Linux内核中的无锁编程探索
需积分: 10 132 浏览量
更新于2024-07-26
收藏 396KB PDF 举报
"透过Linux内核看无锁编程"
在多核多线程的现代计算环境中,无锁编程已经成为提升性能和解决并发问题的关键技术。Linux内核,作为世界上最复杂且广泛应用的并行程序之一,引入了无锁编程技术,为开发者提供了一个理想的实践和学习平台。本文将基于Linux 2.6.10版本,探讨无锁编程在多核环境中的应用和优势。
无锁编程,顾名思义,是指在编程中避免使用传统的锁机制来保护共享数据,以减少或消除线程间的同步等待。这种技术的主要目标是提高并发性能,减少上下文切换的开销,以及避免与锁相关的死锁、活锁和优先级反转等问题。
传统的同步机制,如互斥量(mutex)、信号量(semaphore)等,属于阻塞型同步。当一个线程试图访问已被其他线程持有的共享数据时,它会被迫进入等待状态,直到持有锁的线程释放资源。然而,这样的阻塞方式可能导致线程饥饿(starvation),死锁,以及效率低下的并发执行。
非阻塞型同步,作为替代方案,避免了线程的阻塞等待。它主要分为两类:Wait-free和Lock-free。
1. Wait-free算法保证了每个线程都能在有限的步骤内完成其操作,无论其他线程如何执行。理论上,Wait-free算法应是无饥饿的,但实际实现中,由于线程间的竞争,仍可能存在饥饿问题,且随着线程数量的增加,内存消耗会显著增大。
2. Lock-free算法则保证了系统作为一个整体总能向前推进,即使某个线程可能被无限期地延迟,系统内的其他线程仍然可以继续执行。Lock-free比Wait-free更宽松,因此在实现上通常更容易,但仍然需要精心设计以避免线程优先级反转和其他并发问题。
在Linux内核中,无锁编程的应用包括了数据结构的更新,例如无锁队列和无锁栈,以及并发原语的实现,如原子操作(atomic operations)和自旋锁(spinlocks)。这些技术在处理高速网络I/O、中断处理等高性能场景中发挥了重要作用。
无锁编程虽然具有很多优点,但也带来了更高的设计和实现难度。程序员需要对底层硬件和并发控制有深入理解,才能有效利用无锁技术。此外,无锁算法往往需要更精细的并发控制,可能导致代码变得复杂且难以调试。
透过Linux内核,我们可以看到无锁编程在解决并发问题上的潜力,以及它在优化多核系统性能上的重要角色。理解和掌握无锁编程技术,对于任何想要在Linux环境下进行高性能并行编程的开发者来说,都是至关重要的。
