Hadoop入门与学习:分布式存储与计算解析
需积分: 8 19 浏览量
更新于2024-07-16
1
收藏 6.05MB PDF 举报
"这是一份关于Hadoop学习的笔记,涵盖了Hadoop的基本概念、安装、使用以及分布式计算和存储的相关知识,适合Hadoop初学者。笔记中提到了如何处理大规模数据的重复行查找问题,并介绍了Hadoop的三大核心模块:HDFS、MapReduce和YARN,以及Hadoop生态系统中的其他技术如Hive、Hbase和Spark。"
在Hadoop学习笔记中,首先提出了一个实际问题:如何在一台普通计算机上查找1TB大文件中的重复行。笔记提出了两种思路。思路一是基于冒泡排序思想,逐行比较并清除内存中的旧数据,但这种方法效率低下。思路二是通过计算哈希值将大文件拆分成小文件,按哈希值对文件进行分组,这样能有效减少比较次数。
接着,笔记详细介绍了Hadoop的三大核心模块:
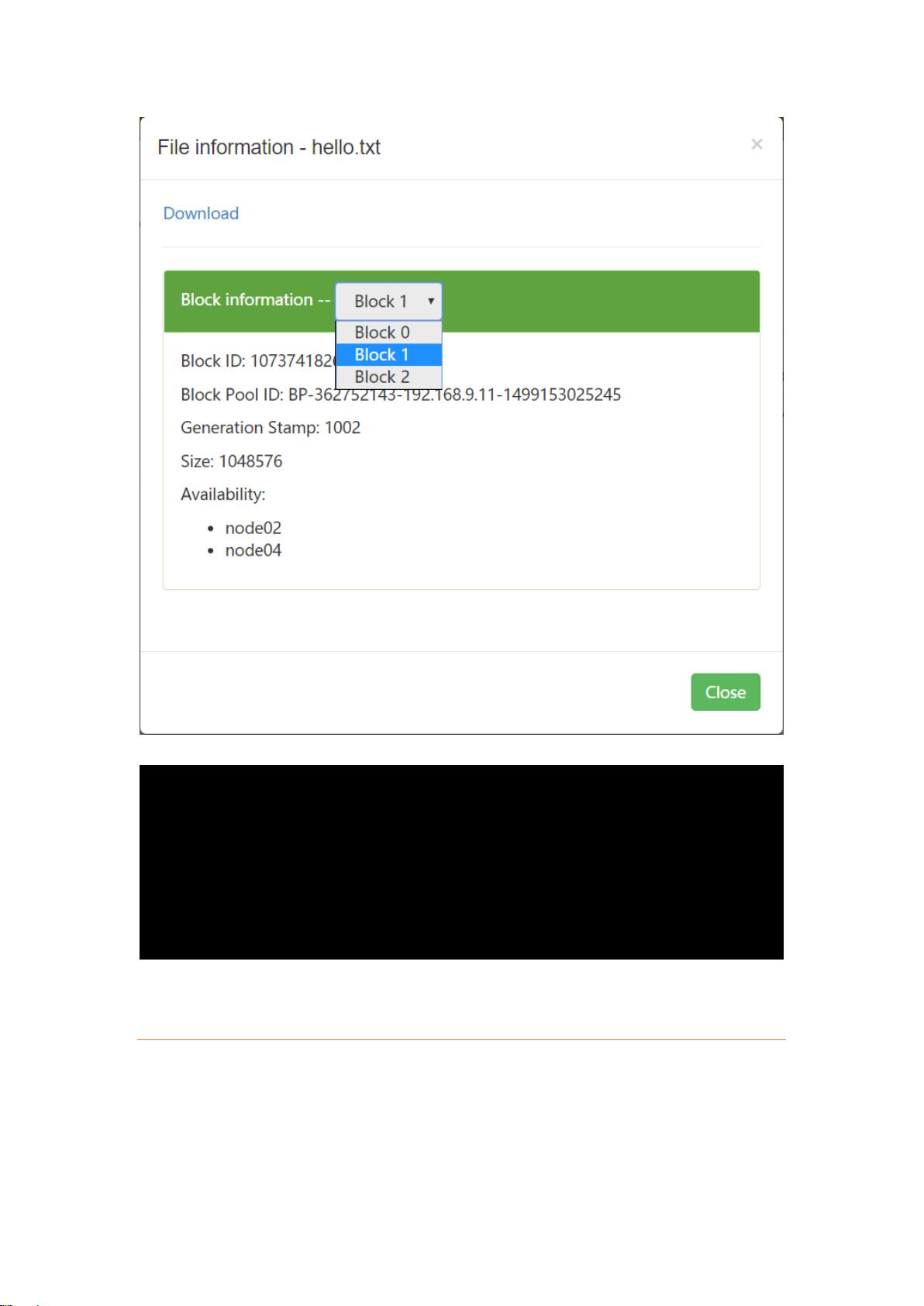
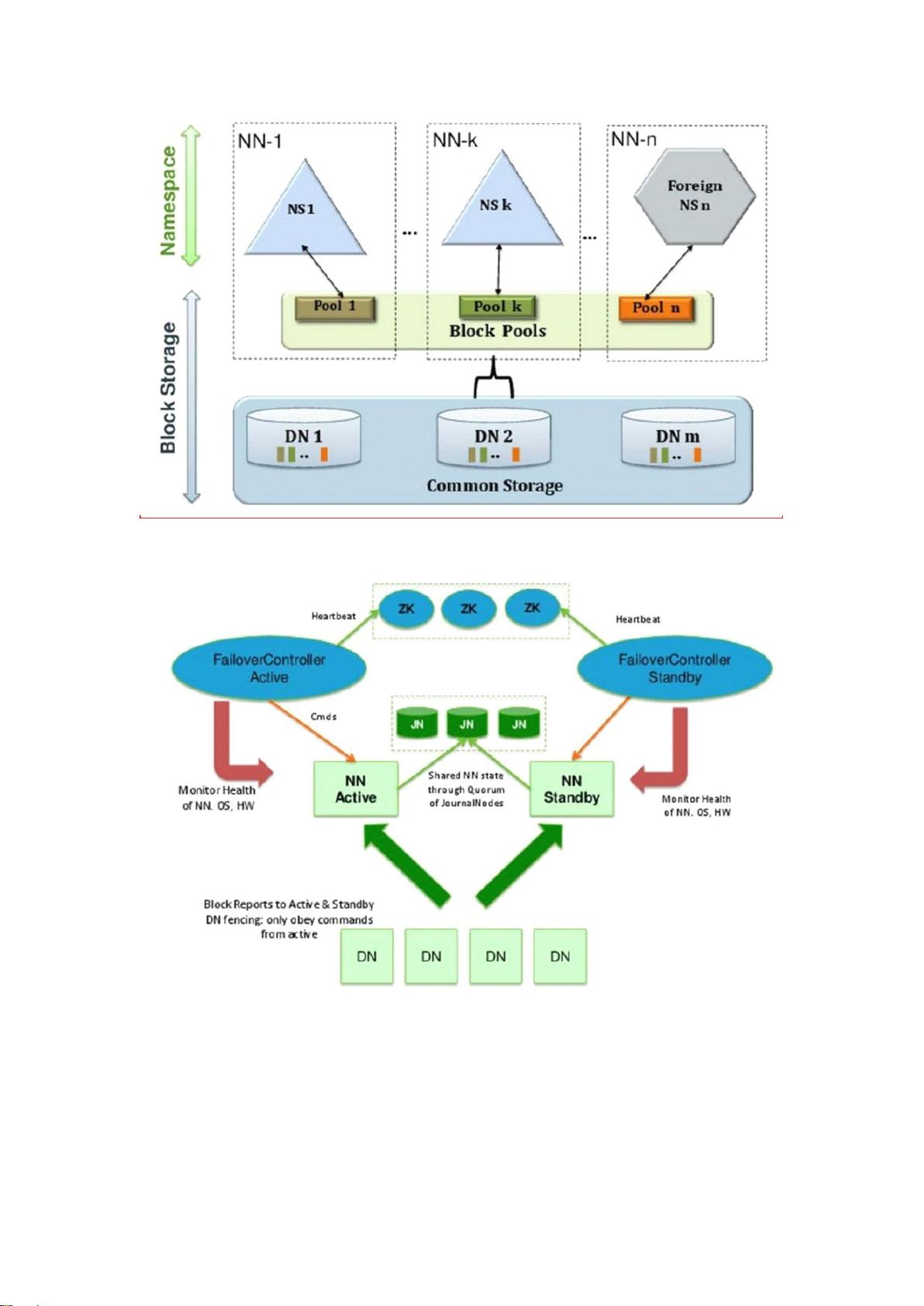
1. **分布式存储系统HDFS (Hadoop Distributed File System)**:HDFS设计用于可靠、可扩展且高吞吐量的数据存储。它将大文件分割成块(Block),每个块有固定的大小,通常为128MB或256MB,且可以设置副本数以提高容错性。HDFS遵循一次写入、多次读取的原则,不支持块内的修改,但允许追加数据。NameNode作为主节点负责存储文件元数据,而DataNode作为从节点保存实际的Block数据,两者通过心跳机制保持通信。
2. **分布式计算框架MapReduce**:MapReduce简化了大规模数据处理的编程模型,具有易编程、高容错和高扩展性的特点。它将任务分解为Map阶段和Reduce阶段,Map阶段处理数据并将结果暂存,Reduce阶段聚合这些结果以生成最终输出。
3. **分布式资源管理框架YARN**:YARN负责集群资源的管理和调度,为Hadoop提供了一个通用的资源管理层,使得除了MapReduce之外的其他计算框架也能在Hadoop集群上运行。
Hadoop的生态系统还包括了其他组件,例如:
- **Hive**:一个基于Hadoop的数据仓库工具,用于数据查询和分析,支持SQL-like语言(HQL)。
