快速ε-最优离散追踪学习自动机:大型行动领域的新方法
136 浏览量
更新于2024-08-27
收藏 1.12MB PDF 举报
"这篇研究论文是关于快速且Epsilon最优的离散追踪学习自动机,发表在2015年10月的IEEE Transactions on Cybernetics期刊上,由Jun Qi Zhang, Cheng Wang和Meng Chu Zhou (IEEE Fellow)共同撰写。"
在强化学习领域,学习自动机(Learning Automata, LA)是一种强大的工具。离散追踪学习自动机(Discretized Pursuit Learning Automata, DPLA)是其中最为流行的一种。DPLA在每个迭代周期内包含三个基本阶段:1) 选择下一个动作;2) 找到最优估计动作;3) 更新状态概率。然而,当动作的数量非常大时,学习过程会变得极其缓慢,因为每个迭代中需要进行太多更新,主要来自第一阶段的动作选择和第三阶段的状态概率更新。
针对这个问题,论文提出了一种新的快速离散追踪学习自动机,保证了ε-最优性。这种方法的关键在于,它将第一阶段的动作选择和第三阶段的状态概率更新的计算复杂度独立于动作的数量,从而大大减少了计算量。这使得新方法在处理大量动作的情况下,仍能保持高效运行。
此外,尽管具有较低的计算复杂度,这种新型学习自动机在静态环境中的收敛速度比传统方法更快。这一改进对于那些需要高效强化学习的大型规模、动作导向的应用场景来说,具有显著的促进作用。论文的贡献在于提供了一种优化策略,使得DPLA能够在保持性能的同时,适应更复杂的决策问题,扩展了LA在大规模行动领域的应用潜力。
ZHANG et al.: FAST AND EPSILON-OPTIMAL DISCRETIZED PURSUIT LA 2091
Fig. 2. DP
RI
using r = 3andn = 5, a
1
is the estimated optimal action and
positive response is received. DP
RI
(a) initialization and (b) state probability
update when the chosen action is rewarded.
the state probability of the action with the highest estimate
has to be increased by an integral multiple of the smallest
step size . When the chosen action is penalized, there is
no updating in the state probability vector, and it is thus of
the reward-inaction paradigm. Assume that m is the index of
the estimated optimal action. The update scheme of DP
RI
is
described briefly as follows [1], [36].
Phase 1: Select the next action.
Select an action a(t) = a
k
according to the probability distri-
bution P(t). Update H
k
, G
k
and
d
k
.
Phase 2: Find the optimal estimated action
m = argmax
i
{
d
i
}.
Phase 3: Update the state probability.
If β(t) = 1 Then
p
j
(t + 1) = max
j=m
{p
j
(t) − , 0}, ∀j ∈ N
r
(2)
p
m
(t + 1) = 1 −
j=m
p
j
(t + 1). (3)
Else
p
j
(t + 1) = p
j
(t), ∀j ∈ N
r
. (4)
Endif
III. F
AST DISCRETIZED PURSUIT LA
In this section, FDP
RI
is proposed by exploiting the most
significant pattern of the discretized update scheme in DP
RI
.
This pattern always increases the state probability of the esti-
mated optimal action but decreases others by discretized step
= 1/(rn) where r is the number of allowable actions, and
n is a resolution parameter.
Once an update occurs, (r − 1) ∗ are rewarded to the
estimated optimal action and other actions are all penalized
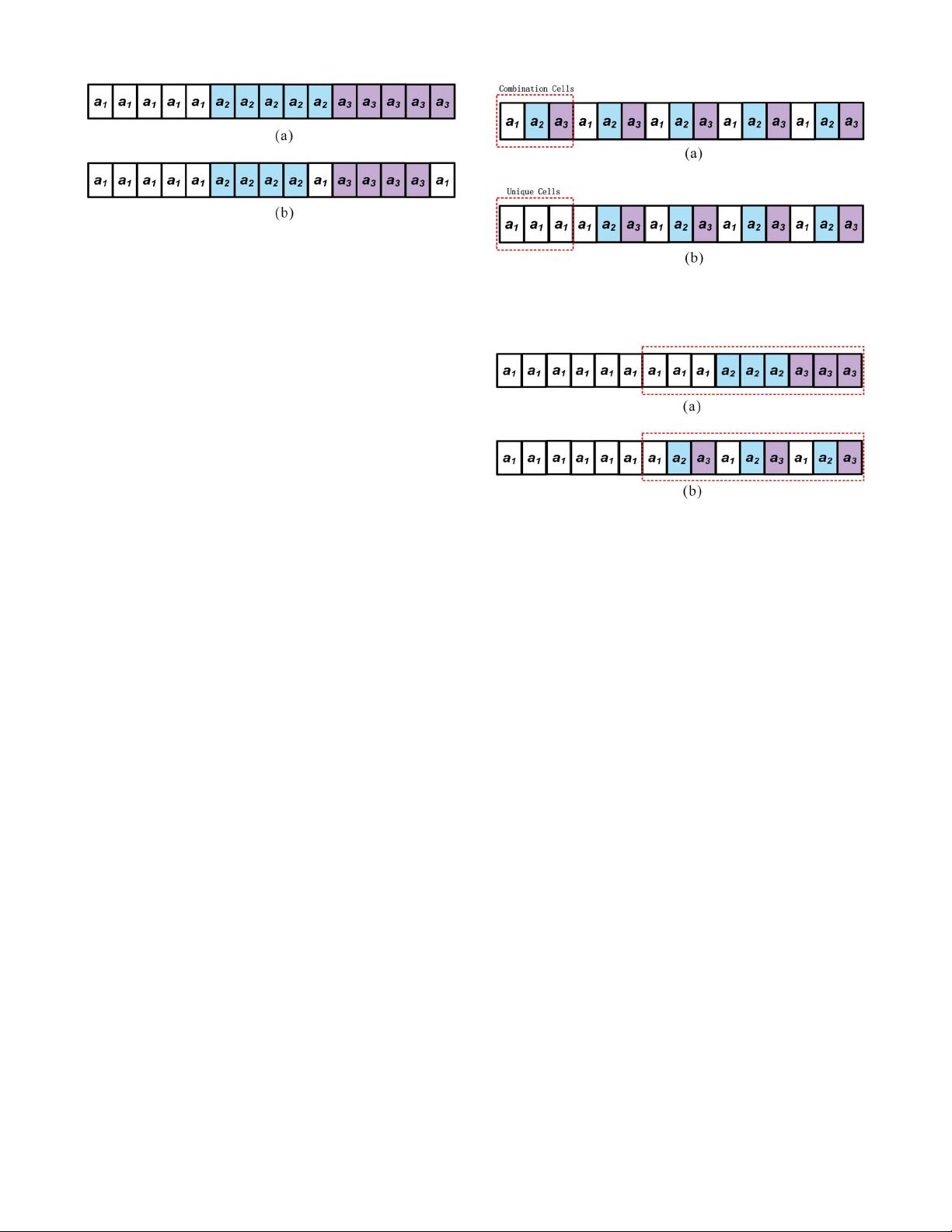
by .Fig.2 illustrates this update scheme. Each is consid-
ered as a probability cell (PC) shown in Fig. 2(a). Assume a
1
is
the estimated optimal action and positive response is received,
(r − 1) PCs are rewarded to a
1
