Python PySpark:大规模数据处理与高级API探索
需积分: 10 127 浏览量
更新于2024-07-10
收藏 757KB DOCX 举报
Apache Spark 是一个强大的分布式数据处理框架,它提供了一个统一的分析引擎,适用于大规模数据处理,支持多种编程语言(Java、Scala、Python 和 R),以及针对图处理、SQL 查询、机器学习和流处理的高级工具。Spark SQL 是其核心组件之一,它不仅能够从Hadoop生态系统中的数据源读取数据,如HDFS,而且还可以通过JDBC接口连接到外部数据库,如PostgreSQL和MySQL。
Spark SQL 的JDBC连接功能是一个关键特性,它允许用户更方便地从各种数据库获取数据并以DataFrame形式处理,相比传统的JdbcRDD方法,这种方式提供了更好的性能和易用性。使用JDBC连接时,需要确保Spark类路径包含了所需的数据库JDBC驱动,例如,连接到PostgreSQL时,需要添加对应的JAR文件,并通过`--driver-class-path`参数指定。
在PySpark环境中,用户可以利用DataFrame API进行高效的数据操作。比如,`df.columns`用于获取DataFrame的列名,`df.show()`和`df.show(n)`用于查看DataFrame的前几行数据,其中`n`是一个整数。此外,`df.limit(n)`用于获取前n行数据,配合`show()`函数一起使用,可以直观地查看数据。直接选择某一列的值,可以通过`df.select("column_name")`来实现,这里的`"column_name"`是需要提取的列的名称。
Spark的强大之处在于其跨语言支持、数据处理的灵活性和性能优化,使得数据科学家和开发者能够方便地处理大规模数据,无论是实时流处理还是批处理,Spark都提供了强大的工具和接口。通过集成JDBC和其他数据库,Spark SQL进一步扩展了数据源的范围,使得数据集成更加无缝。在Pyspark中,API的易用性和灵活性使Python开发者也能充分利用Spark的能力。
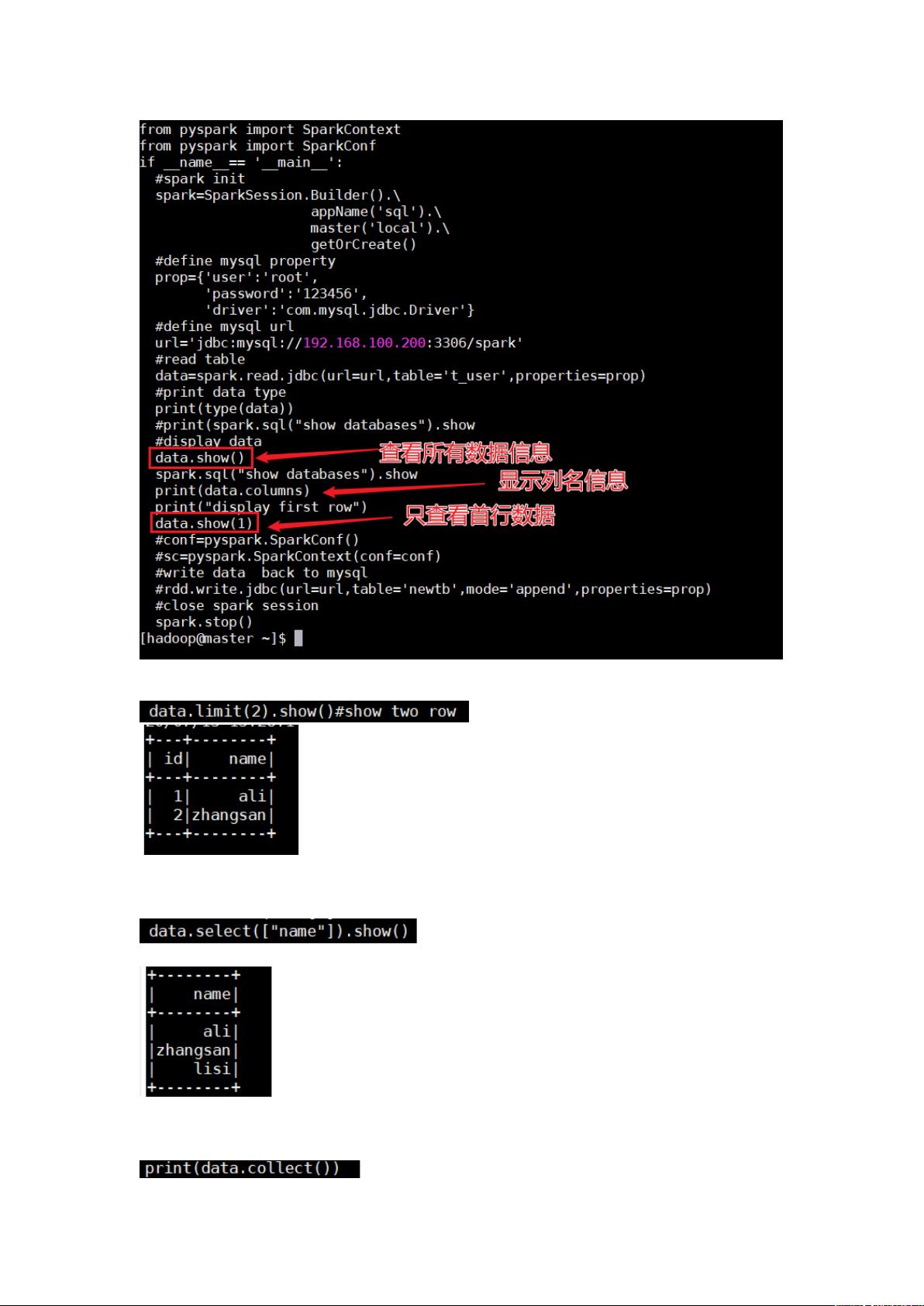
获取前 C 行数据œ2%//6C8里面传递一个整型,后面加上 ;68可以打印输出
获取列值 key df.select([“key”]) 传入参数写法 2%622/8后面加上 ;68可
以打印
执行之后输出结果如下
将 2 格式转换成列表 2%68
剩余23页未读,继续阅读
2021-12-11 上传
2021-11-12 上传
1545 浏览量
210 浏览量
2080 浏览量
125 浏览量
3419 浏览量
2024-03-08 上传
449 浏览量

qq_42048263
- 粉丝: 70
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







