机器学习必备:回归损失函数详解
版权申诉
68 浏览量
更新于2024-07-07
收藏 673KB DOCX 举报
"本文介绍了机器学习中常用的5个回归损失函数,包括L1、L2、Huber、Log-Cosh和分位数损失函数,强调了选择合适的损失函数对模型性能的重要性。"
回归损失函数是机器学习中评估模型预测效果的关键工具,不同的损失函数适用于不同的数据特性和应用场景。下面我们将逐一探讨这五个回归损失函数:
1. **均方误差 (Mean Squared Error, MSE)**:MSE是最常见的回归损失函数,它通过计算预测值与真实值之间的差值平方的平均值来评估误差。MSE对异常值敏感,因为一个大误差会被平方放大,可能导致训练过程中权重更新过于剧烈。其图形是一个关于真实值的对称抛物线,最小值出现在预测值等于真实值时。
2. **平均绝对误差 (Mean Absolute Error, MAE)**:与MSE不同,MAE计算的是预测值与真实值之差的绝对值的平均值,对异常值的敏感性较低。由于不进行平方操作,MAE通常对离群值的处理更为稳健,但其梯度不如MSE平滑,可能使得梯度下降过程较慢。
3. **Huber损失**:Huber损失结合了MSE和MAE的优点,对于小误差,它接近于MSE,而对于大误差,它接近于MAE,这样可以同时减少对离群值的敏感性和保持良好的梯度特性。Huber损失通过一个阈值δ来划分小误差和大误差,低于阈值的部分采用平方误差,超过部分采用绝对误差。
4. **Log-Cosh损失**:Log-Cosh损失函数是基于双曲余弦函数的,它在小误差时接近于MSE,但在大误差时更平滑,不会像MSE那样急剧增加。这种损失函数对异常值有较好的鲁棒性,并且其导数在所有地方都存在,避免了梯度消失的问题。
5. **分位数损失 (Quantile Loss)**:分位数损失常用于计算预测区间,特别是在金融领域预测未来趋势时,需要估计预测值的分布。它可以根据用户对风险的容忍度选择不同的分位数,如0.5对应的中位数损失,可以得到无偏预测。分位数损失函数不是对称的,对于低于或高于真实值的预测,损失函数的形状不同。
