Apache Flink 1.7 中文文档详解:从入门到高级特性
需积分: 9 141 浏览量
更新于2024-07-16
收藏 11.27MB PDF 举报
Apache Flink 1.7 中文文档是一份详尽的指南,涵盖了Flink的大数据处理技术。Flink是一款开源的流处理框架,以其容错性、低延迟和高吞吐量而闻名。文档主要分为以下几个部分:
1. **概念**:这部分介绍了Flink的数据流编程模型,强调了其与传统批处理的区别,以及Flink如何处理连续和断断续续的数据流。
2. **分布式运行时环境**:讲述了Flink如何在分布式环境中部署和运行,包括本地安装教程和在Windows上的运行指导。
3. **教程**:
- **DataStream API教程**:详细讲解了Flink的核心API,如事件时间(event time)和处理时间(processing time)的概念,以及如何创建、转换和处理数据流。
- **Setup教程**:涉及项目的构建设置,包括Java和Scala项目模板,以及配置依赖关系和连接器。
4. **活动时间/生成时间戳/水印**:这部分讨论了Flink如何处理事件时间的逻辑,如预定义的时间戳提取器和水印机制,这对于正确处理乱序数据至关重要。
5. **状态与容错**:介绍Flink的状态管理和容错机制,如状态运行、广播状态模式,以及检查点功能,确保系统在故障发生时能够恢复。
6. **算子与操作**:
- **视窗**:讲解了窗口操作,如滑动窗口和会话窗口,常用于时间相关的聚合分析。
