VMware HA深度解析:业务连续性与灾难恢复实践
需积分: 9 84 浏览量
更新于2024-08-02
收藏 1.32MB PDF 举报
"VMware Virtualization Forum 2009 的‘业务持续性和灾难恢复’分会场主要聚焦于VMware HA(High Availability)技术的解析和最佳实践,由VMware合作伙伴工程师刘长风和VMware高级工程师Gary Liu共同探讨。参会者可以通过点击‘2009VMware虚拟化论坛’标签获取更多大会内容。会议涵盖了VMware HA的基础概念、主机监控、故障切换策略、接纳控制、虚拟机健康监测和实施细节等方面,并深入讨论了一些高级议题。"
VMware HA是VMware ESX/ESXi平台的一项关键功能,旨在提高虚拟化环境的可用性,通过自动检测和处理主机故障,确保业务连续性。以下是对会议内容的详细阐述:
1. **VMware HA概述**:VMware HA提供了一种机制,当物理主机出现故障时,能够自动将运行在其上的虚拟机迁移到集群内的其他健康主机上,以最小化停机时间。
2. **主机监控和故障切换**:主机通过管理网络定期交换检测信号,每秒一次。如果15秒内没有收到信号,系统将判定该主机出现故障。为了防止误报,还会执行主机ping操作。一旦发现故障,协调器主机将负责识别故障主机上的虚拟机并尝试在集群中的其他主机上重启它们,按照预留容量和虚拟机兼容性进行优先排序。
3. **接纳控制**:接纳控制确保在故障发生时,有足够的备用容量来启动故障虚拟机,避免过载健康主机。它监控集群的资源使用情况,避免在资源紧张时启动虚拟机。
