"Spark安装、部署与Scala程序运行指南"
需积分: 1 152 浏览量
更新于2024-03-13
收藏 1.5MB PDF 举报
Spark是一个快速的、通用的集群计算系统,也是一个基于内存计算的大数据处理框架。本文将会介绍关于Spark的基础知识,包括安装和部署,以及在不同操作系统上运行Spark程序的方法。我们将会使用软件包VMware、SSH连接工具XshellPlus、Linux操作系统CentOS-7、JDK1.8、Hadoop2.7.4、Hive2.3.6、Spark2.3.2以及IntelliJ IDEA2019来进行安装和部署。通过本文学习,读者将了解Spark的特点、掌握Spark集群的搭建、理解Spark运行架构与原理以及掌握在不同操作系统上部署和运行Spark程序的方法。
首先,本文将介绍关于Spark基础的知识。Spark是一种快速、通用的集群计算系统,它支持多种编程语言,包括Java、Scala、Python和R。Spark提供了高层次的API,使得用户能够轻松地使用它来进行大规模数据处理。此外,Spark的一个重要特点是基于内存计算,它能够在内存中对数据进行快速的计算,从而提高计算性能。除此之外,Spark还提供了丰富的库和工具,如Spark SQL、Spark Streaming和MLlib等,用于满足不同领域的大数据处理需求。
接下来,本文将介绍关于Spark的安装和部署。对于Spark的安装,我们将会使用软件包VMware来搭建虚拟机环境,并使用SSH连接工具XshellPlus来进行远程连接。在Linux操作系统CentOS-7上,我们将会安装JDK1.8、Hadoop2.7.4、Hive2.3.6和Spark2.3.2这些必要的软件包,以建立起Spark的开发环境。一旦安装完成,我们将会学习不同的部署模式,包括Standalone模式、YARN模式和Mesos模式。每种模式都有其特点和适用场景,读者将学会如何根据实际需求选择合适的部署模式来搭建Spark集群。
在第二章中,本文将会详细介绍如何在不同操作系统上运行Scala程序以及在HDFS系统上运行Scala程序。在Windows操作系统上,我们将会使用IntelliJ IDEA2019来进行Scala程序的编写和运行。通过配置相关环境和参数,我们可以轻松地在Windows上运行Scala程序,并实现数据的读写和计算。另外,我们还将会介绍如何在Linux操作系统的HDFS系统上运行Scala程序,以实现大规模的数据处理。
总而言之,本文将会为读者提供关于Spark的基础知识、安装和部署,以及在不同操作系统上运行Spark程序的方法。通过学习本文,读者将能够了解Spark的特点,掌握Spark集群的搭建,理解Spark运行架构与原理,并掌握在不同操作系统上部署和运行Spark程序的方法。希望本文能够帮助读者更深入地了解和应用Spark,从而更好地实现大数据处理和分析的需求。
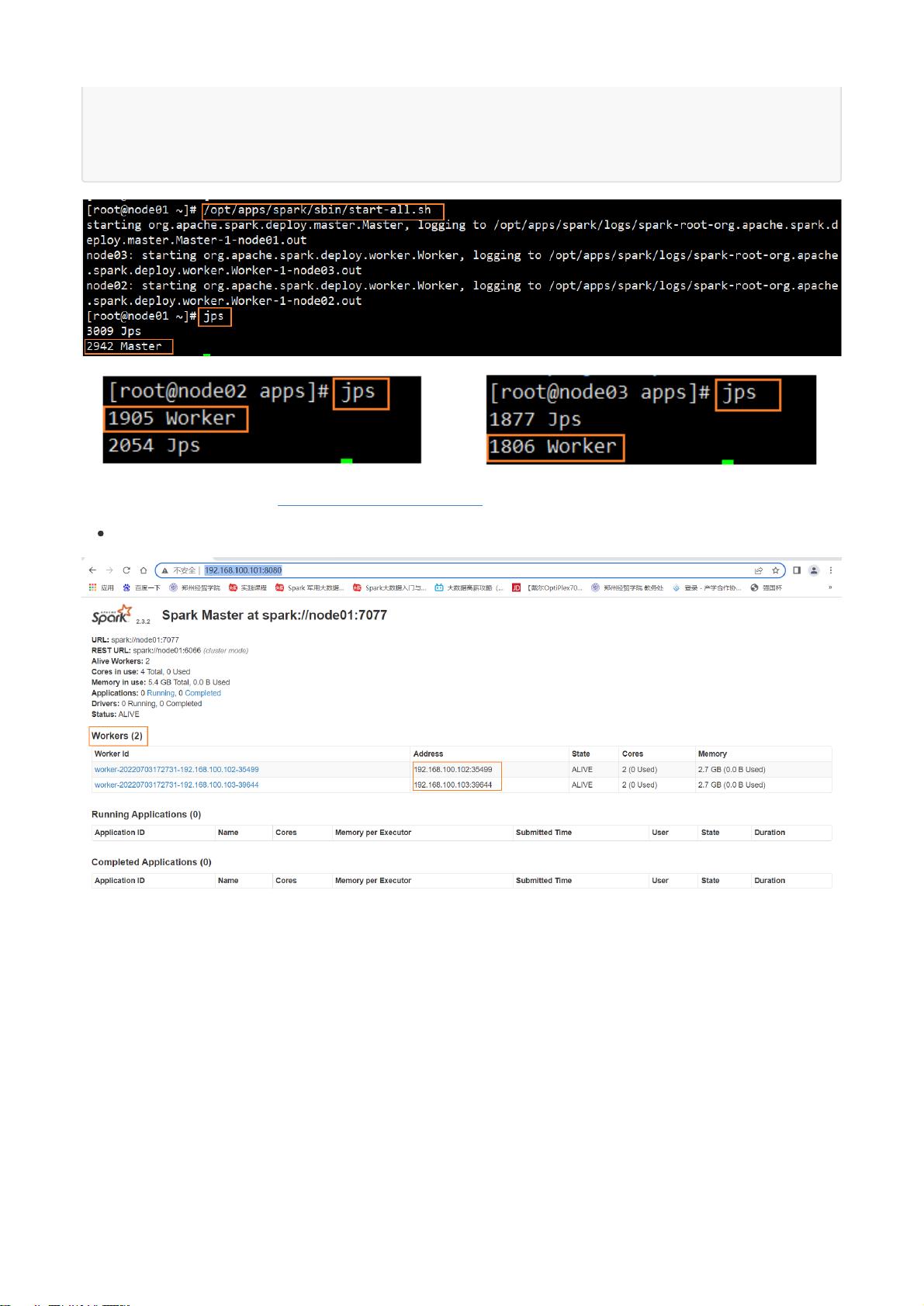
