MapReduce与Spark实现Cube计算详解
需积分: 12 105 浏览量
更新于2024-07-08
收藏 3.44MB PDF 举报
本资源主要探讨了使用MapReduce和Spark进行Cube计算的原理和流程,特别是在Apache Kylin框架下的应用。Kylin是一个开源的、分布式的分析型数据库,旨在提供亚秒级的Hadoop之上大数据查询性能。
在Kylin架构中,有两个主要的工作负载:构建Cube和查询Cube。构建Cube是一个ETL(提取、转换、加载)过程,涉及到大量计算和磁盘I/O,通常需要几分钟到几小时的时间,适合离线处理。而查询Cube则对内存要求较高,能够实现在线查询,延迟低至毫秒到秒级别。
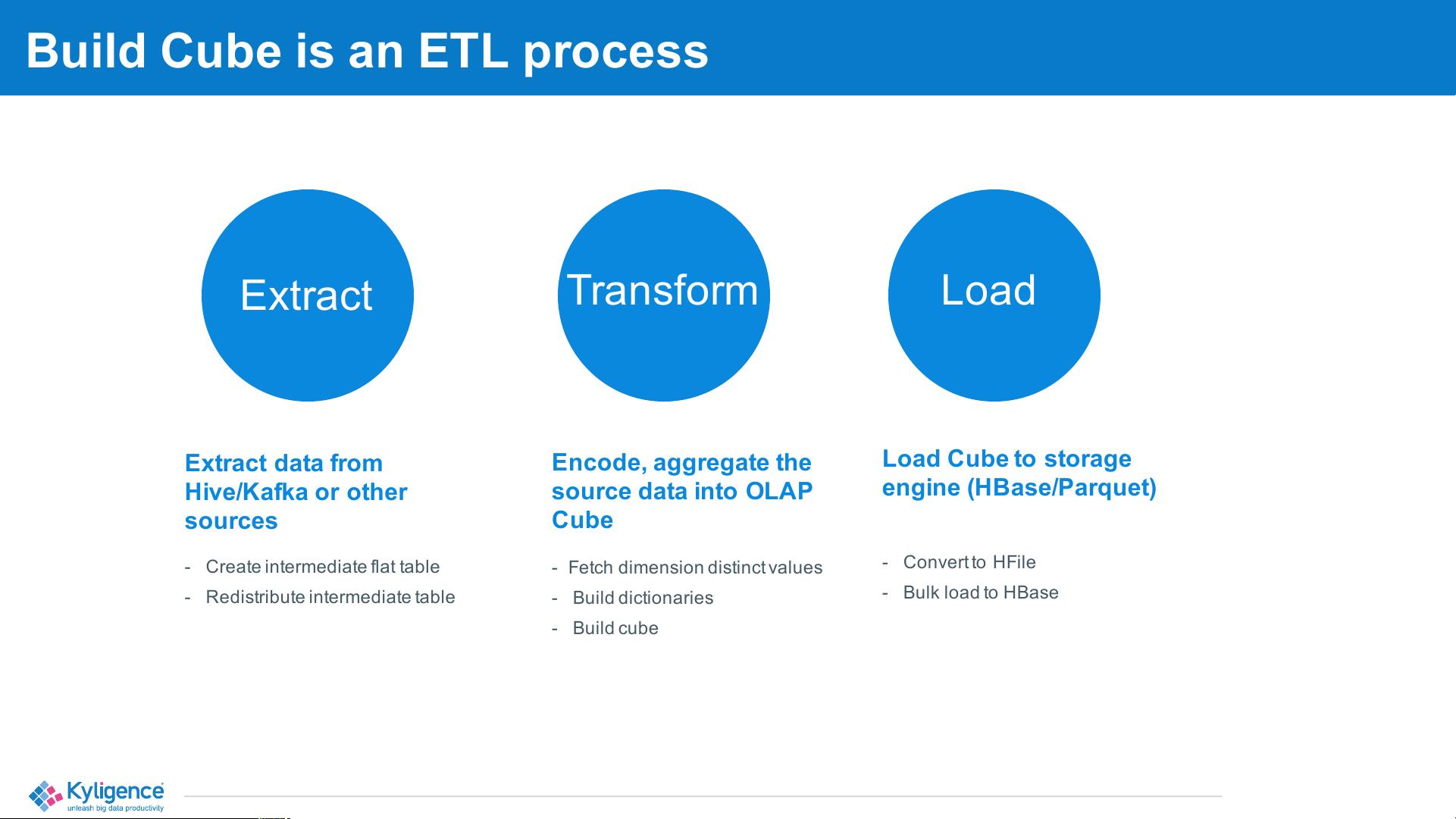
构建Cube的过程包括以下几个步骤:
1. 提取数据:从Hive、Kafka或其他数据源提取数据。
2. 转换数据:生成维度的唯一值,建立字典,并对源数据进行编码和聚合,将数据转换成适合OLAP的Cube形式。
3. 加载数据:将转换后的数据转换为HFile格式,然后批量加载到HBase或Parquet等存储引擎中。此外,还会创建一个中间平坦表,并重新分布这个中间表,以便于查询优化。
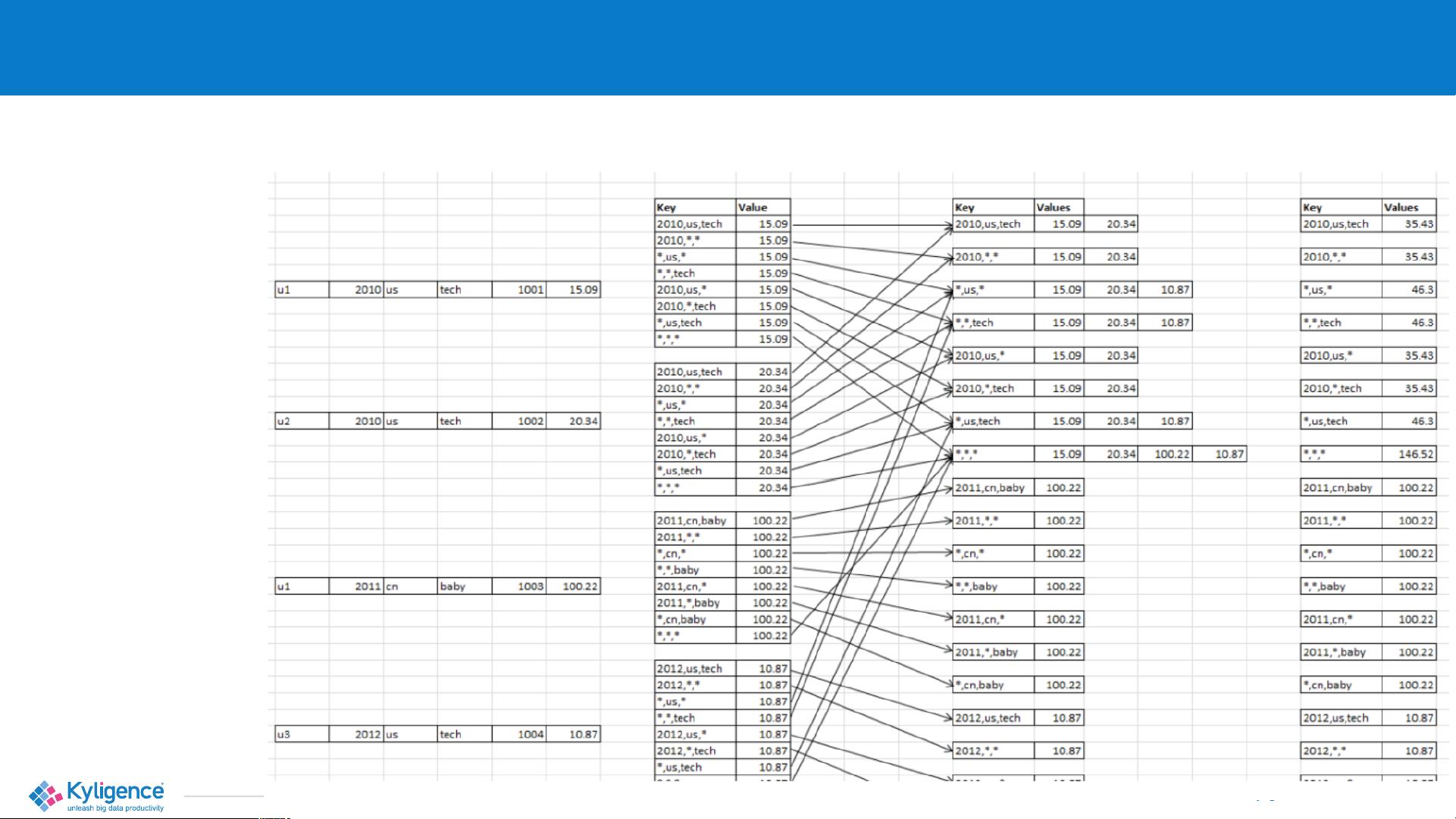
以一个包含6列、3个维度(年份、国家、类别)和1个度量(价格总和)的小表为例,Kylin会生成8个cuboids。Cuboids是Cube的基本构建块,由维度的不同组合构成。每个cuboid对应一种特定的分组,通过预先计算和存储这些分组的聚合结果,可以极大地加速查询响应时间。
当使用MapReduce进行Cube计算时,数据会被分割成多个块,每个块在不同的节点上并行处理,然后将结果合并。而Spark作为更现代的计算框架,提供了内存计算的优势,能够在数据处理过程中减少磁盘I/O,提高处理速度。
MapReduce和Spark在Kylin中的应用使得大规模数据集的Cube计算成为可能,为快速、高效的OLAP查询提供了基础。无论是对于大数据分析师还是数据工程师,理解这一过程对于优化数据仓库性能和提升用户体验都至关重要。
© Kyligence Inc. 2019, Confidential.
Build Cube is an ETL process
- Fetch dimension distinct values
- Build dictionaries
- Build cube
Encode, aggregate the
source data into OLAP
Cube
- Convert to HFile
- Bulk load to HBase
Load Cube to storage
engine (HBase/Parquet)
- Create intermediate flat table
- Redistribute intermediate table
Extract data from
Hive/Kafka or other
sources
Extract
Transform Load
剩余25页未读,继续阅读
2021-10-14 上传
2019-10-11 上传
2020-03-02 上传
2021-12-23 上传
2021-08-31 上传
2018-10-10 上传
2022-11-17 上传
点击了解资源详情
点击了解资源详情









