"Kafka笔记参数说明及配置要求,深入解析Kafka流平台功能与特点"
需积分: 5 166 浏览量
更新于2024-01-01
收藏 1.05MB DOCX 举报
Kafka是一种流平台,最初是LinkedIn开发的一个内部基础设施系统,用于处理持续数据流。在设计理念上,开发者希望将数据视为一个持续变化和不断增长的流,并构建一个数据系统和架构。Kafka可以发布和订阅数据流,并将其保存并进行处理。
Kafka类似于传统的消息系统,但与其有很大的差异。首先,Kafka是一个现代分布式系统,以集群的方式运行,并可以自由伸缩。其次,Kafka可以按需存储数据,可以保存数据的时间非常灵活。第三,Kafka的流式处理能力可以将数据处理的层次推向新的高度。与传统的消息系统只能传递数据不同,Kafka的流式处理能力使我们可以用更少的代码动态地处理派生流和数据集。因此,Kafka不仅仅是一个消息中间件。
在大数据领域,Kafka还可以被看作是实时版的Hadoop。Hadoop用于存储和定期处理大量数据,而Kafka则可以将数据以实时的方式传输和处理,具有更高的实时性和灵活性。
接下来,我们将详细介绍关于Kafka的参数配置和部署。
一、Kafka部署:
Kafka可以以集群的方式进行部署,部署过程如下:
1.首先,确定Kafka集群的规模和数量,并准备相应的服务器。
2.在每台服务器上安装Kafka,并确保服务器之间可以相互通信。
3.配置Kafka集群的参数,包括Zookeeper的地址、Kafka监听的端口等。
4.启动Zookeeper集群,并确保集群正常运行。
5.在每台服务器上启动Kafka Broker,并加入到Zookeeper集群中。
6.验证Kafka集群的正常运行,包括发送和消费消息的功能。
二、Kafka配置要求:
1.Zookeeper的地址:Kafka使用Zookeeper来进行集群的管理和协调,因此需要配置正确的Zookeeper地址。
2.Kafka监听的端口:Kafka默认使用9092端口进行监听,可以根据需要进行配置。
3.数据存储位置:Kafka需要配置数据存储的位置,包括消息的存储和索引文件的存储。
4.日志压缩类型:Kafka可以对消息进行压缩,支持多种压缩类型,包括gzip、snappy等。
5.消息的保留时间:Kafka可以配置消息的保留时间,即消息在存储中的保存时间,默认为7天。
6.消息的备份数量:Kafka可以配置消息的备份数量,以确保消息的可靠性。
7.网络配置:Kafka还需要配置网络相关的参数,包括网络传输的缓冲区大小、连接超时等。
三、Kafka参数配置中文说明:
1.broker.id:Kafka Broker的唯一标识,每个Broker需要配置不同的id。
2.port:Kafka监听的端口,默认为9092。
3.log.dirs:数据存储的位置,包括消息的存储和索引文件的存储。
4.auto.create.topics.enable:是否允许自动创建Topic,默认为true。
5.num.partitions:一个Topic的分区数量,默认为1。
6.default.replication.factor:一个Topic的备份数量,默认为1。
7.socket.send.buffer.bytes:发送缓冲区的大小,默认为128KB。
8.socket.receive.buffer.bytes:接收缓冲区的大小,默认为32KB。
9.num.network.threads:网络处理的线程数量,默认为3。
10.num.io.threads:IO处理的线程数量,默认为8。
11.log.retention.hours:消息的保留时间,默认为168小时。