- **Join**:详细说明了Flink的内连接、外连接等Join操作,支持复杂的关联分析。
- **过程函数(低级算子操作)**:深入剖析了Flink提供的高级算子,如映射、过滤和扁平化等。
7. **外部数据访问**:探讨了Flink如何通过异步I/O与各种数据源(如Kafka、Cassandra、Amazon Kinesis Streams和Elasticsearch)进行高效交互。
8. **错误处理和数据可靠性**:强调了数据源和接收器的容错保障,确保数据在传输过程中的完整性。
整个文档覆盖了从基础到高级的概念和技术细节,对想要学习或使用Flink处理大数据流的应用开发者来说是一份非常宝贵的参考资料。无论是Java还是Scala开发者,都能在这个文档中找到所需的信息来构建实时和批量处理系统。
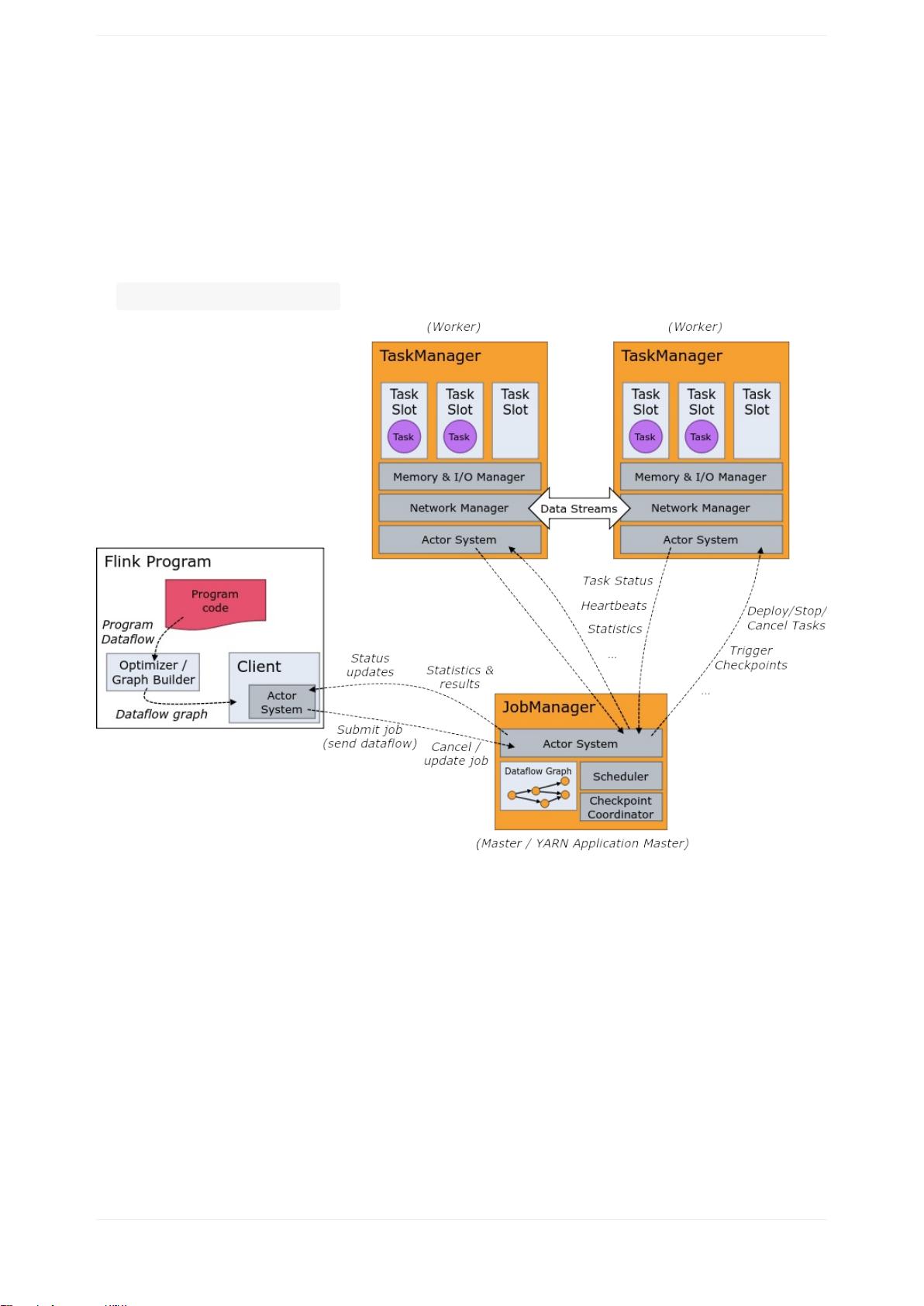
必须始终至少有一个TaskManager。
JobManagers和TaskManagers可以通过多种方式启动:作为独立集群直接在计算
机上,在容器中,或由YARN或Mesos等资源框架管理。TaskManagers连接到
JobManagers,宣布自己可用,并被分配工作。
该客户端是不运行时和程序执行的一部分,而是被用来准备和发送的数据流的
JobManager。之后,客户端可以断开连接或保持连接以接收进度报告。客户端既
可以作为触发执行的Java/Scala程序的一部分运行,也可以在命令行进程中运
