Ubuntu环境下Hadoop单机与伪分布式搭建指南
需积分: 10 126 浏览量
更新于2024-07-19
收藏 1.25MB DOCX 举报
"在Ubuntu系统下搭建Hadoop,包括单机版和伪分布式环境的配置,整个过程耗时一学期。"
在Ubuntu系统中搭建Hadoop是大数据处理学习和实践的重要步骤,这里主要介绍如何在Ubuntu环境下配置Hadoop的单机模式和伪分布式模式。
首先,我们需要在虚拟机上安装Ubuntu操作系统。确保在D盘创建一个名为"hadoop"的文件夹,然后在VMware中创建一个新的虚拟机,使用Ubuntu 14.04的镜像文件进行自定义安装。安装过程中,要将网络适配器设置为桥接模式,以便虚拟机能够直接连接到物理网络。
接下来,创建一个名为"hadoop"的新用户,这是为了更好地管理和运行Hadoop服务。通过以下命令添加新用户,并赋予sudo权限:
```bash
sudo useradd -m -s /bin/bash hadoop
sudo passwd hadoop
sudo adduser hadoop sudo
```
记得在创建用户后,注销当前用户并使用新创建的"hadoop"用户登录。
在登录新用户后,我们需要更新Ubuntu的软件包管理器apt,以确保能安装最新的软件。在终端中输入:
```bash
sudo apt-get update
```
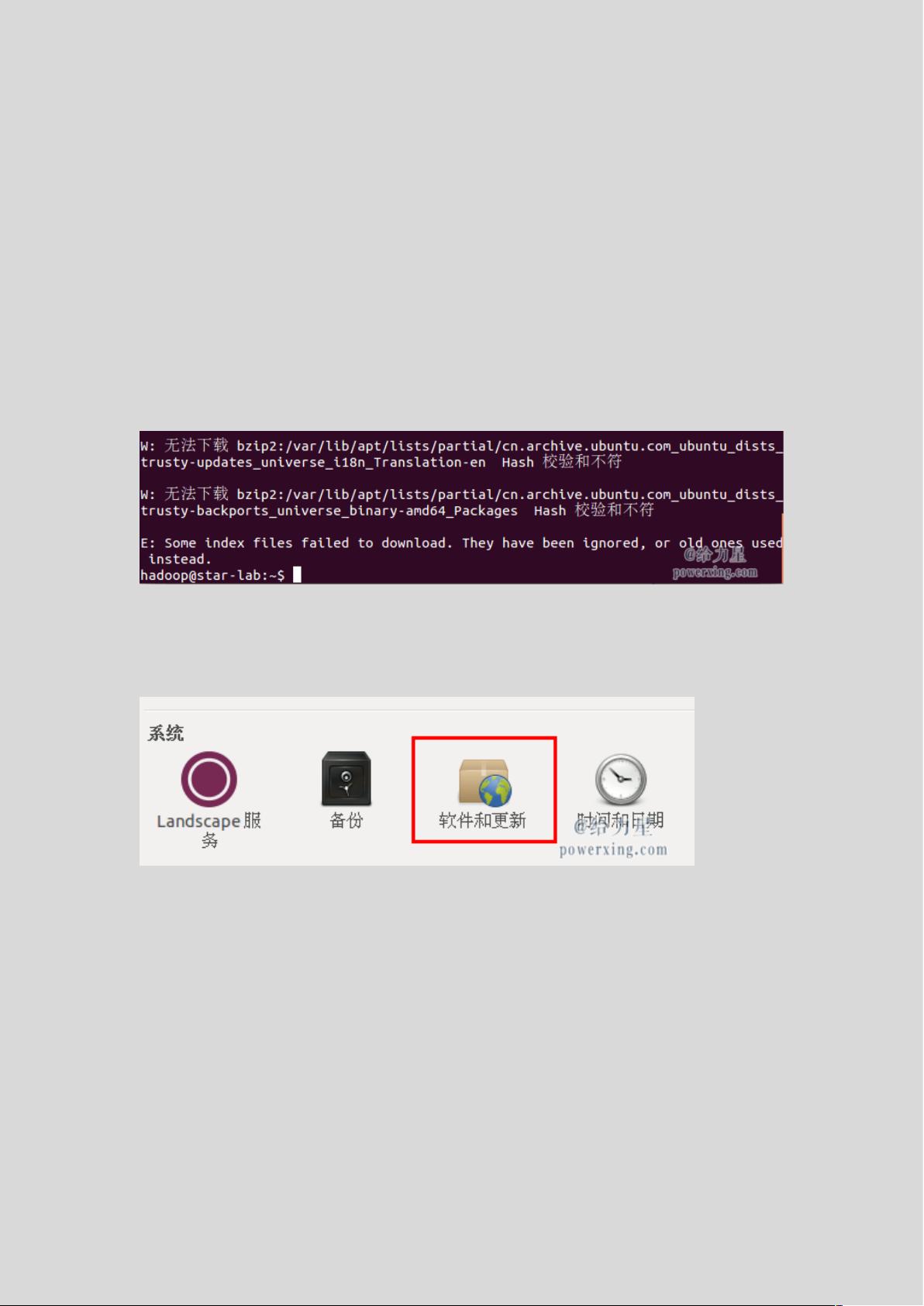
如果遇到"Hash校验和不符"的错误,可以考虑更改Ubuntu的软件源。例如,可以将源更换为阿里云的镜像服务器,这将提高软件包下载速度和稳定性。更改软件源的步骤包括在“软件和更新”设置中选择“其他”,然后选择“mirrors.aliyun.com”服务器,确认后更新软件源列表。
完成上述步骤后,我们可以开始安装Hadoop。首先,我们需要安装一些依赖库和工具,例如Java开发环境:
```bash
sudo apt-get install openjdk-8-jdk
```
下载Hadoop的tarball文件,将其解压到/home/hadoop目录下,并将解压后的目录设置为环境变量`HADOOP_HOME`。还需要配置Hadoop的配置文件`core-site.xml`、`hdfs-site.xml`和`mapred-site.xml`,以适应单机或伪分布式环境。
对于单机模式,只需修改`hdfs-site.xml`,设置`dfs.replication`为1,表示数据块只复制一份。
对于伪分布式模式,除了设置`dfs.replication`为1外,还需开启Hadoop守护进程,如NameNode、DataNode、YARN的Resource Manager和Node Manager等。
最后,通过以下命令启动Hadoop服务:
```bash