12.log.retention.bytes:消息的保留大小,默认为-1,表示不限制。
13.log.segment.bytes:日志段文件的大小,默认为1GB。
14.log.cleaner.enable:是否启用日志清理,默认为true。
15.append.records.checksums:是否启用消息的校验和,默认为true。
总结:
Kafka是一种流平台,用于处理持续数据流。它不仅仅是一个消息中间件,还具备流式处理的能力。Kafka可以以集群的方式部署,并需要配置一系列参数来满足不同的需求。Kafka的配置要求包括Zookeeper的地址、Kafka监听的端口、数据存储位置、日志压缩类型、消息的保留时间等。Kafka的参数配置中文说明涵盖了一系列参数,包括Broker id、端口、数据存储位置、自动创建Topic、分区数量、备份数量、缓冲区大小、线程数量、消息的保留时间等。通过理解和配置这些参数,可以更好地使用和管理Kafka。
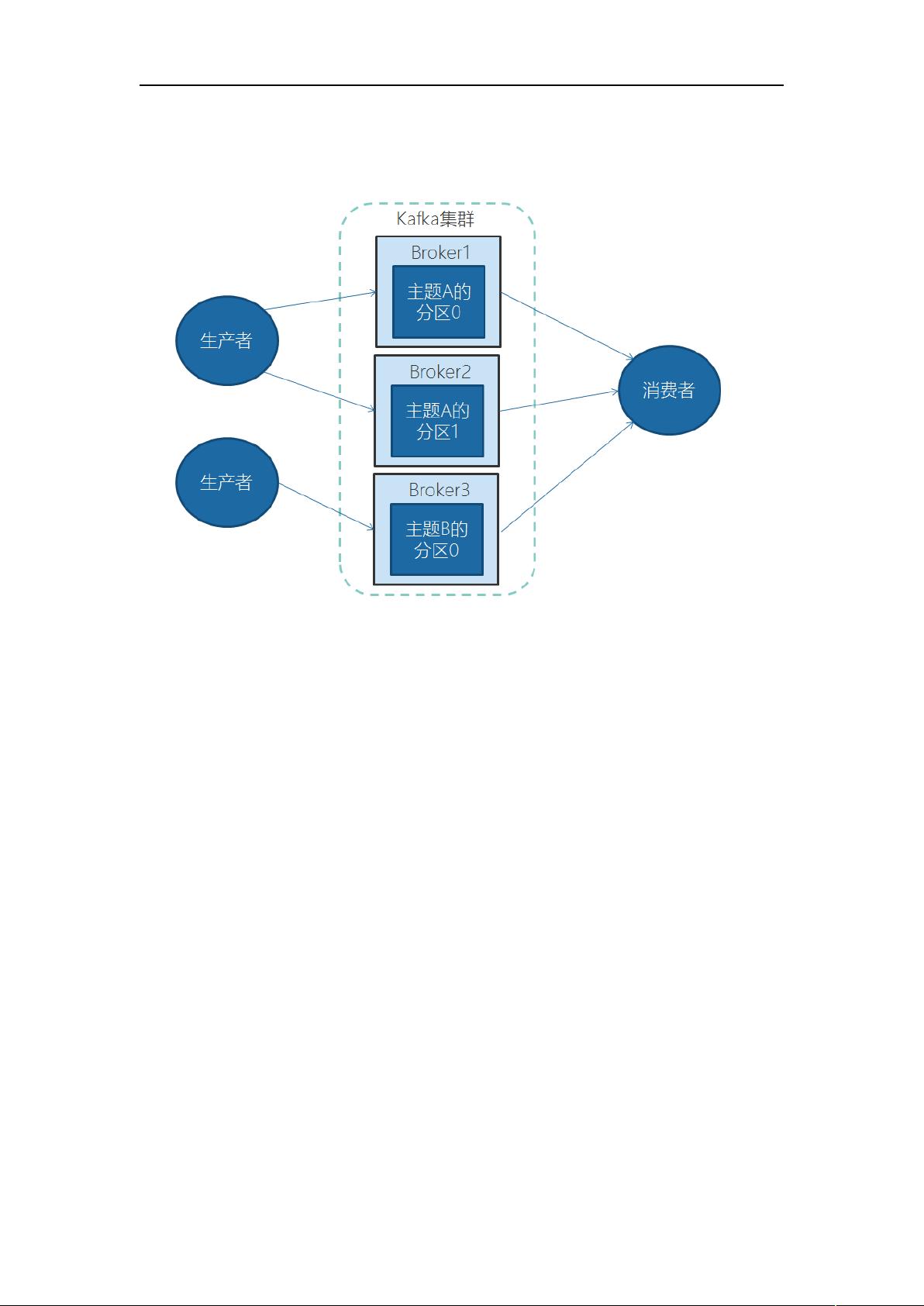
Kafka 的集群
为何需要 Kafka 集群
本地开发,一台 足够使用。在实际生产中,集群可以跨服务器进行负载均衡,
再则可以使用复制功能来避免单独故障造成的数据丢失。同时集群可以提供高可用性。
如何估算 Kafka 集群中 Broker 的数量
要估量以下几个因素:
需要多少磁盘空间保留数据,和每个 " 上有多少空间可以用。比如,如果一个集
群有 的数据需要保留,而每个 " 可以存储 ,那么至少需要 B 个 "。如果
启用了数据复制,则还需要一倍的空间,那么这个集群需要 个 "。
集群处理请求的能力。如果因为磁盘吞吐量和内存不足造成性能问题,可以通过扩展
" 来解决。
Broker 如何加入 Kafka 集群
非常简单,只需要两个参数。第一,配置 4((,第二,为新增的 "
设置一个集群内的唯一性 。

剩余48页未读,继续阅读
2017-09-22 上传
2022-02-10 上传
2024-02-22 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

you来有去
- 粉丝: 7890
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android应用源码利用poi将内容填到word模板-IT计算机-毕业设计.zip
- mdi-es:材料设计图标导出为ES模块
- LocationSearch
- 行业文档-设计装置-一种利用浸胶纸作为过渡联接体的胶合板.zip
- ImageProcessingApp:使用流行的MVC架构的图像处理应用程序
- hideandseek:Hide & Seek 是一款开源的多人在线街机游戏,对抗两支捉迷藏者团队,玩法有趣快节奏。 项目已从 https 移出
- angular-first-app
- 数据库课程设计-家庭理财管理.zip
- MochaBabelCoverage:一个 Mocha 运行器,支持对包含 JSX 的文件运行 Mocha,并支持覆盖率报告
- 脑机接口BCI-eeglab安装包
- grantwforsythe.github.io
- 性能测试工具LoadRunner书籍(14本)目录知识点(思维导图加图).rar
- ArgRouter:为js函数添加重载功能
- 2D形状
- android应用源码合肥工业大学客户端源码-IT计算机-毕业设计.zip
- PdfFormFillerUTF-8:带有命令行或 WWW 界面的简单 PDF Form Filler 实用程序。-开源
