糖尿病检测:KNN、逻辑回归与决策树模型分析
需积分: 15 62 浏览量
更新于2024-06-29
1
收藏 1.76MB PDF 举报
"该资源是一个关于糖尿病检测的数据分析项目,要求使用不同的机器学习方法,包括KNN算法、逻辑回归和决策树,分析8个特征,构建模型并评估其性能。"
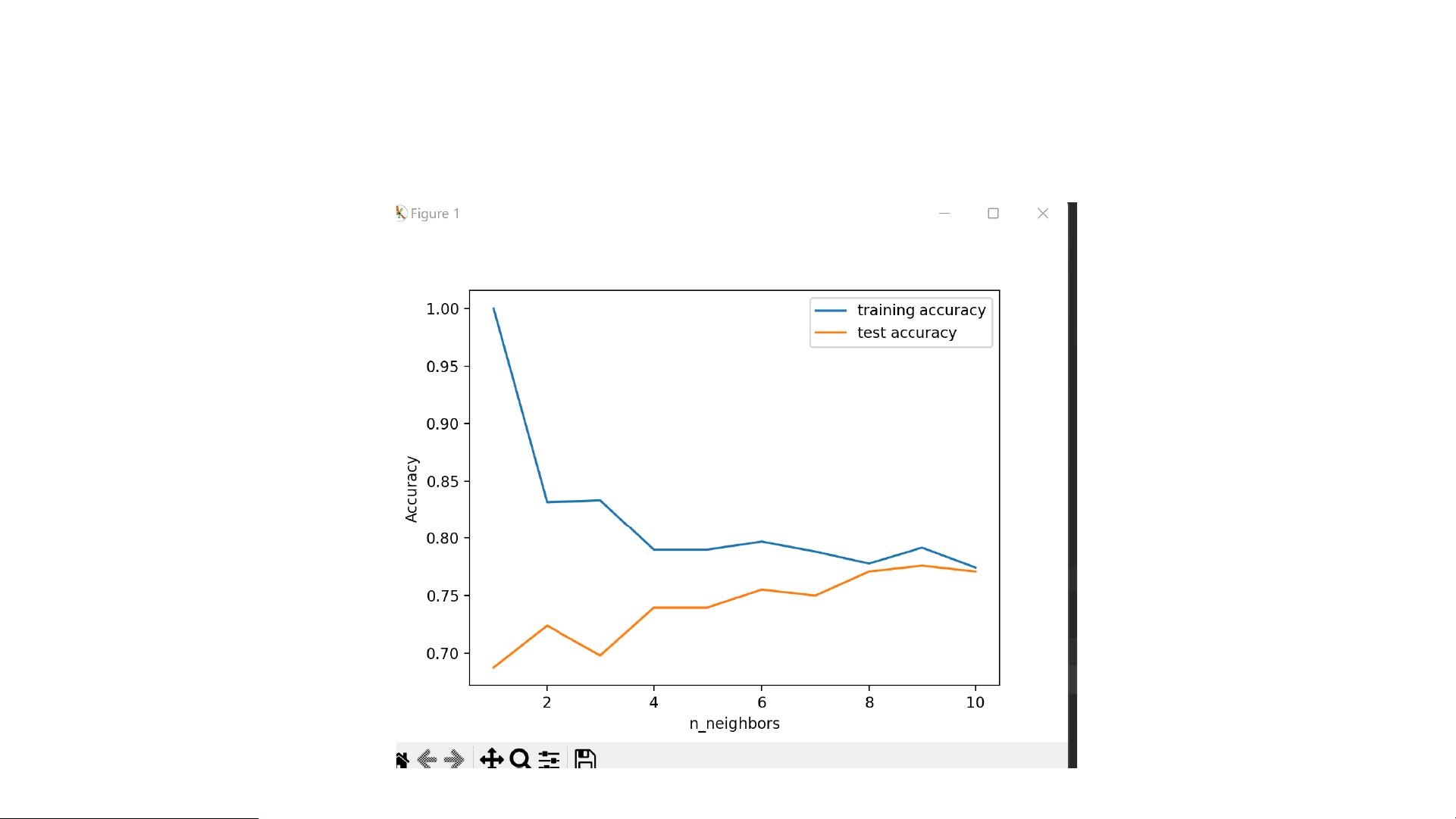
在糖尿病检测的数据集中,分析涉及了多个机器学习模型的构建和评估。首先,我们关注KNN(K-最近邻)算法,这是一个基于实例的学习方法,模型存储训练数据,并在预测时寻找最近的邻居。通过改变邻居数量(k值),我们可以调整模型的复杂度和精确度。在本案例中,发现当k=9时,模型在训练集和测试集上的平衡最佳。
接着,我们转向逻辑回归,它是一种广泛使用的二分类算法。虽然增大正则化参数C(如C=100)可能导致训练集准确度提高,但测试集的准确度可能会降低,提示可能存在过拟合。默认设置C=1被认为是较好的选择,因为它在保持模型简洁性的同时,提供了相对稳定的预测性能。通过可视化模型系数,发现特征"DiabetesPedigreeFunction"在所有情况下都有正向关联,意味着这个特征对糖尿病预测有积极影响。
最后,我们讨论了决策树,它容易发生过拟合,导致训练集准确度过高而测试集准确度低。通过限制决策树的最大深度(如max_depth=3),可以缓解过拟合,提高模型对新数据的泛化能力。此外,决策树还提供特征重要性评分,帮助我们理解哪些特征对预测结果的影响更大。
这个数据分析项目旨在通过比较不同模型在糖尿病检测数据集上的表现,找出最佳的预测策略。通过对KNN、逻辑回归和决策树的参数调整和性能评估,我们可以更好地理解每个模型的优势和局限性,为实际的糖尿病预测提供有价值的见解。
如果无图片输出,看看是不是忘了
plt.show()
剩余34页未读,继续阅读
2019-04-17 上传
2023-06-17 上传
2021-05-22 上传
2024-10-25 上传
2023-05-31 上传
2023-06-01 上传
2024-05-08 上传
2023-04-30 上传
2023-07-10 上传

我爱学习168
- 粉丝: 233
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- Effective C++ 第2版(中文版).pdf
- verilog+HDL.pdf
- 汇编DEBUG命令使用解析及范例大全
- Instructor’s Solution Manual
- 2010年英语考研大纲词汇
- 华为笔试题含答案 [C]
- 游戏编程之单例类与对象工厂的简单介绍与实现
- ARM嵌入式WINCE实践教程 pdf
- linux系统移植(很详细的移植文档哦) pdf
- 系统托盘Shell_NotifyIcon
- mfc实现系统托盘c++
- VERILOG快速入门
- 《计算机应用基础》习题参考答案.doc
- CC1110中文资料(无线部分)
- ExecutableLinkableFormat.pdf
- 笔记本电脑维修指导手册