- **HBase**:一个分布式的、面向列的NoSQL数据库,运行在HDFS之上,提供实时读写操作。
- **Spark**:快速、通用且可扩展的大数据处理框架,支持批处理、交互式查询和实时流处理,与Hadoop兼容。
这些组件共同构建了强大的大数据处理平台,使得开发者能够高效地处理PB级别的数据。通过学习这份笔记,读者将对Hadoop有深入的理解,并具备处理大数据问题的基础能力。

</property>
</configuration>
[root@node01 hadoop]# vi slaves
node02
node03
node04
4. 将 node01 的 hadoop 安装目录分发给其他节点
[root@node01 sxt]# scp -r hadoop-2.6.5 node02:`pwd`
[root@node01 sxt]# scp -r hadoop-2.6.5 node03:`pwd`
[root@node01 sxt]# scp -r hadoop-2.6.5 node04:`pwd`
5. 格式化文件系统(只在第一次启动时格式化)
[root@node01 sxt]# hdfs namenode -format
6. 启动服务
[root@node01 sxt]# start-dfs.sh
Starting namenodes on [node01]
node01: starting namenode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-namenode-
node01.out
node04: starting datanode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-datanode-
node04.out
node02: starting datanode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-datanode-
node02.out
node03: starting datanode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-datanode-
node03.out
Starting secondary namenodes [node02]
