预训练模型演进:从Word Embedding到ChatGPT的历史
下载需积分: 2 | PDF格式 | 17.11MB |
更新于2024-06-26
| 201 浏览量 | 举报
本文档深入探讨了从word embedding到chatGPT预训练模型的发展历程,展示了自然语言处理领域预训练技术的演变及其在实际应用中的关键作用。预训练模型起源于迁移学习的概念,尤其是通过深度学习在诸如图像识别领域的成功应用,启发了将其扩展到自然语言处理中。早期的预训练方法包括浅层加载(Frozen)和深层微调(Fine-Tuning),前者保持一部分模型参数不变,后者则允许模型在新任务上持续学习。
Word Embedding作为NLP的早期预训练技术,核心思想是将词语转化为固定维度的向量,以便计算机理解其语义和上下文关系。这个向量表示是基于词语与其周围上下文的统计学习,可以用于计算词语之间的相似度,例如判断"man"和"woman"相较于"man"和"app"之间的相似性。这种技术显著提升了下游任务的性能,如情感分析、机器翻译和文本分类等。
随着深度学习的发展,预训练模型如BERT(Bidirectional Encoder Representations from Transformers)引入了Transformer架构,能够捕捉词语的双向上下文信息,极大地提高了模型的表达能力和泛化能力。BERT在大规模文本数据集上进行预训练,然后在特定任务上进行微调,显著改善了NLP任务的表现。
从word embedding到BERT,再到更先进的预训练模型如GPT系列(如GPT-2、GPT-3和ChatGPT),这些模型的出现不仅提升了自然语言理解和生成的能力,还推动了对话系统、文本生成等领域的创新。ChatGPT作为最新一代的预训练语言模型,以其强大的语言生成和对话交互能力,正在重新定义人机交互的方式。
总结来说,预训练模型的发展经历了从简单词嵌入到复杂架构的转变,通过大规模的数据预训练和微调策略,它们在各种NLP任务中扮演了至关重要的角色,并且随着技术的进步,预训练模型的性能和应用场景将持续扩展和深化。理解这些演变对于NLP研究者和从业者来说至关重要,因为他们需要紧跟技术趋势,利用预训练模型的优势,解决实际问题并推动行业的进步。
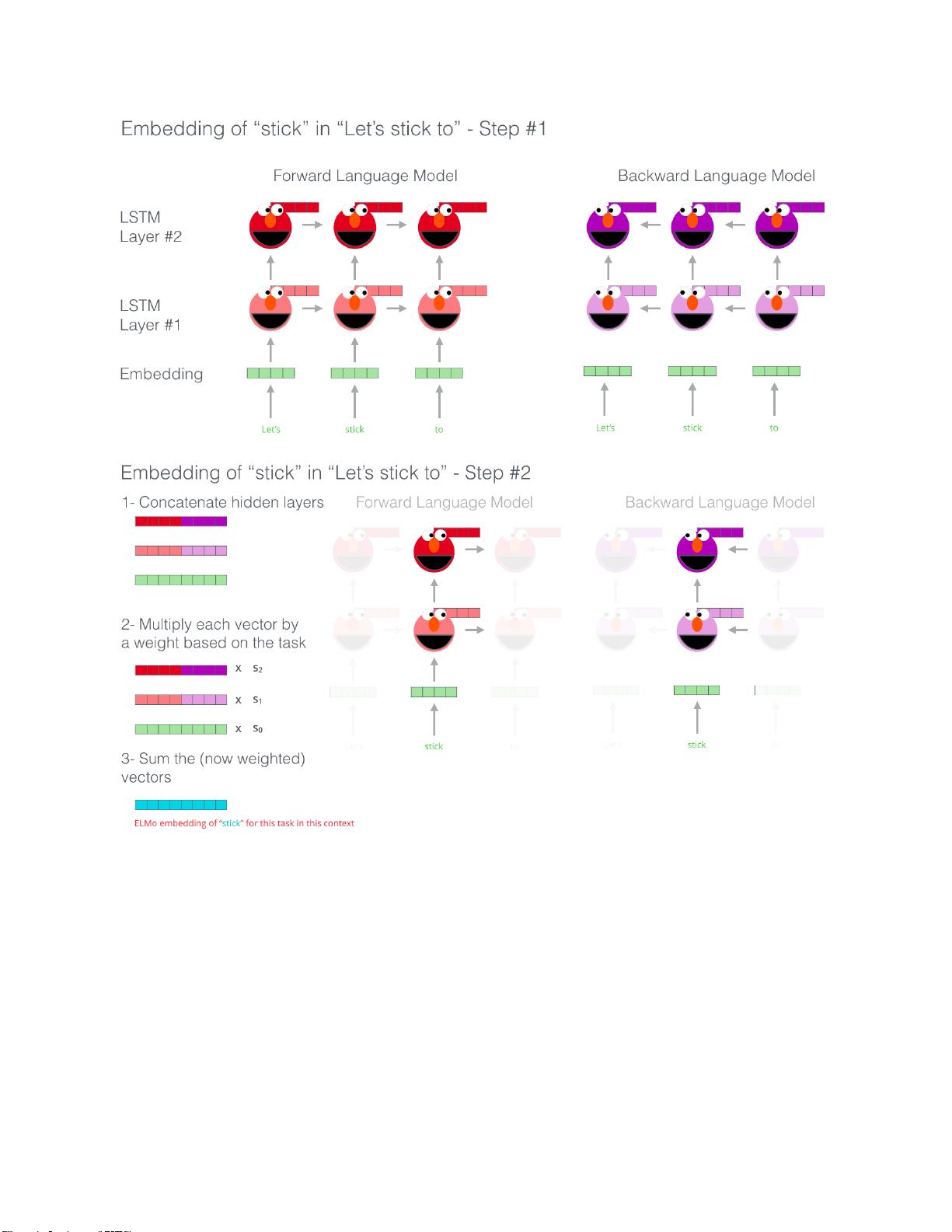
如果训练好这个网络后,输入一个新句子,句子中每个单词都能得到对应的三个Embedding:
(1)最底层,单词的Word Embedding
(2)往上第一层LSTM中对应单词位置的Embedding,这层编码单词的句法信息更多一些;
(3)往上第二层LSTM中对应单词位置的Embedding,这层编码单词的语义信息更多一些。
将整个句子作为预训练好的ELMO网络的输入,这样每个单词通过预训练ELMo网络得到三个
Embedding,加权求和(权重可以学习得到)将三个Embedding整合成一个,作为补充的新特征给
下游任务使用。
2023-04

剩余45页未读,继续阅读
相关推荐





中本王
- 粉丝: 175
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现ART与SART算法在医学CT重建中的应用
- S2SH整合版:快速搭建Struts2+Spring+Hibernate开发环境
- 托奇卡项目团队成员介绍
- 提升外链发布效率的SEO推广神器——搜易达网络推广大师v2.035
- C#打造简易记事本应用详细教程
- 探索虚拟现实地图VR的奥秘
- iOS模拟器屏幕截图新工具
- 深入解析JavaScript在生活应用开发中的运用
- STM32F10x函数库3.5中文版详解与应用
- 猎豹浏览器v6.0.114.13396 r1:安全防护与网购敢赔
- 掌握JS for循环输出的最简洁代码技巧
- Java入门教程:TranslationFileGenerator快速指南
- OpenDDS3.9源码解析及最新文档指南
- JavaScript提示框插件:鼠标滑过显示文章摘要
- MaskRCNN气球数据集:优质图像识别资源
- Laravel日志查看器:实现Apache多站点日志统一管理
