STM32嵌入式平台上的孤立词语音识别系统实现
需积分: 50 186 浏览量
更新于2024-07-17
1
收藏 1.27MB PDF 举报
"STM32嵌入式平台上实现的孤立词语音识别系统是一个结合了音频处理、模式识别和嵌入式技术的项目。系统通过一系列处理步骤,包括预滤波、ADC转换、分帧、端点检测、预加重、加窗、特征提取(Mel频率倒谱系数MFCC)以及动态时间弯折(DTW)算法进行特征匹配,最终完成语音识别。该设计首先在Matlab环境中进行算法验证,然后针对STM32嵌入式平台的存储和计算限制进行优化移植,构建出一个基于STM32的孤立词语音识别系统。这一技术的发展受到消费电子和移动互联网的推动,逐渐从实验室走向实际应用,如语音门禁、智能电视控制、智能手机助手等,预示着语音识别在人工智能领域的重要地位和广泛应用前景。"
STM32嵌入式平台上的孤立词语音识别系统是语音识别技术在嵌入式设备中的实现,其核心技术包括以下几个方面:
1. **预处理**:语音信号首先通过预滤波去除噪声,改善信噪比,以提高后续处理的效果。
2. **模拟数字转换(ADC)**:ADC将麦克风采集的模拟语音信号转化为数字信号,为后续数字处理提供基础。
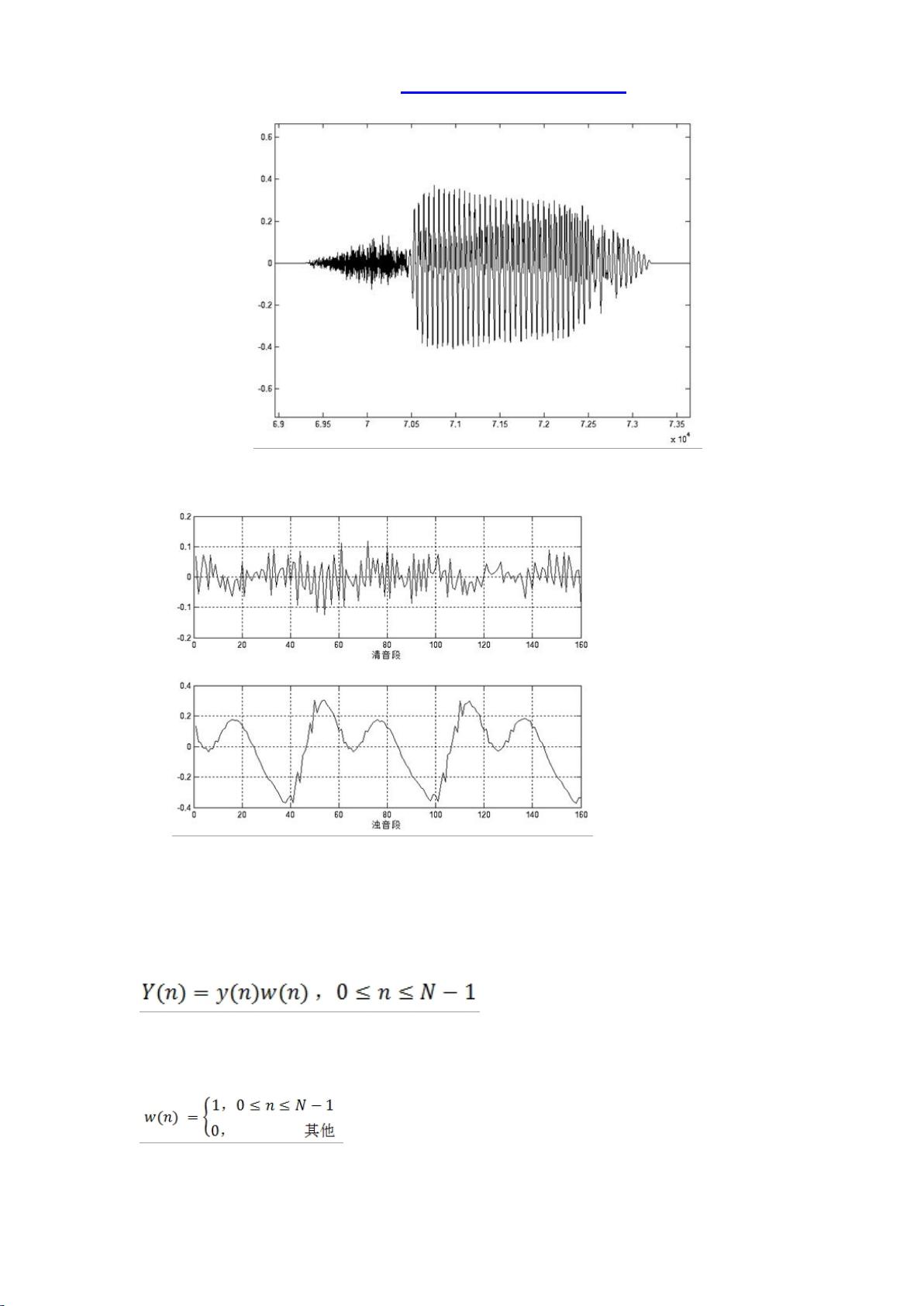
3. **分帧与端点检测**:将数字语音信号分割成多个短时帧,并使用短时幅度和短时过零率结合的方法进行端点检测,以确定有效语音片段。
4. **预加重**:通过补偿高频率成分的衰减,使得语音信号的频谱更接近人耳感知。
5. **加窗**:减少帧间干扰,提高谱分析的精度。
6. **特征提取**:计算每帧语音的Mel频率倒谱系数(MFCC),这是模拟人耳对不同频率敏感性的特征参数。
7. **特征匹配**:利用动态时间弯折(DTW)算法,使得输入语音的MFCC序列与预先训练的模板匹配,确定最佳匹配结果,从而识别出对应的孤立词。
8. **算法优化与移植**:在STM32平台上,需要针对嵌入式设备的资源限制进行算法优化,确保识别系统的实时性和效率。
这个系统展示了语音识别技术在嵌入式环境中的应用潜力,尤其在资源有限的微控制器上实现复杂算法的能力。随着技术的进步,这种技术将更加普及,推动更多的智能设备采用语音交互,提高用户体验,并在智能家居、车载系统、医疗健康等领域发挥重要作用。
剩余23页未读,继续阅读
2021-04-20 上传
2024-10-09 上传
2021-04-22 上传
点击了解资源详情
2018-08-07 上传
2024-06-18 上传
2024-04-25 上传

Aneglar
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