改的假设,采用了类似于数据库的 commit-retry 的模式。当同步冲突出现的
机会很少时,这种假设能带来较大的性能提升。
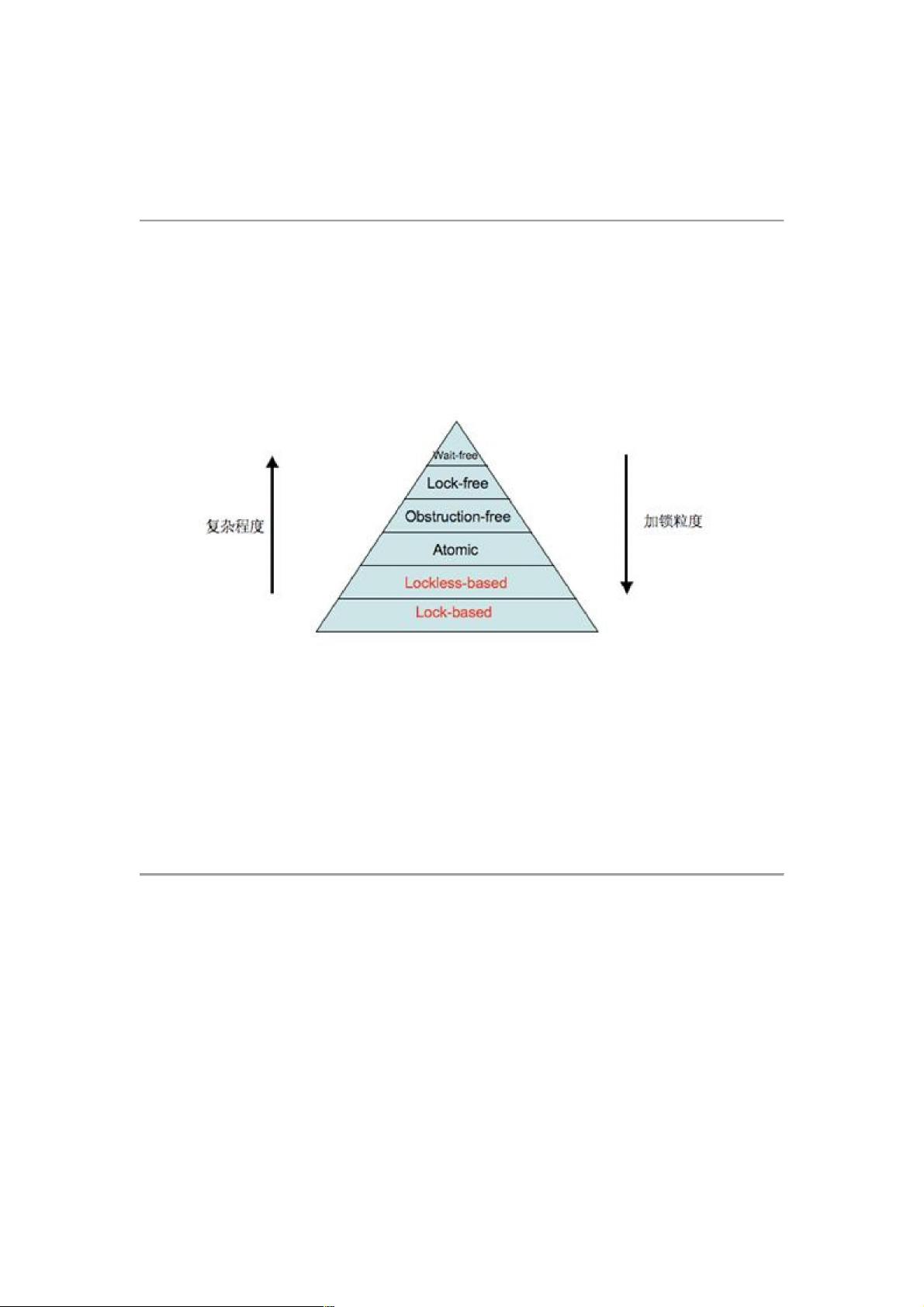
加锁的层级
根据复杂程度、加锁粒度及运行速度,可以得出如下图所示的锁层级:
图 1. 加锁层级
其中标注为红色字体的方案为 Blocking synchronization,黑色字体为
Non-blocking synchronization。Lock-based 和 Lockless-based 两者之
间的区别仅仅是加锁粒度的不同。图中最底层的方案就是大家经常使用的
mutex 和 semaphore 等方案,代码复杂度低,但运行效率也最低。
Linux 内核中的无锁分析
Linux 内核可能是当今最大最复杂的并行程序之一,它的并行主要来至于中断、
内核抢占及 SMP 等。内核设计者们为了不断提高 Linux 内核的效率,从全局
着眼,逐步废弃了大内核锁来降低锁的粒度;从细处下手,不断对局部代码进行
优化,用无锁编程替代基于锁的方案,如 seqlock 及 RCU 等;不断减少锁冲
突程度、降低等待时间,如 Double-checked locking 和原子锁等。
剩余15页未读,继续阅读
2011-05-26 上传
2022-05-24 上传
298 浏览量
141 浏览量
2010-12-07 上传
112 浏览量
2018-12-29 上传
点击了解资源详情

linux_Freax
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- hetseq:杂交序列
- Realm-createOrUpdateObjectFromJson-Test
- JEK
- Krikkit-开源
- smart-datatable:角度智能表
- projects
- network:为ndla组件提供通用网络功能的库
- 20200331-2020年中国公关行业概览.rar
- pintos4
- torch_spline_conv-1.2.1-cp39-cp39-linux_x86_64whl.zip
- KornaXx-开源
- 生活服务网站模版
- lapstore
- frontend-clientes
- 62162-cat-energy-22:凯瑟琳
- MATLAB实现基于LVQ神经网络的乳腺肿瘤诊断分类代码
