深度学习图像卷积详解:从Sobel算子到高层特征提取
版权申诉
145 浏览量
更新于2024-08-11
收藏 919KB PDF 举报
"深度学习:图像的卷积原理和本质(详解)。深度学习原理.pdf"
本文深入探讨了深度学习中的图像卷积原理及其在计算机视觉中的应用。卷积是深度学习,尤其是卷积神经网络(CNN)的核心操作,对于图像处理、边缘检测和图像分割等领域具有重要意义。
首先,卷积过程是通过一个小尺寸的滤波器(或称卷积核)在图像上滑动并应用特定的数学运算来完成的。例如,常见的滤波器尺寸为3×3或5×5,而图像则是一个较大的二维矩阵(或高维张量)。在卷积过程中,滤波器与图像的每个部分进行点乘操作,然后将结果求和,形成新的像素值,这通常用于特征提取或图像降噪。
卷积的起源可以从传统的图像处理算法中找到,比如Sobel算子。Sobel算子是一种边缘检测算法,其工作原理与卷积类似。通过对图像应用Sobel算子,可以检测到图像的边缘,这是因为卷积操作能够突出图像中的强度变化,从而标识出可能的边缘位置。因此,深度学习中的卷积层可以实现类似的功能,不仅能进行边缘检测,还能进行更复杂的图像分割任务。
在多通道图像(如RGB图像)中,卷积处理更为复杂。每个通道都要分别与卷积核进行卷积,并将结果相加,最终形成新的特征图。如果卷积核的通道数与输入图像的通道数相同,那么可以确保所有通道的信息都被考虑在内。
为了提取图像的高层特征,深度学习模型通常会包含多个卷积层和池化层。卷积层可以捕获图像的局部特征,而池化层则可以降低数据的空间维度,减少计算量,同时保持关键信息。全连接层则将这些低级和中级特征组合起来,形成全局的理解,为分类或回归任务提供输入。
从函数的角度来看,卷积过程可以视为在图像每个位置应用线性变换,将卷积核视为权重,图像像素视为输入,通过向量内积加上偏置来得到新的值。多层卷积网络通过层层映射形成一个复杂的非线性函数,训练过程就是学习这个函数的参数,以便最好地拟合输入数据。
深度学习中的卷积是通过一系列的数学运算,捕捉图像的局部模式,进而构建更高级别的特征表示。这种表示对于理解图像内容、识别物体以及执行其他视觉任务至关重要。通过深度卷积网络,我们可以实现从简单的边缘检测到复杂的图像识别等多种功能,这也是深度学习在人工智能领域取得诸多成就的基础。
深度学习:图像的卷积原理和本质(详解)。
⾸先,介绍图像卷积的计算过程。
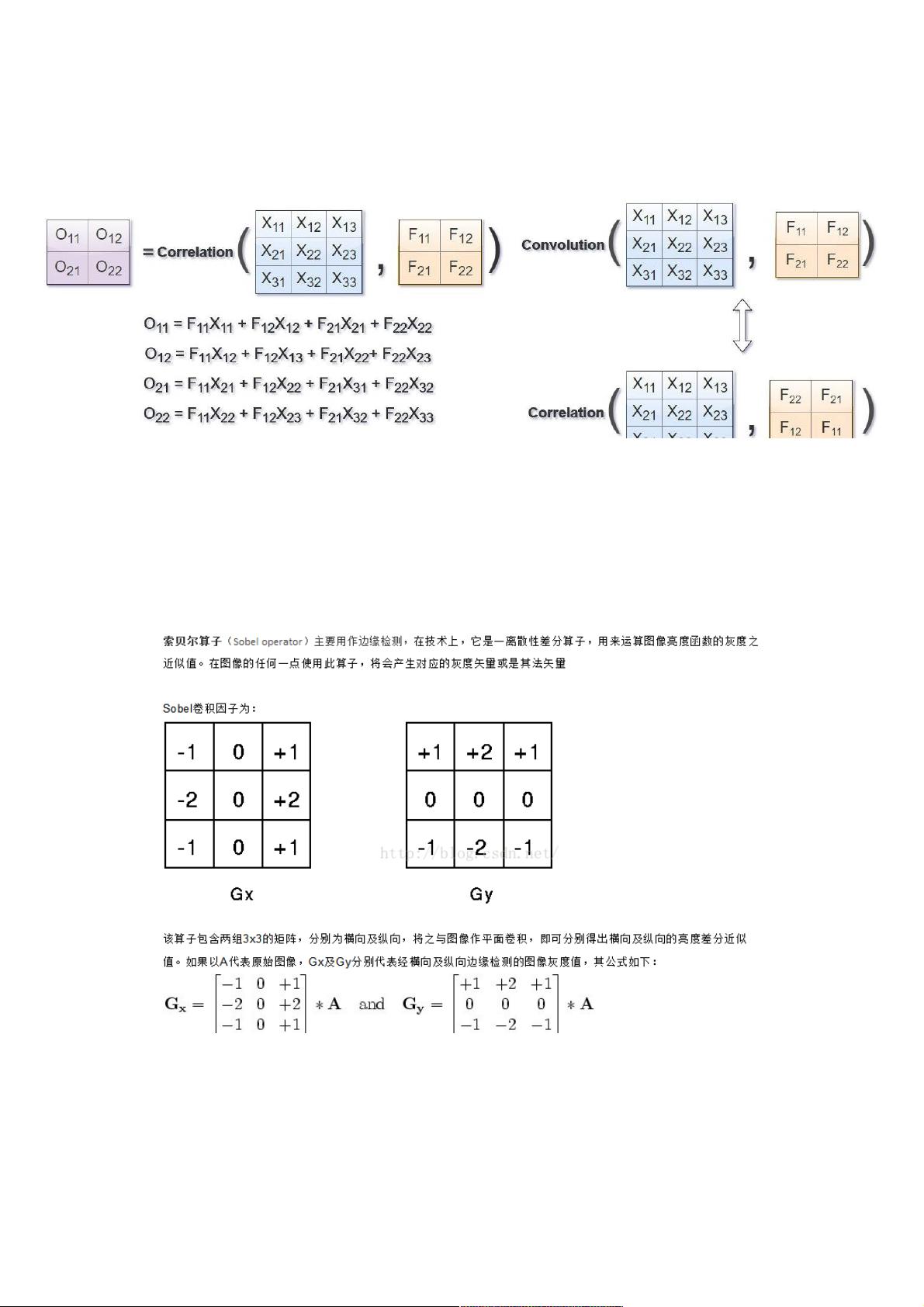
在计算机视觉领域,卷积核、滤波器通常为较⼩尺⼨的矩阵,⽐如3×33×3、5×55×5等,数字图像是相对较⼤尺⼨的2维(多维)矩阵
(张量),图像卷积运算与相关运算的关系如下图所⽰,其中FF为滤波器,XX为图像,OO为结果。
图1 图像卷积算⼦
以上便是图像卷积的某⼀次简单操作。
但是为什么⽤这样的⽅式呢?这种⽅式的起源来⾃哪⾥?
说到起源,⼤家是否能想起与上图运算⽅式相似的图像算法?sobel算⼦,对这是⼀个图像的边缘检测算法。
来看⼀看sobel边缘检测算⼦的原理过程
图2:sobel算⼦
下载后可阅读完整内容,剩余4页未读,立即下载
2023-10-14 上传
2022-04-13 上传
2024-06-09 上传
2018-05-11 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

_webkit
- 粉丝: 31
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