and one PC is penalized for
other actions as shown in Fig. 2(b), respectively.
A. Fast Probability Update
In the proposed FDP
RI
, r PCs from each action are initially
composed as a combination (C) unit in Fig. 3(a). n C units
are initialized and equivalent to the one for DP
RI
in Fig. 2(a).
When an update occurs, a C unit is transformed to a unique (U)
unit which is composed r PCs of a
1
as shown in Fig. 3(b).
This updating result is equivalent to the one for DP
RI
as shown
in Fig. 2(b).
Fig. 3. FDP
RI
using r = 3andn = 5, a
1
is the estimated optimal action
and it received positive response. FDP
RI
(a) initialization and (b) rewarded
when C ≥ 1.
Fig. 4. U-C transformation: r = 3andn = 5. (a) All U units. (b) U-C
transformation.
Thus, the computational complexity to update the prob-
ability is reduced from O(r) to O(1) in FDP
RI
because a
type transformation from a C unit to a U unit can finish the
probability updating.
B. U-C Transformation
In FDP
RI
, n C units are initialized. When the probability
update continues, the C units can be used up and transformed
into the U units. Fig. 4 shows that r U units can be trans-
formed into r C units and they are equivalent. In this way, the
transformed C units can be available for the subsequent fast
probability update.
C. Reorganization
An action a
i
is active if its state probability p
i
(t) is nonzero.
When the state probability of an active action turns to be
zero as shown in Fig. 5(a), reorganization is triggered as
shown in Fig. 5(b). Reorganization lets ˜r =˜r − 1 and set
this action as nonactive state where ˜r is number of the active
actions and initially ˜r = r. Hence, the step size turns to be
= 1/(˜rn). The step size of the update scheme in FDP
RI
for p
m
(t) “increases” because more and more state probabili-
ties turn to be zero such that the number of the active actions
decreases with the learning process. It means that the step size
is “accelerated” along with the learning process. It is reason-
able because the number of times for which active actions
are selected increases and the reward probability estimation
of active actions becomes more and more accurate along with
the learning process.
Then the U-C transformation is called to transform U units
into C units for the subsequent fast probability updating. As
剩余10页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-05-29 上传
2021-08-18 上传
2009-06-05 上传
2021-04-25 上传
2021-05-09 上传
2021-04-10 上传

weixin_38662367
- 粉丝: 5
- 资源: 912
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