4. **虚拟机运行状况监控**:VMware HA不仅关注主机的健康状态,还监视虚拟机的运行状况。如果虚拟机自身出现问题,HA可以触发相应的恢复策略。
5. **实施细节**:实施VMware HA涉及配置集群设置、设置适当的网络和存储,以及根据实际环境调整策略,如设置合适的故障检测时间和资源预留。
6. **最佳实践**:会议分享了如何优化HA配置,包括合理规划资源分配、配置适当的心跳检测间隔、使用Distributed Resource Scheduler (DRS)协同工作,以及在故障恢复策略中考虑数据保护和备份。
7. **高级议题**:可能涵盖更复杂的场景,如多层应用的故障恢复策略、跨数据中心的HA配置,以及与第三方工具的集成,以实现更全面的灾难恢复解决方案。
通过理解和掌握这些知识点,IT管理员可以更有效地利用VMware HA来增强其虚拟化环境的稳定性和灾难恢复能力,确保业务的连续运行。
版权所有 © 2009 VMware,Inc. 保留所有权利。此产品受美国和国际版权及知识产权法保护。VMware 产品拥有 http://www.vmware.com/go/patents 中列出的一项或多项专利。
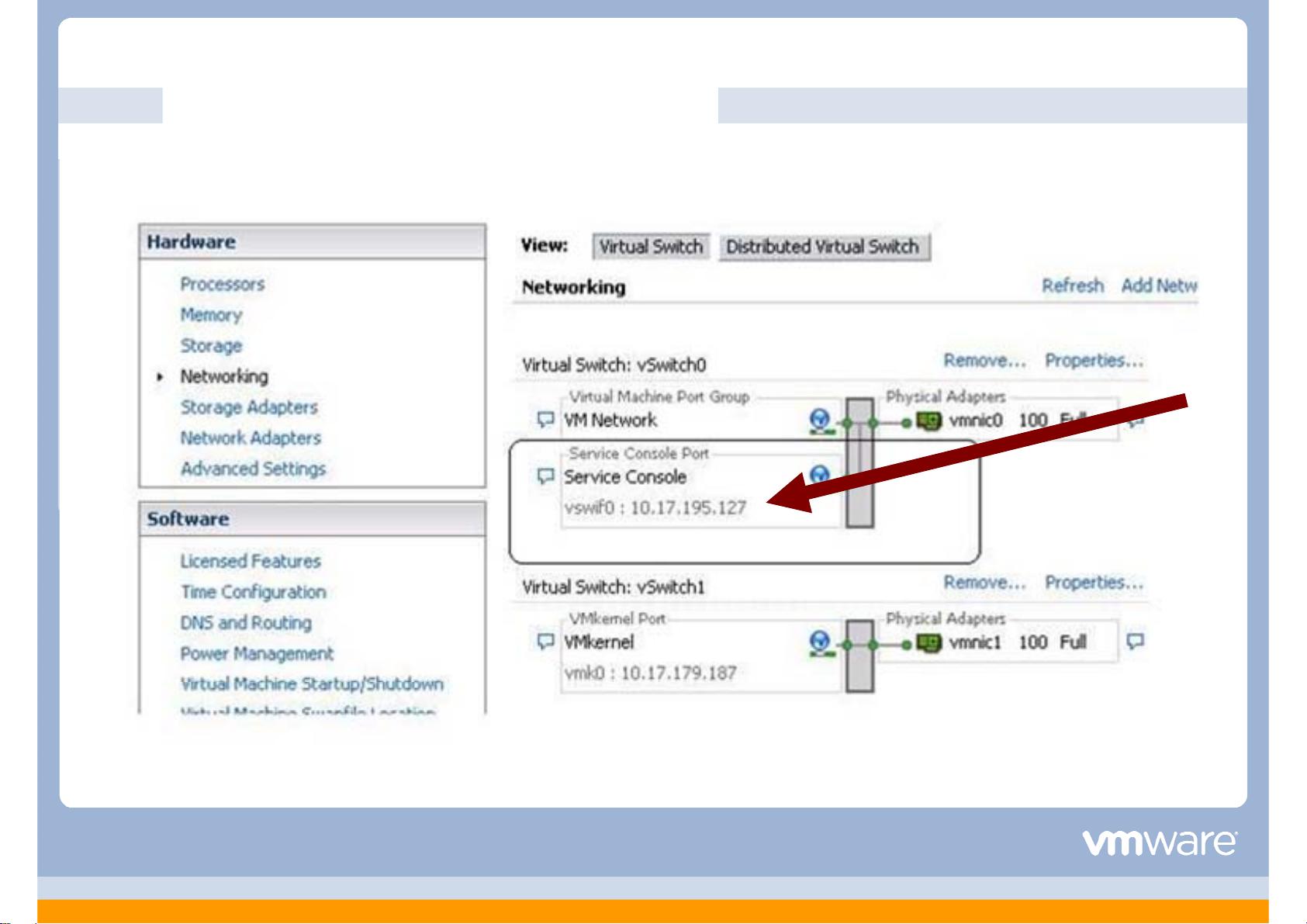
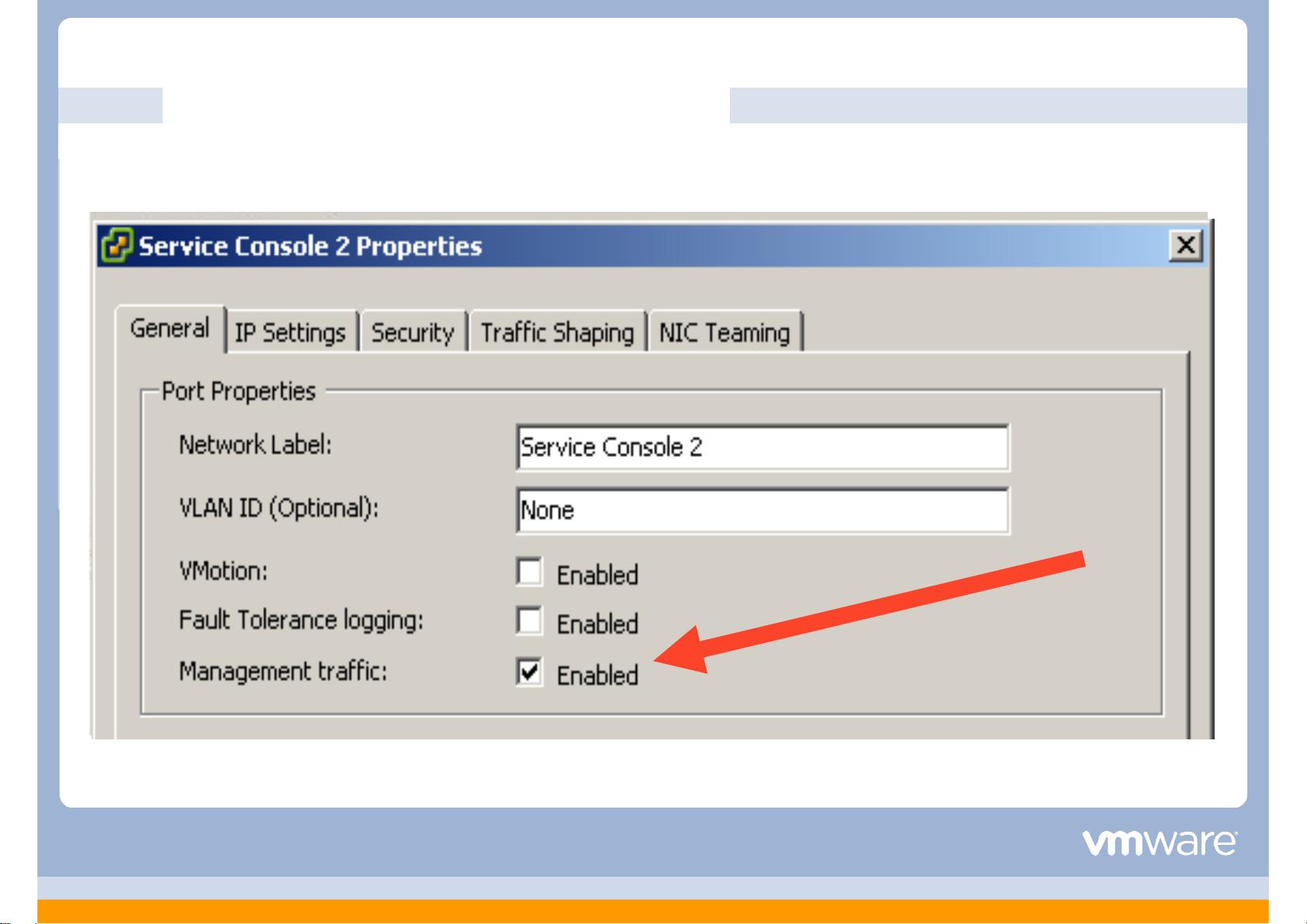
vSphere HA 通信选择 − ESX
剩余41页未读,继续阅读
2009-12-11 上传
2009-12-11 上传
182 浏览量
134 浏览量
171 浏览量
188 浏览量
171 浏览量
217 浏览量

imliuli
- 粉丝: 233
- 资源: 1350
 我的内容管理
展开
我的内容管理
展开







最新资源
- 紫黄扁平化工作总结图表大全PPT模板
- stuntz-strategies.github.io:stuntzstrategies.com
- GitRainbow-crx插件
- 煤渣:干净,响应Swift的MkDocs主题
- 基于modbus协议的大屏数据监控,使用modbus slave模拟数据,串口服务器获取温湿度.zip
- office2007驱动AccessDatabaseEngine.zip
- sample-quarkus-speaker:这是一个如何使用JAX-RS RESOURCES,Hibernate Panache以及如何准备在Openshift中使用S2I的项目的示例。
- Free fire generator-crx插件
- farmaciaJS:法玛西亚
- AngularJs-and-grunt-with-java-spring
- 数据结构课后答案
- sqlite-utils:用于操纵SQLite数据库的Python CLI实用程序和库
- SpringBoot-atguigu-resource:Bilibili SpringBoot_2019权威教程CRUD实验静态资源文件
- 蓝色复古花卉文艺范图表下载PPT模板
- duplichecker for chrome-crx插件
- binwalk-master.zip