行 ./bin/flinkrun...。
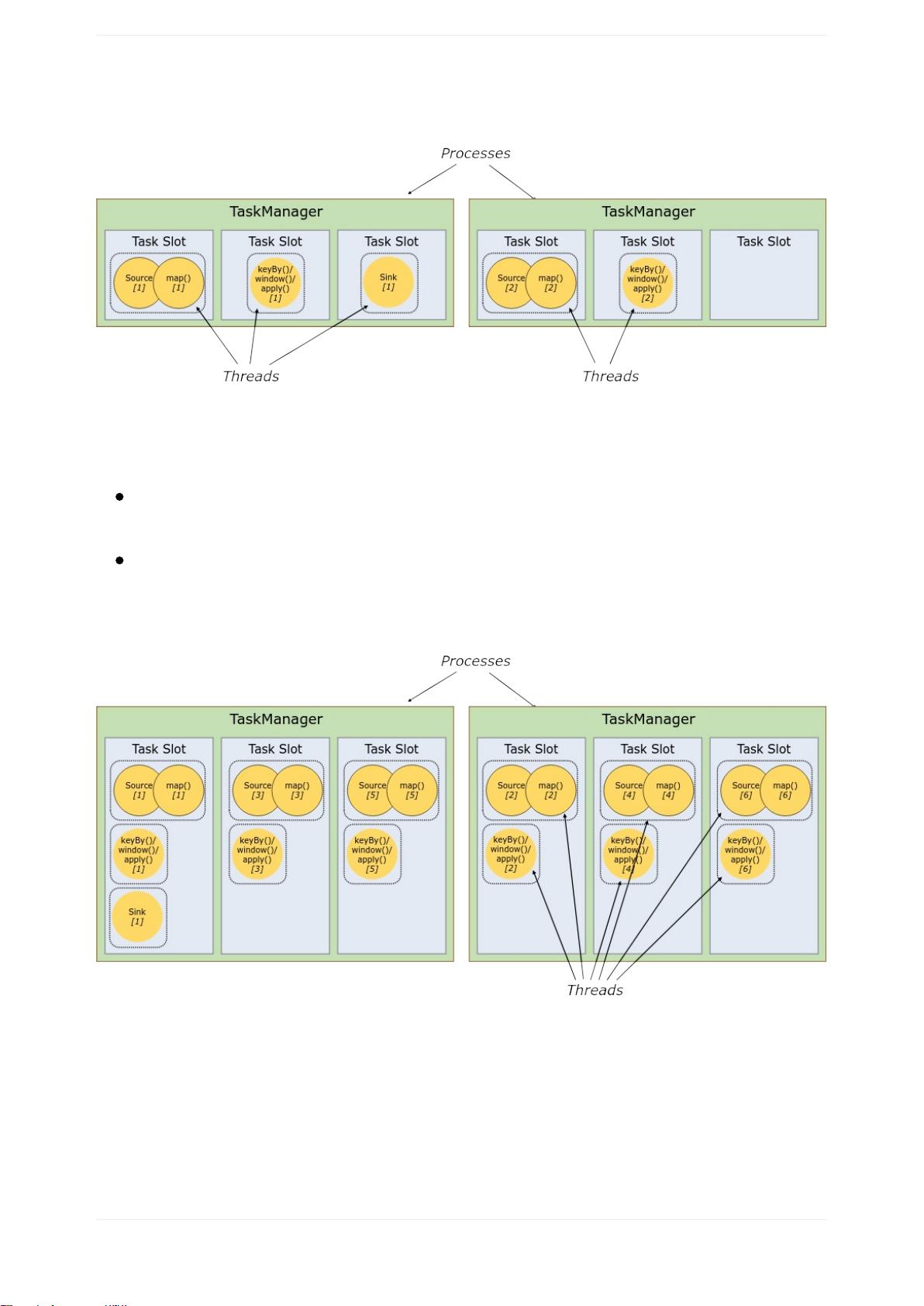
任务槽和资源
每个worker(TaskManager)都是一个JVM进程,可以在不同的线程中执行一个或
多个子任务。为了控制工人接受的任务数量,工人有所谓的任务槽(至少一个)。
每个任务槽代表TaskManager的固定资源子集。例如,具有三个插槽的
TaskManager将其1/3的托管内存专用于每个插槽。切换资源意味着子任务不会与来
自其他作业的子任务竞争托管内存,而是具有一定数量的保存托管内存。请注意,
此处不会发生CPU隔离;当前插槽只分离任务的托管内存。
通过调整任务槽的数量,用户可以定义子任务如何相互隔离。每个TaskManager有
一个插槽意味着每个任务组在一个单独的JVM中运行(例如,可以在一个单独的容
器中启动)。拥有多个插槽意味着更多子任务共享同一个JVM。同一JVM中的任务
分布式运行时环境
16



剩余1168页未读,继续阅读
2021-05-28 上传
2021-03-05 上传
2019-06-12 上传
2021-11-14 上传
2023-09-05 上传
2020-11-16 上传
2023-05-12 上传
2023-03-04 上传

萧曵丶
- 粉丝: 2617
- 资源: 264
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
