CVPR18 AVOD论文详解:3D目标检测与自动驾驶的深度解析
本资源是一份关于"Joint 3D Proposal Generation and Object Detection from View Aggregation"的论文讲解PPT,该论文于2018年在CVPR上发表,聚焦于3D目标检测与自动驾驶领域的研究。AVOD(Aggregate View Object Detection)是论文的核心概念,它提出了一种结合多视角信息的方法来提高自动驾驶中的物体检测性能。
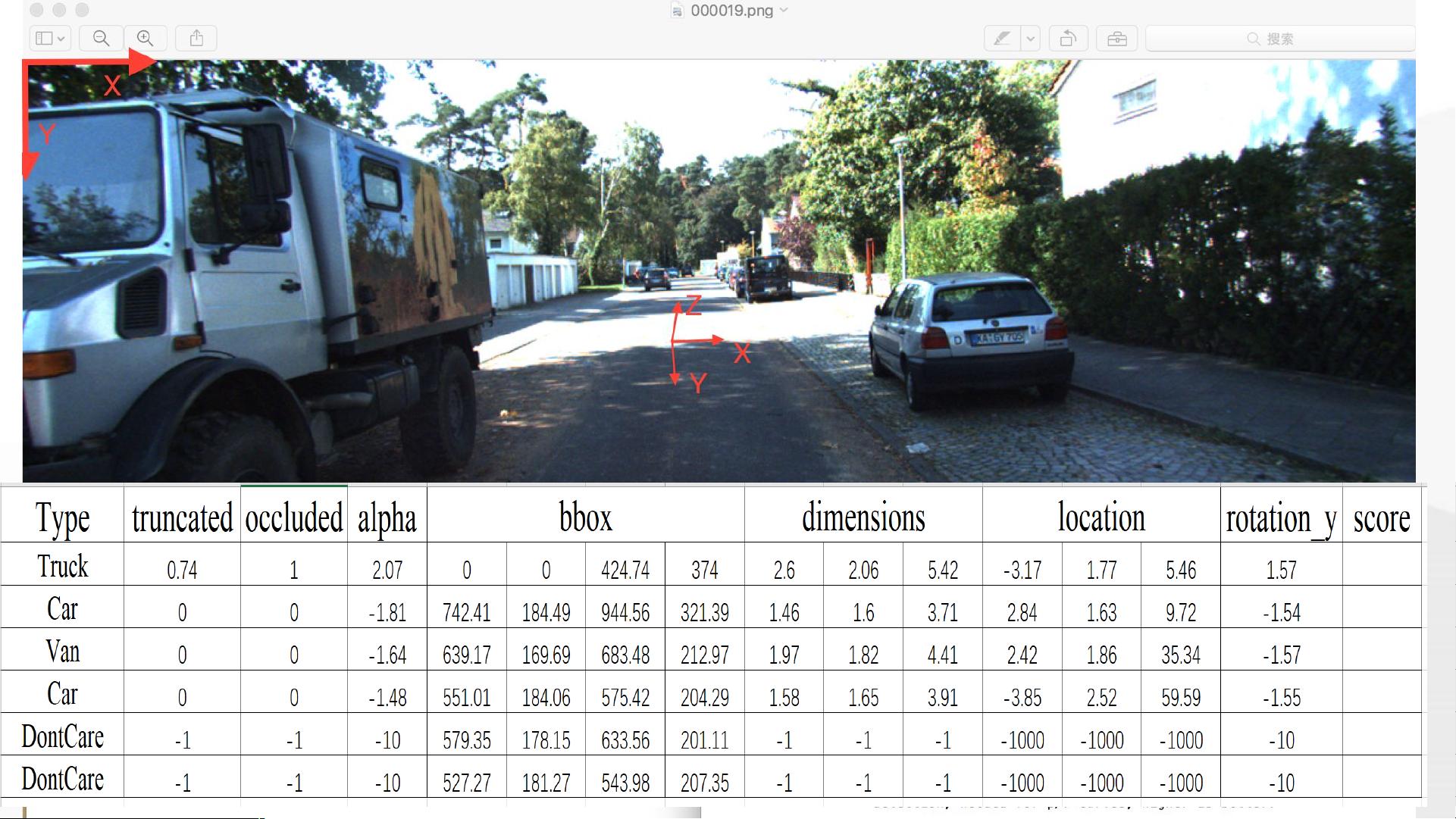
AVOD论文的主要背景是Kitti Object Detection Dataset,一个广泛用于3D视觉研究的公开数据集。Kitti数据集包含来自2个PointGray Flea2黑白相机、2个彩色相机、1个Velodyne HDL-64E旋转激光雷达、1个OXTS RT300惯性导航和GPS定位系统,以及多种镜头,支持多种任务,如立体视觉、光流估计、视觉里程计、3D对象检测和跟踪。其重点在于3D对象检测,特别是对车辆(Van)、汽车、卡车、行人、骑自行车的人、有轨电车和其它类别进行检测。
