
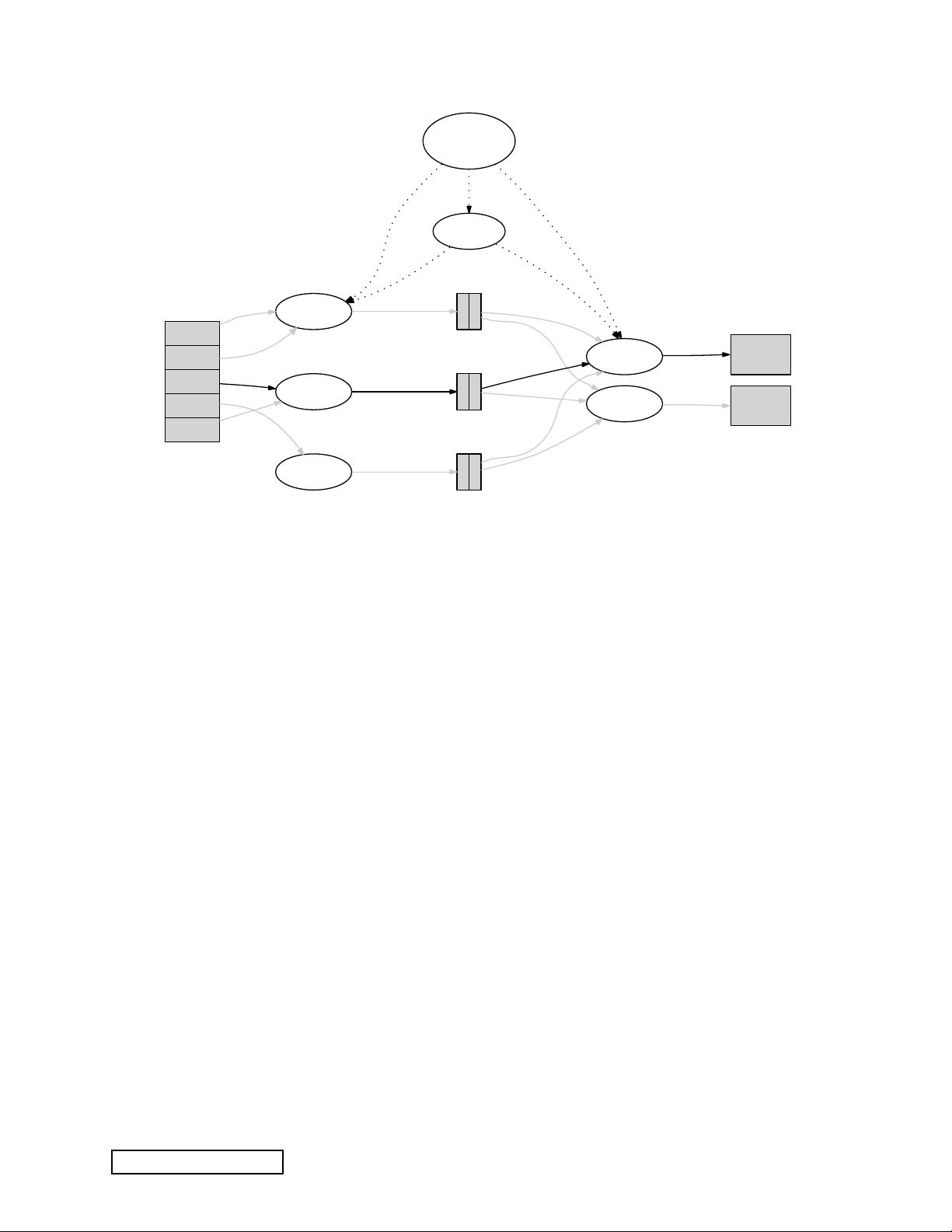
User
Program
Master
(1) fork
worker
(1) fork
worker
(1) fork
(2)
assign
map
(2)
assign
reduce
split 0
split 1
split 2
split 3
split 4
output
file 0
(6) write
worker
(3) read
worker
(4) local write
Map
phase
Intermediate files
(on local disks)
worker
output
file 1
Input
files
(5) remote read
Reduce
phase
Output
files
Figure 1: Execution overview
Inverted Index: The map function parses each docu-
ment, and emits a sequence of hword, document IDi
pairs. The reduce function accepts all pairs for a given
word, sorts the corresponding document IDs and emits a
hword, list(document ID)i pair. The set of all output
pairs forms a simple inverted index. It is easy to augment
this computation to keep track of word positions.
Distributed Sort: The map function extracts the key
from each record, and emits a hkey, recordi pair. The
reduce function emits all pairs unchanged. This compu-
tation depends on the partitioning facilities described in
Section 4.1 and the ordering properties described in Sec-
tion 4.2.
3 Implementation
Many different implementations of the MapReduce in-
terface are possible. The right choice depends on the
environment. For example, one implementation may be
suitable for a small shared-memory machine, another for
a large NUMA multi-processor, and yet another for an
even larger collection of networked machines.
This section describes an implementation targeted
to the computing environment in wide use at Google:
large clusters of commodity PCs connected together with
switched Ethernet [4]. In our environment:
(1) Machines are typically dual-processor x86 processors
running Linux, with 2-4 GB of memory per machine.
(2) Commodity networking hardware is used – typically
either 100 megabits/second or 1 gigabit/second at the
machine level, but averaging considerably less in over-
all bisection bandwidth.
(3) A cluster consists of hundreds or thousands of ma-
chines, and therefore machine failures are common.
(4) Storage is provided by inexpensive IDE disks at-
tached directly to individual machines. A distributed file
system [8] developed in-house is used to manage the data
stored on these disks. The file system uses replication to
provide availability and reliability on top of unreliable
hardware.
(5) Users submit jobs to a scheduling system. Each job
consists of a set of tasks, and is mapped by the scheduler
to a set of available machines within a cluster.
3.1 Execution Overview
The Map invocations are distributed across multiple
machines by automatically partitioning the input data
To appear in OSDI 2004 3
剩余12页未读,继续阅读

csumzf
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- Google Test 1.8.x版本压缩包快速下载指南
- Java实现二叉搜索树的插入与查找功能
- Python库丰富性与数据可视化工具Matplotlib
- MATLAB通信仿真设计源代码与应用解析
- 响应式环保设备网站模板源码下载
- 微信小程序答疑平台完整设计源码案例
- 全元素DFT计算所需赝势UPF文件集合
- Object-C实现的Flutter组件开发详解
- 响应式环境设备网站模板下载 - 恒温恒湿机营销平台
- MATLAB绘图示例与知识点深入探讨
- DzzOffice平台新插件:excalidraw白板功能介绍与使用指南
- Java基础实训教程:电子商城项目开发与实践
- 物业集团管理系统数据库设计项目完整复刻包
- 三五族半导体能带参数计算器:精准模拟与应用
- 毕业论文:基于SSM框架的毕业生跟踪调查反馈系统设计与实现
- 国产化数据库适配:人大金仓与达梦实践教程
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