node02: starting secondarynamenode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-
secondarynamenode-node02.out
7. 进行一些操作
[root@node01 ~]# for i in `seq 100000`;do echo "$i Hello sxt You Are Good" >>
/tmp/hello.txt;done
[root@node01 ~]# hdfs dfs -D dfs.blocksize=1048576 -put /tmp/hello.txt
#hdfs 切割文件时,按照字节来切分,思考,如果是中文,怎么切割?


剩余114页未读,继续阅读
2018-08-25 上传
Exception in thread "main" org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.fs.FileAlreadyExi
2023-04-03 上传
2023-05-27 上传
2023-05-25 上传
2023-06-13 上传
2023-06-10 上传

则不达
- 粉丝: 10
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- JDK 17 Linux版本压缩包解压与安装指南
- C++/Qt飞行模拟器教员控制台系统源码发布
- TensorFlow深度学习实践:CNN在MNIST数据集上的应用
- 鸿蒙驱动HCIA资料整理-培训教材与开发者指南
- 凯撒Java版SaaS OA协同办公软件v2.0特性解析
- AutoCAD二次开发中文指南下载 - C#编程深入解析
- C语言冒泡排序算法实现详解
- Pointofix截屏:轻松实现高效截图体验
- Matlab实现SVM数据分类与预测教程
- 基于JSP+SQL的网站流量统计管理系统设计与实现
- C语言实现删除字符中重复项的方法与技巧
- e-sqlcipher.dll动态链接库的作用与应用
- 浙江工业大学自考网站开发与继续教育官网模板设计
- STM32 103C8T6 OLED 显示程序实现指南
- 高效压缩技术:删除重复字符压缩包
- JSP+SQL智能交通管理系统:违章处理与交通效率提升
