提升方法的统计视角:加法逻辑回归
需积分: 10 70 浏览量
更新于2024-07-09
收藏 728KB PDF 举报
"Additive Logistic Regression - A Statistical View of Boosting"
这篇论文深入探讨了Boosting算法,特别是Adaboost算法,以及它在集成学习中的应用。Adaboost是一种强大的分类方法,通过序列化地对训练数据应用分类算法,并对产生的分类器进行加权多数投票来提升性能。该技术的核心在于其迭代过程,每次迭代都会重新调整数据点的权重,使得难以分类的数据点在后续的迭代中得到更多的关注。
论文的作者,Jerome Friedman、Trevor Hastie和Robert Tibshirani,都是统计学和机器学习领域的知名专家,他们来自斯坦福大学。他们揭示了Boosting背后的统计原理,将其与已知的统计概念——加性建模和最大似然估计联系起来。对于二分类问题,Boosting可以看作是在逻辑尺度上对加性模型的一种近似,使用最大伯努利似然作为优化标准。
作者进一步发展了更直接的近似方法,这些方法在实践中几乎能与Boosting得到相同的结果。对于多分类问题,他们基于多项式似然提出了直接的推广,展示了这种方法在性能上的优秀表现。这为理解和改进Boosting提供了一个统计学的视角,同时也为实际应用中的分类问题提供了理论支持。
Boosting算法的优越性在于它能够自动识别并强化弱学习器,将一系列弱分类器组合成一个强分类器。通过对每个迭代中分类错误的数据点给予更高的权重,Boosting能逐步提高整体模型的准确性。此外,由于每次迭代只关注那些之前分类错误的样本,这使得算法对噪声和异常值具有一定的鲁棒性。
在集成学习中,Adaboost和其他Boosting变体(如Gradient Boosting)已经成为解决分类和回归问题的标准工具。它们广泛应用于数据挖掘、计算机视觉、自然语言处理和生物信息学等领域,因为它们能够处理高维数据,对小样本和不平衡数据集表现出色,并且可以通过调整迭代次数和学习率等参数来控制模型复杂度,防止过拟合。
"Additive Logistic Regression - A Statistical View of Boosting"这篇论文为理解Boosting算法的内在机制提供了统计学的基础,同时也为实际应用中的优化和改进提供了指导。通过深入研究这些原理,数据科学家和机器学习工程师能够更好地利用Boosting来构建高效、准确的分类模型。