访问Spark WebUI管理界面:http://192.168.100.101:8080/ ,可以看到这里有两个从节点,处于存活状态。
8080:spark master的webUI端口,同时也是Tomcat的端口。
注意:这里只需要启动Spark集群,即可测试Standalone模式是否部署成功!
2.3.3. YARN模式(掌握)
下面讲YARN模式下,Spark的安装与配置
Spark on Yarn是生产环境中最为常见的部署方式,只不过这种方式有两种模式“yarn-client" 和"yarn-cluster"。两
种模式大同小异,主要区别是Driver运行在哪里。Spark Shell只能采用yarn-client模式。
(1)修改文件 spark-env.sh
[root@node01 conf]# scp -r /opt/apps/spark node03:/opt/apps/
## 7.启动Spark集群,并用jps命令查看运行的进程
[root@node01 conf]# cd ~
[root@node01 ~]# /opt/apps/spark/sbin/start-all.sh
剩余18页未读,继续阅读
2018-04-13 上传
2024-03-25 上传
2023-03-31 上传
2016-12-13 上传
2023-06-14 上传
2019-10-29 上传
点击了解资源详情

冷月半明
- 粉丝: 3864
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- 近探拓客软件-实现日更新的全国工商数据采集的工具-工商数据采集工具免费下载V21.4.1
- telescope_hoogle:望远镜的Hoogle搜索集成
- passwordGenerator:此分配使用math.random为用户生成密码
- dotnet C# 根据椭圆长度和宽度和旋转角计算出椭圆中心点的方法.rar
- ProjectManager:.NET Core中的简单项目管理
- Muzisung_FE:这是无知项目前端的存储库。
- Mysis_DVM_Modeling:我的高级论文项目“为 Diluviana 的 Diel 垂直迁移模式建模”的代码和头脑风暴。
- torch_spline_conv-1.2.1-cp36-cp36m-linux_x86_64whl.zip
- CMTraerPhysics:Traer v3.0物理引擎的Objective-CCocoa端口; 与iOS演示应用程序
- bilingual-pdf:由英文PDF生成双语PDF,回归原生加速长篇英文阅读!
- js-demo:关于本人博客中关于js的使用的代码示例
- 清水混凝土模板支撑施工方案.zip
- 来自“菜鸟教程”JavaScript实例练习【二】web.zip
- 仿天猫静态页面 登陆/注册/首页/天猫超市页/购物车/手机列表页 Tmall.zip
- 淘特新闻管理系统 v4.0.4
- Class-33