start-dfs.sh
start-yarn.sh
```
至此,Hadoop已经在Ubuntu环境中搭建完成,可以开始进行大数据处理的相关实验和学习了。这个过程中可能遇到的常见问题包括权限问题、网络配置错误以及配置文件错误,需要根据日志信息逐步排查解决。
2.1.3 更新 apt
用 hadoop 用户登录后,我们先更新一下 apt,后续我们使用 apt 安装软件,如
果没更新可能有一些软件安装不了。按 ctrl+alt+t 打开终端窗口,执行如下命令:
hadoop@hadoop-virtual-machine:~$ sudo apt-get update
若出现如下 “Hash 校验和不符” 的提示,可通过更改软件源来解决。若没有该问
题,则不需要更改
如何更改软件源
首先点击左侧任务栏的【系统设置】(齿轮图标),选择【软件和更新】
Ubuntu 更新软件源点击 “下载自” 右侧的方框,选择【其他节点】
剩余22页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2012-11-11 上传
2014-05-06 上传
2018-11-05 上传
2013-03-18 上传
2021-09-19 上传

qisoft1213
- 粉丝: 8
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- typora-themes:我的Typora主题资料库
- 摇滚音乐娱乐网站模板是一款大气单页HTML5网站模板下载。.zip
- 1ere-evaluation-php-sql-site-annonces-immobilieres
- 演示
- Particulate matter Korea-crx插件
- Presenca:用于对Uberhub CodeClub项目进行学术控制的网站。 用Flask制作-Python的微框架-这对组织很有帮助,它经常被成百上千的学生使用
- 清新的韩国风格自然风景下载PPT模板
- Titanic_ML_Competitons:使用Titanic Dataset的ML项目,这是Kaggle的入门比赛(描述为土耳其语,因为该比赛有很多英语来源)
- 工业建筑施工方案模板--余杭区临平塘栖供水二期某水厂工程施工组织设计
- car-rental-php:PHP中的汽车租赁项目
- cppcoffee.github.io:我的github页面
- 红色艺术花纹背景下载PPT模板
- historias_medicas
- block-similarity:通过相似性尝试搜索块
- 简历-求职简历-word-文件-简历模版免费分享-应届生-高颜值简历模版-个人简历模版-简约大气-大学生在校生-求职-实习
- 数据库-应用程序:.BinarySearchTREE-数据库-应用程序