348 J. FRIEDMAN, T. HASTIE AND R. TIBSHIRANI
Note that after each Newton step, the weights change, and hence the tree
configuration will change as well. This adds an adaptive twist to the data
version of a Newton-like algorithm.
Parts of this derivation for AdaBoost can be found in Breiman (1997) and
Schapire and Singer (1998), but without making the connection to additive
logistic regression models.
Corollary 2. After each update to the weights, the weighted misclassifi-
cation error of the most recent weak learner is 50%.
Proof. This follows by noting that the c that minimizes JF +cf satisfies
∂JF + cf
∂c
=−Ee
−yFx+cfx
yfx = 0(21)
The result follows since yf x is 1 for a correct and −1 for an incorrect
classification. ✷
Schapire and Singer (1998) give the interpretation that the weights are
updated to make the new weighted problem maximally difficult for the next
weak learner.
The Discrete AdaBoost algorithm expects the tree or other “weak learner”
to deliver a classifier fx∈−1 1. Result 1 requires minor modifications to
accommodate fx∈R, as in the generalized AdaBoost algorithms [Freund
and Schapire (1996b), Schapire and Singer (1998)]; the estimate for c
m
differs.
Fixing f, we see that the minimizer of (20) must satisfy
E
w
yfxe
−cyfx
=0(22)
If f is not discrete, this equation has no closed-form solution for c, and requires
an iterative solution such as Newton–Raphson.
We now derive the Real AdaBoost algorithm, which uses weighted proba-
bility estimates to update the additive logistic model, rather than the classifi-
cations themselves. Again we derive the population updates and then apply it
to data by approximating conditional expectations by terminal-node averages
in trees.
Result 2. The Real AdaBoost algorithm fits an additive logistic regression
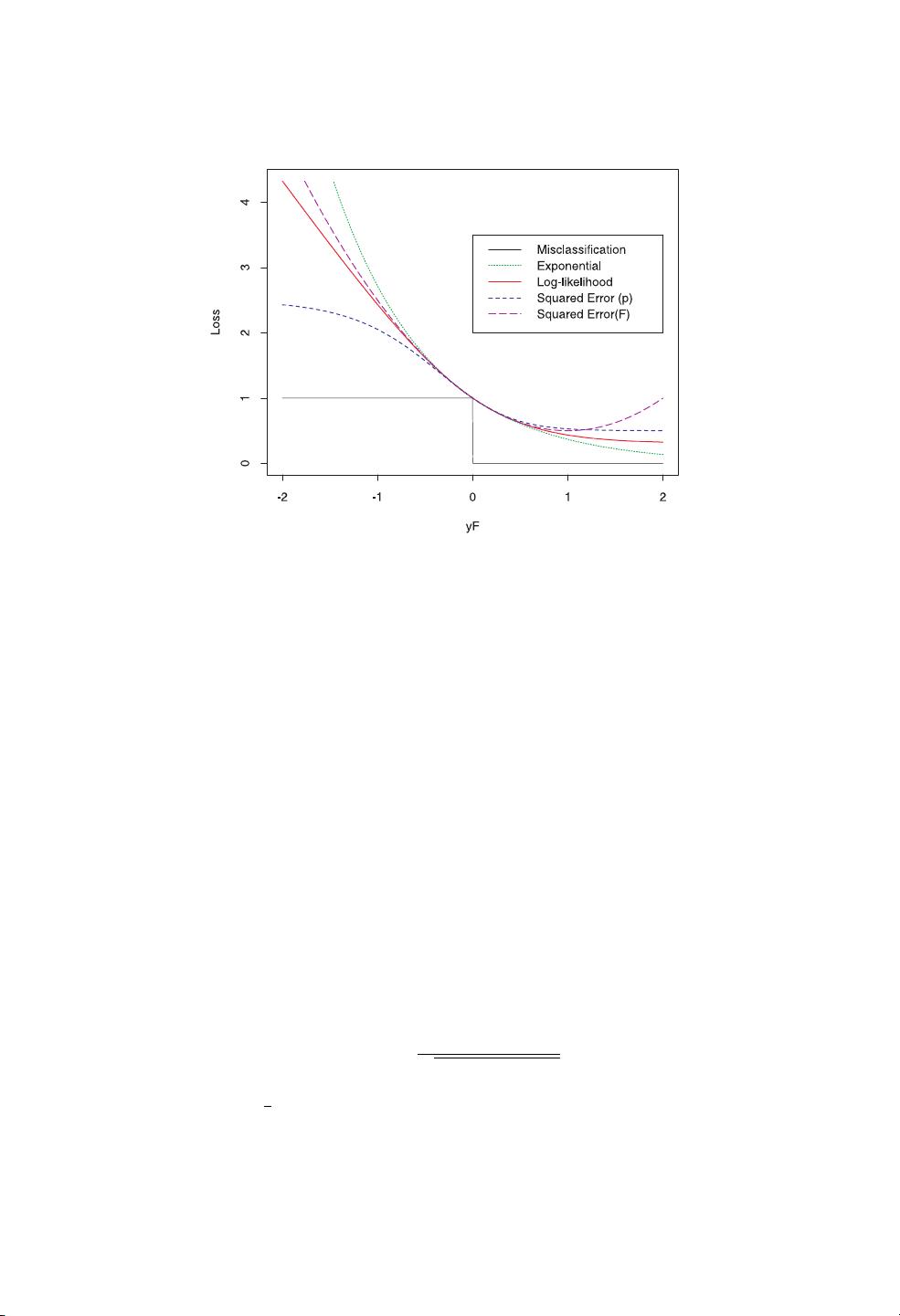
model by stagewise and approximate optimization of JF=Ee
−yFx
.
Proof. Suppose we have a current estimate Fxand seek an improved esti-
mate Fx+fx by minimizing JFx+fx at each x.
JFx+fx = Ee
−yFx
e
−yfx
x
= e
−fx
Ee
−yFx
1
y=1
x+e
fx
Ee
−yFx
1
y=−1
x
Dividing through by Ee
−yFx
x and setting the derivative w.r.t. fx to zero
we get
fx=
1
2
log
E
w
1
y=1
x
E
w
1
y=−1
x
(23)


剩余70页未读,继续阅读
2009-07-20 上传
2013-06-02 上传
2016-06-08 上传
2017-08-06 上传
123 浏览量
点击了解资源详情

小李玉
- 粉丝: 2
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- custom-radio-and-checbox-only-css:仅使用CSS自定义复选框和单选框
- 遥控潜艇-项目开发
- OxenTop.szwpkedo15.gaAXJiD
- movie-app2:React电影应用程序的锻炼
- 易语言卡拉OK系统源码-易语言
- CacheAmok.9v0s5hoplb.gaPQ1Db
- Data-Science
- terraform-gitcrypt:与terraform lite一起安装的git-crypt
- ekonsulta:医患在线咨询系统
- fSQ支持库1.0版(Sq.fne)-易语言
- QT软件工具使用.zip
- Aprendendo-Kotlin:紫杉醇
- cz-covid-19-score:聚醚砜
- blogPessoal-angular
- 数据库记录集分页显示源码-易语言
- retest:PHP正则表达式测试工具,封装PCRE函数,格式化输出,便于PHP正则表达式调试
