted [table_name]`则分别用于查看表的基本信息(字段、分区)和更详细的元数据(如路径、格式等)。Hive支持多种数据类型,包括整型(TINYINT、SMALLINT、INT、BIGINT)、布尔型(BOOLEAN)、浮点型(FLOAT、DOUBLE)和字符型(STRING)。
内部表和外部表是Hive中两种主要的表类型。内部表在删除时会同步删除Hadoop上的数据,适合用作中间表或结果表,无需频繁从外部加载数据。创建内部表的语法示例是:
```sql
CREATE TABLE tab (
column1 STRING,
column2 STRING,
column3 STRING,
column4 STRING,
columnN STRING
);
```
相比之下,外部表用于存储外部数据源(如本地文件或HDFS)的数据,删除不会影响底层数据。创建外部表的语法包含额外的`ROWFORMAT`和`LOCATION`参数:
```sql
CREATE EXTERNAL TABLE tab (
column1 STRING,
column2 STRING,
column3 STRING,
column4 STRING,
columnN STRING
) ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE
LOCATION 'hdfs://namenode/tmp/liuxiaowen/tab/';
```
分区功能在Hive中扮演着重要角色,尤其当数据量巨大且需要按时间或其他属性进行细粒度查询时。分区表通过`CREATE TABLE`语句指定,例如按日期创建每日分区:
```sql
CREATE TABLE tab (
column1 STRING,
...
partition (date STRING)
) ...
PARTITIONED BY (date STRING);
```
理解这些基础概念和语法后,Hive函数大全就显得尤为重要。Hive提供了丰富的内置函数,用于数据处理、转换和分析。这些函数涵盖了数学运算、字符串操作、日期时间处理等多个领域。熟练运用这些函数可以极大地提高数据分析的效率。
总结来说,学习Hive入门首先需要熟悉其数据模型、表结构、数据类型以及基本操作。接着深入了解内部表和外部表的区别,学会如何创建和管理分区。最后,掌握Hive函数的使用,能够根据具体需求进行高效的数据查询和处理。随着实践的积累,你将逐步成长为Hive的专家。
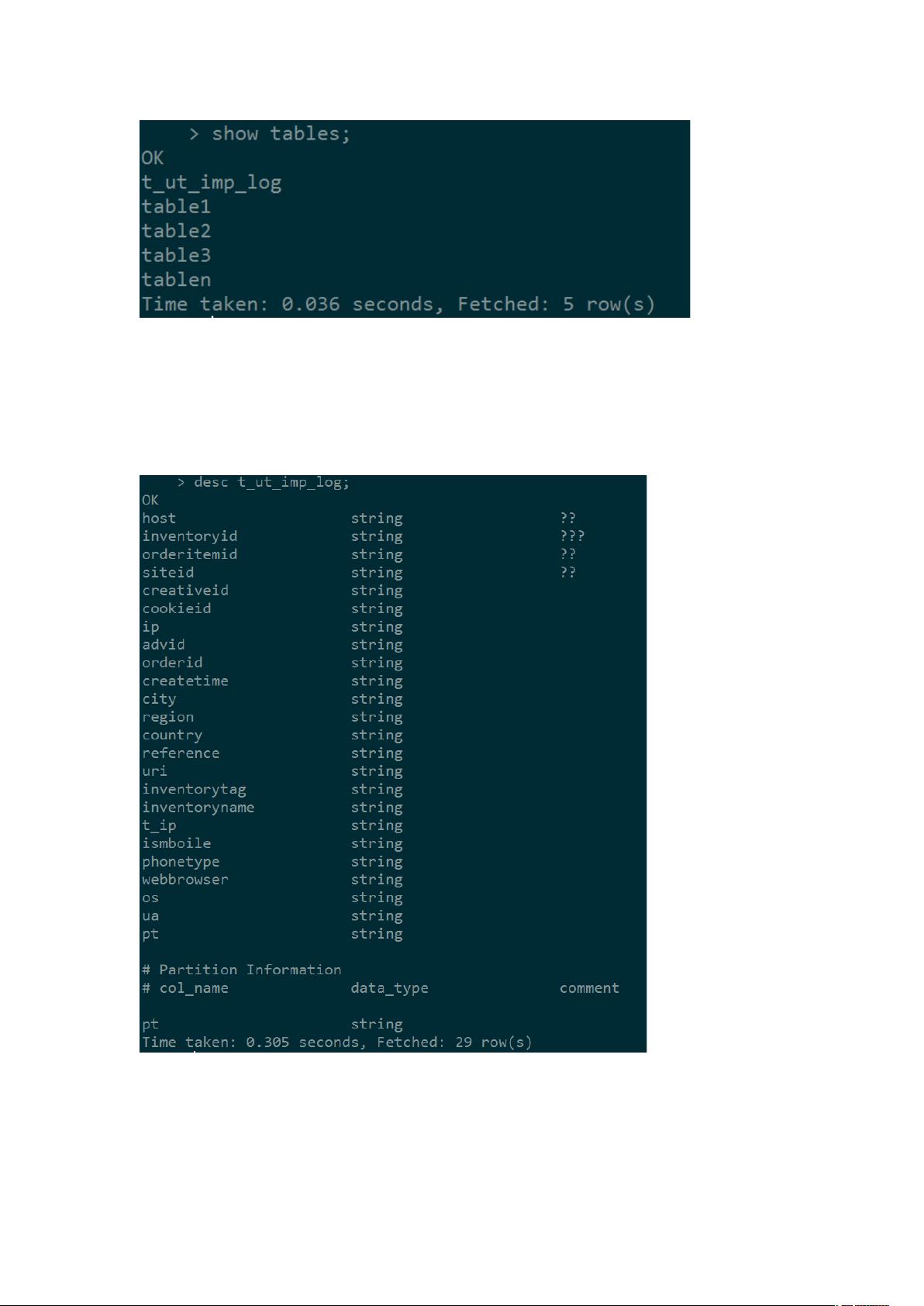
1.4 查看表结构
查看表的基础信息字段、分区
查看表的详细信息字段、分区、路径、格式等
剩余14页未读,继续阅读
2017-09-07 上传
2024-11-21 上传
2023-04-26 上传
2014-06-03 上传
2018-06-19 上传
2018-12-04 上传

听见下雨的声音hb
- 粉丝: 69
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
