Hadoop1全步骤安装指南
需积分: 10 147 浏览量
更新于2024-07-22
收藏 3.21MB PDF 举报
"Hadoop1安装全套手顺"
在学习和使用大数据处理框架Hadoop时,安装过程往往是初学者面临的第一道难关。本文提供了一套详细的Hadoop1安装步骤,旨在帮助用户避免安装过程中可能遇到的问题,减少摸索的时间。
首先,安装Hadoop1需要满足一定的硬件和软件要求。硬件上,至少需要6GB的内存和100GB的硬盘空间。在软件方面,推荐使用虚拟机软件VMware,因为它具有较高的虚拟化能力。选择的操作系统是CentOS-6.5-x86_64,这是一个常见的Linux发行版,适合服务器环境。此外,还需要远程连接工具如xshell4,便于在Windows主机上操作Linux虚拟机。Hadoop版本为hadoop-1.0.4,以及Java开发工具包JDK,此处推荐的是jdk-6u32-linux-x64。
安装过程首先涉及到虚拟机的设置。创建一个namenode节点,即Hadoop集群的主节点,然后可以复制这个节点来创建其他slave节点。虚拟机的安装遵循一般的Linux安装流程,选择"Install or upgrade an existing system"选项,然后跳过硬件检测。安装完成后,使用相同的方式安装其他slave节点。对于熟悉Linux安装的用户,可以考虑通过克隆虚拟机来快速创建slave节点,但需要注意的是,克隆后的虚拟机需要重新生成MAC地址以避免冲突。
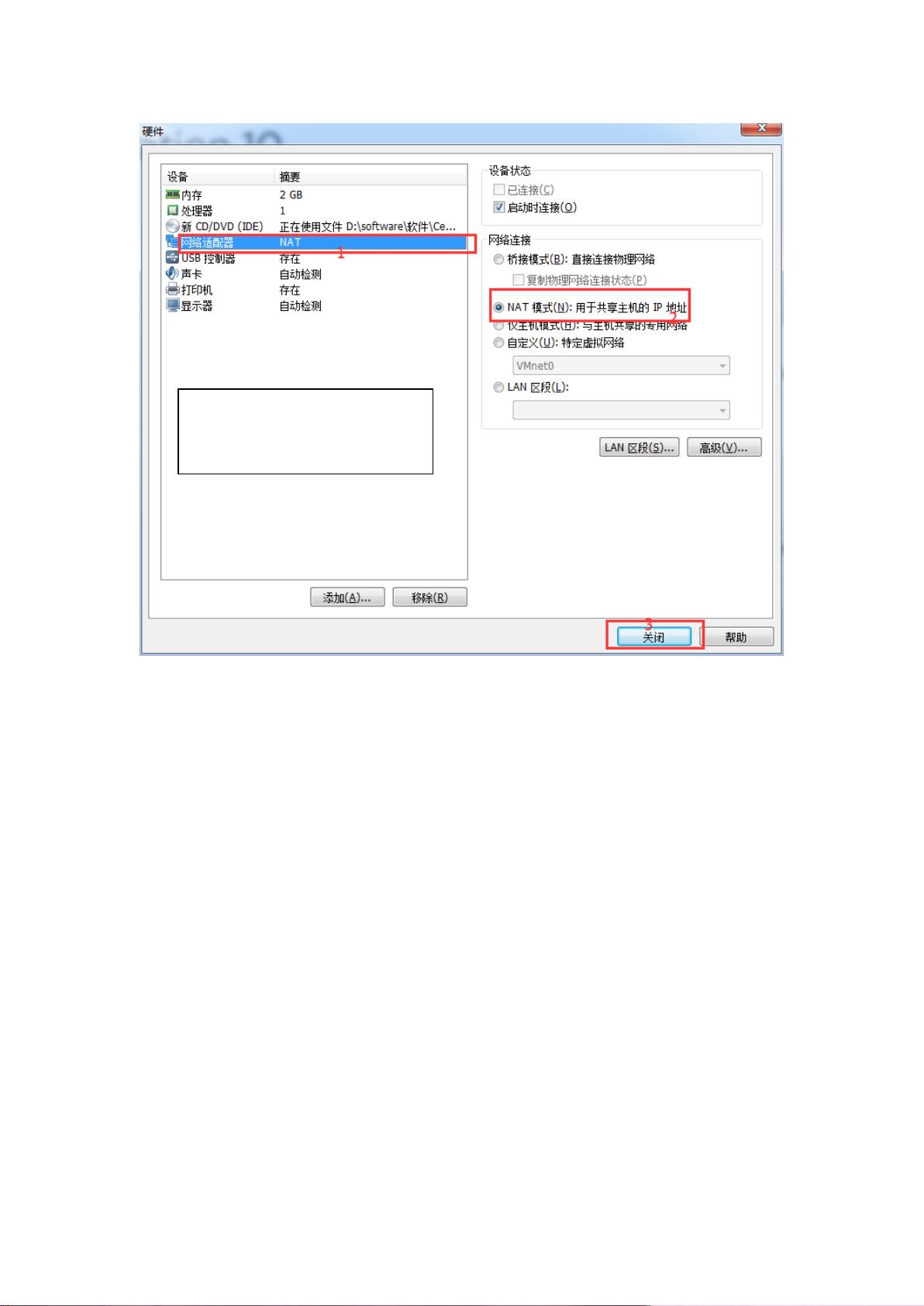
