大数据环境下的MapReduce关联规则挖掘
需积分: 10 42 浏览量
更新于2024-07-23
收藏 788KB PDF 举报
"这篇文档详细介绍了大数据环境下的关联规则挖掘技术,主要涵盖了MapReduce计算框架、关联规则挖掘的基本概念、面临的挑战以及MapReduce为解决大数据关联规则挖掘问题提供的两种解决方案。文档作者为赵修湘,内容包括课程目标、MapReduce框架介绍、关联规则挖掘原理、挖掘过程中的挑战以及MapReduce如何应对这些挑战。"
正文:
关联规则挖掘是数据挖掘领域中的一个重要方法,用于在大数据集中寻找项集之间的有趣关联。在大数据环境下,这一过程变得尤为复杂,因为数据量庞大,处理速度和效率成为关键问题。MapReduce计算框架是Google提出的一种分布式计算模型,适用于处理大规模数据集,为关联规则挖掘提供了可能。
MapReduce框架由两个主要阶段组成:Map和Reduce。Map阶段将输入数据分割成多个部分,每个部分由一个Map任务独立处理,生成中间键值对。Reduce阶段则负责收集Map阶段的结果,对相同键的值进行聚合,最终输出结果。这种并行处理方式使得MapReduce能够高效地处理海量数据。
在关联规则挖掘中,有两个核心度量参数:支持度和支持度。支持度衡量的是项集在所有事务中出现的频率,而置信度则表示在项集A出现的情况下,项集B出现的概率。Apriori算法是一种经典的关联规则挖掘算法,它通过迭代生成频繁项集,然后基于这些项集构建满足最小支持度和最小置信度的关联规则。
然而,在大数据环境下,关联规则挖掘面临着诸多挑战,例如数据分布不均、计算资源的高效利用、内存限制以及处理时间等问题。MapReduce提供了解决这些问题的策略。一方面,通过数据分区和并行处理,MapReduce能够有效地处理大数据集;另一方面,它通过容错机制确保任务的可靠执行,即使在节点故障时也能保证作业的完成。
文档中提到了两种MapReduce的解决方案。第一种可能涉及使用MapReduce来实现Apriori算法的分布式版本,通过多轮MapReduce任务分别找出频繁项集和挖掘关联规则。第二种解决方案可能涉及到优化算法,比如采用基于云图的算法或者使用近似算法来减少计算量,提高挖掘效率。
大数据环境下的关联规则挖掘需要结合强大的计算框架如MapReduce,通过设计适应大数据特性的算法,以解决海量数据中的关联发现问题。这种方法在商业智能、市场分析、用户行为预测等领域有着广泛的应用,帮助企业发现潜在的销售模式,优化库存管理,提升客户体验。
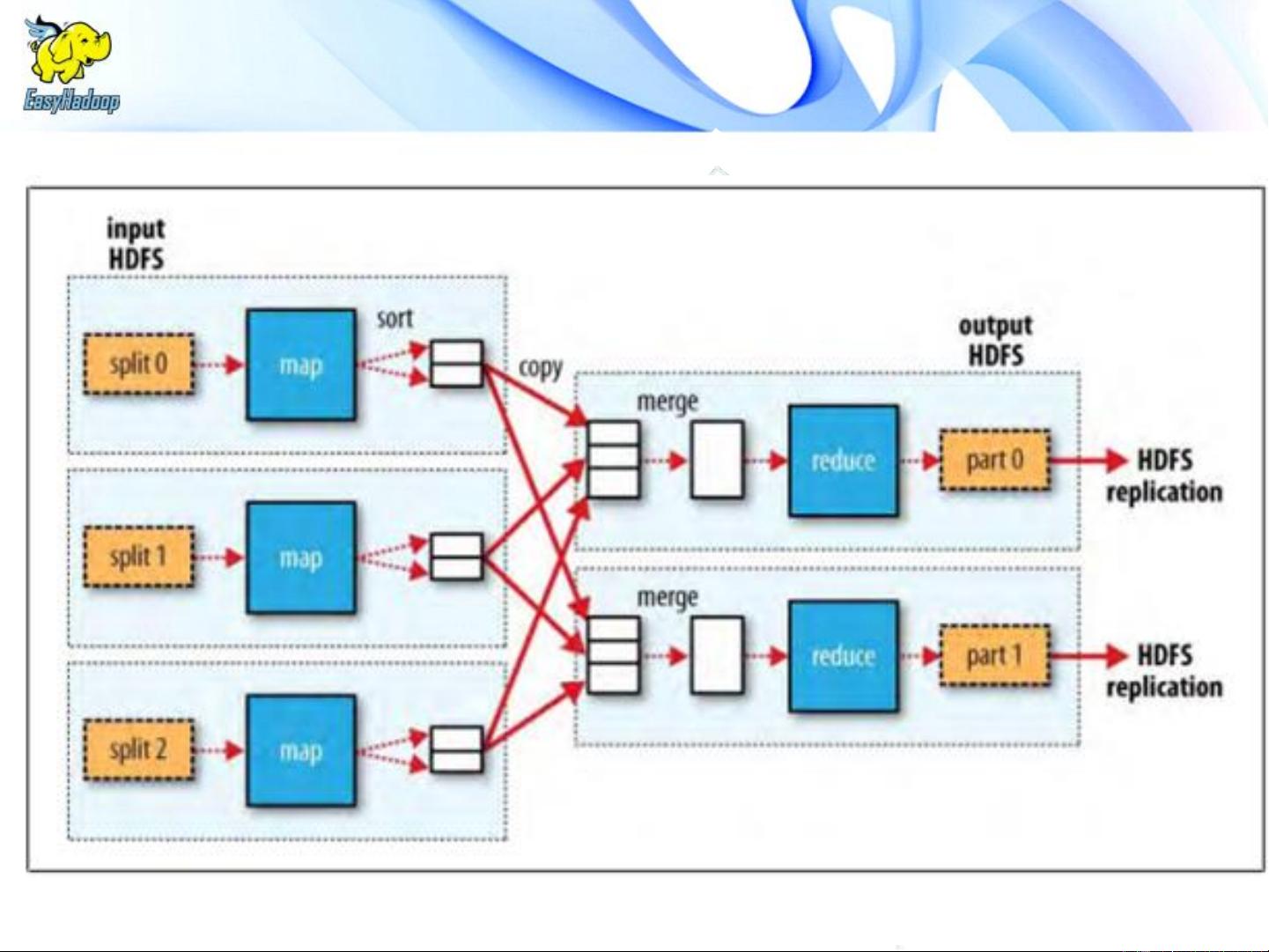
mapred计算框架简介
剩余20页未读,继续阅读
2021-11-20 上传
2021-10-03 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

alongines
- 粉丝: 179
- 资源: 25
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握Jive for Android SDK:示例应用的使用指南
- Python中的贝叶斯建模与概率编程指南
- 自动化NBA球员统计分析与电子邮件报告工具
- 下载安卓购物经理带源代码完整项目
- 图片压缩包中的内容解密
- C++基础教程视频-数据类型与运算符详解
- 探索Java中的曼德布罗图形绘制
- VTK9.3.0 64位SDK包发布,图像处理开发利器
- 自导向运载平台的行业设计方案解读
- 自定义 Datadog 代理检查:Python 实现与应用
- 基于Python实现的商品推荐系统源码与项目说明
- PMing繁体版字体下载,设计师必备素材
- 软件工程餐厅项目存储库:Java语言实践
- 康佳LED55R6000U电视机固件升级指南
- Sublime Text状态栏插件:ShowOpenFiles功能详解
- 一站式部署thinksns社交系统,小白轻松上手