在Kitti数据集的3D对象检测标准中,对于不同类别的对象设置了不同的阈值:对于汽车,最小包围盒高度要求为40像素,完全可见时的遮挡级别不超过15%,而对于行人和骑自行车的人,这些标准较低,分别为25像素和50%的遮挡。评估难度分为三个级别:Easy、Moderate和Hard,分别对应不同的遮挡程度和最小包围盒高度。
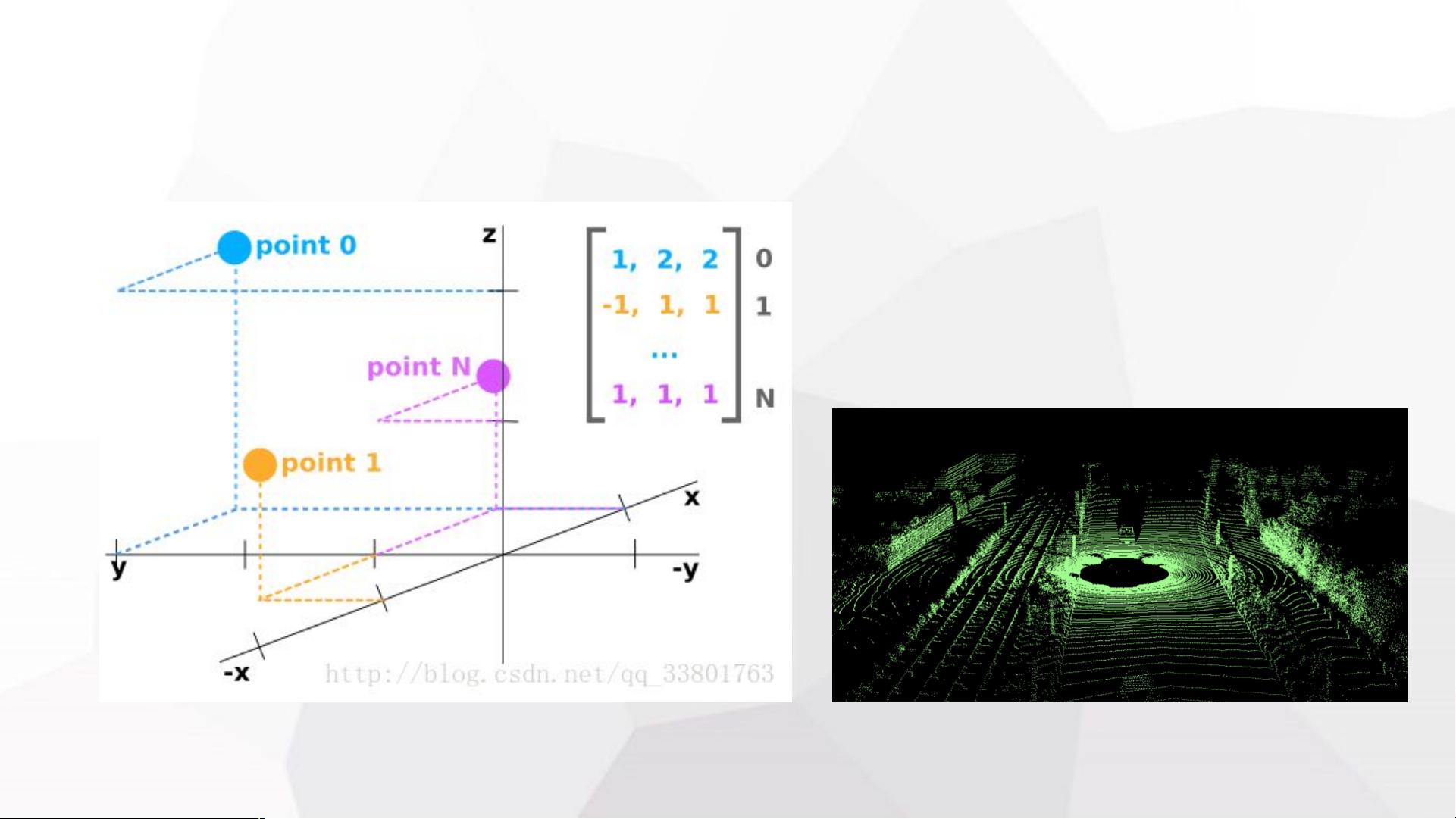
论文中介绍了一种关键步骤,即从激光雷达点云数据通过特定投影公式将三维坐标(x, y, z, reflectivity)映射到图像坐标系中。这涉及到相机矩阵P2、R0_rect(传感器坐标系到世界坐标系的转换)、Tr_velo_to_cam(激光雷达坐标系到相机坐标系的转换)等参数的应用。这种转换有助于整合来自不同传感器的信息,从而生成更准确的3D目标候选区域,并进行后续的检测和识别。
这份PPT对于研究生和博士生在研究3D计算机视觉、自动驾驶算法,尤其是AVOD方法的实现与优化具有很高的参考价值。通过深入理解论文内容和演示文稿中的技术细节,研究者可以提升自己在复杂环境下的3D感知能力,推动自动驾驶技术的进一步发展。
剩余30页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2020-11-20 上传
489 浏览量
2022-04-21 上传

qq_26919935
- 粉丝: 82
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