网络配置是安装Hadoop的关键步骤。由于使用固定IP,需要确保所有虚拟机和本地主机的VMnet8在同一网段。在Windows上设置好VMnet8的IP后,虚拟机的IP也需要配置在同一网段。有两种方法进行配置:一是通过虚拟机的网络连接设置,二是直接在Linux终端中进行修改。切换到root用户,编辑网络配置文件,如`/etc/sysconfig/network-scripts/ifcfg-eth0`,设置IP、子网掩码和网关。
完成上述步骤后,Hadoop的安装并未结束。接下来,需要配置Hadoop环境变量,解压并移动Hadoop安装包到适当目录,例如 `/usr/local/hadoop`,然后配置`hadoop-env.sh`,`core-site.xml`,`hdfs-site.xml`,`mapred-site.xml`等配置文件,以设定Hadoop的相关参数,如HDFS的名称节点和数据节点,MapReduce的相关设置等。
最后,启动Hadoop服务,包括DataNode,NameNode,SecondaryNameNode,ResourceManager,NodeManager等。通过运行相应的启动脚本,如`start-dfs.sh`和`start-yarn.sh`,并检查服务是否正常运行,如通过`jps`命令查看进程状态。
Hadoop1的安装涉及虚拟机设置、操作系统安装、网络配置、Hadoop环境变量设定、配置文件修改以及服务启动等多个环节。每个环节都需要细心操作,以确保整个集群的稳定运行。通过这个详细的安装手顺,希望能够帮助学习者顺利地建立起自己的Hadoop1集群,为进一步学习和实践Hadoop提供基础。
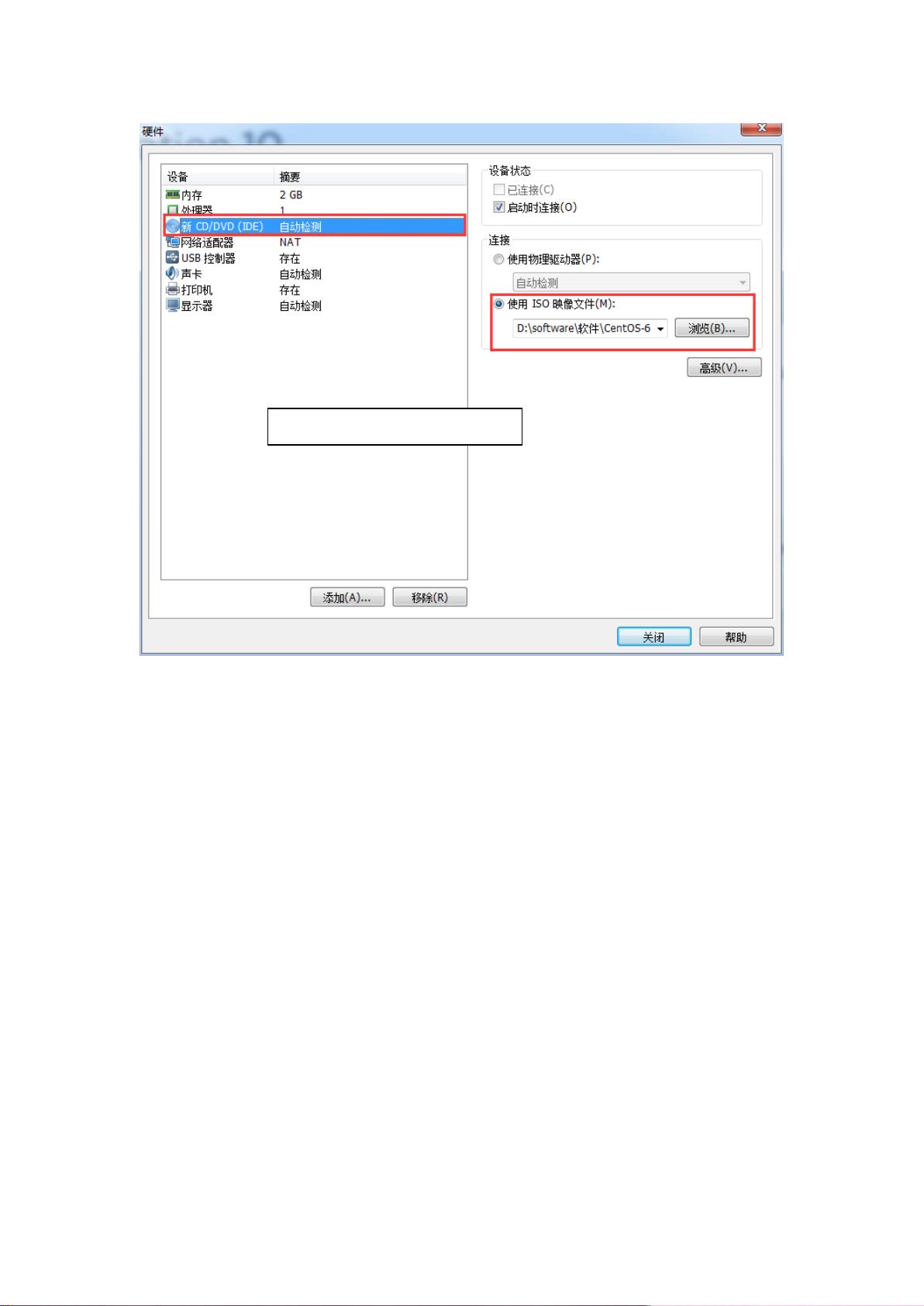
这里选中你下载好的镜像文件
剩余46页未读,继续阅读
196 浏览量
138 浏览量
点击了解资源详情
233 浏览量
270 浏览量
259 浏览量

Nevia
- 粉丝: 1
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- ADA-Framework:ADA框架是第一个旨在简化本机Android应用程序源代码的库。 你准备好了吗?-Android application source code
- 基于matlab的彩色图片去噪
- PHP实例开发源码—PHP飞天下载系统FTDMS.zip
- Creature-Creator:在Unity中按程序生成生物-受孢子启发
- 待办事项
- MATLAB工具箱大全-Matlab数学建模工具箱
- CodeFind:这是一个Android源代码参考应用程序-Android application source code
- leetcode答案-leetcode:学习用基础数据结构与常见算法二刷leetcode相关题目
- 2001年3月主要宏观经济统计指标
- ReactPhotosub:带React的WebSite Photosub
- kaniko-build-private-repo
- leetcode答案-leetcode1701:平均等待时间有一家只有一名厨师的餐厅。给定一个数组customers,其中customers[
- 生成艺术:围棋中的生成艺术
- 2021.1.23
- 金哥哥的秘密小屋.zip
- 金雅拓-Gemalto 智能汽车技术 M2M Automotive-综合文档