选择合适的损失函数取决于具体任务的需求,例如,如果数据中存在大量异常值,Huber或Log-Cosh损失可能是更好的选择;如果需要对预测的不确定性建模,分位数损失则更有用。理解并正确应用这些损失函数,能够帮助我们构建更精确、更鲁棒的机器学习模型。在实际应用中,通常需要通过实验比较不同损失函数的效果,以找到最适合特定数据集的那一个。
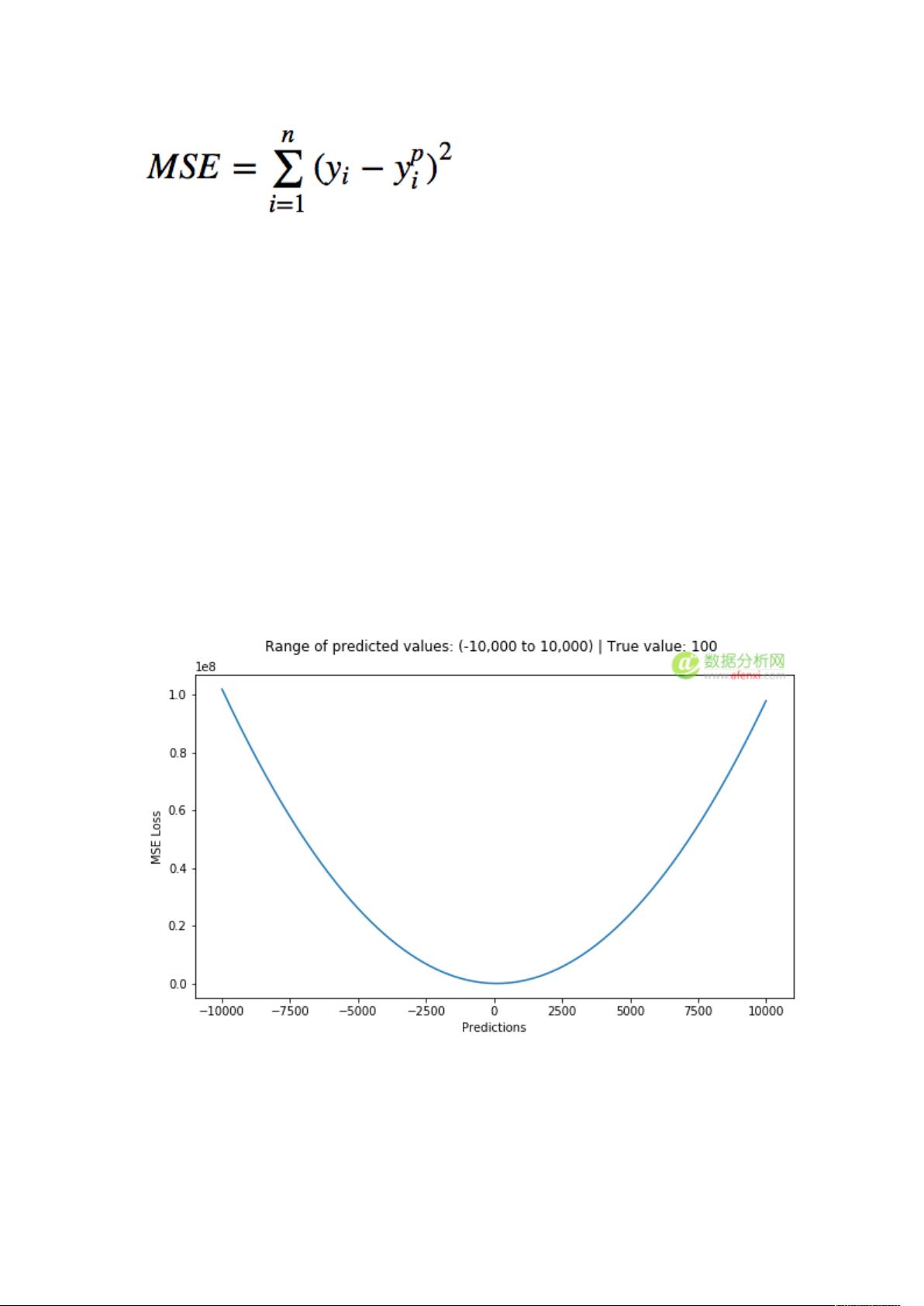
均方误差(MSE)是最常用的回归损失函数,计算方法是求预测
值与真实值之间距离的平方和,公式如图。
下图是 MSE 函数的图像,其中目标值是 100,预测值的范围
从-10000 到 10000,Y 轴代表的 MSE 取值范围是从 0 到正无
穷,并且在预测值为 100 处达到最小。
MSE 损失(Y 轴)-预测值(X 轴)
平均绝对值误差(也称 L1 损失)
剩余23页未读,继续阅读
2022-08-03 上传
2022-06-11 上传

weixin_41031635
- 粉丝: 0
- 资源: 5万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- IEEE 14总线系统Simulink模型开发指南与案例研究
- STLinkV2.J16.S4固件更新与应用指南
- Java并发处理的实用示例分析
- Linux下简化部署与日志查看的Shell脚本工具
- Maven增量编译技术详解及应用示例
- MyEclipse 2021.5.24a最新版本发布
- Indore探索前端代码库使用指南与开发环境搭建
- 电子技术基础数字部分PPT课件第六版康华光
- MySQL 8.0.25版本可视化安装包详细介绍
- 易语言实现主流搜索引擎快速集成
- 使用asyncio-sse包装器实现服务器事件推送简易指南
- Java高级开发工程师面试要点总结
- R语言项目ClearningData-Proj1的数据处理
- VFP成本费用计算系统源码及论文全面解析
- Qt5与C++打造书籍管理系统教程
- React 应用入门:开发、测试及生产部署教程
