Python后端爬虫开发深度解析:从基础到实战
需积分: 3 13 浏览量
更新于2024-06-14
收藏 48.87MB PDF 举报
"本课程详细介绍了Python后端开发中的Spider框架,涵盖了爬虫的基本原理、数据抓取技术、网络请求库、数据解析方法以及数据库存储和并发控制等内容,旨在提升开发者在Python爬虫领域的进阶技能。"
在Python后端开发中,Spider框架通常用于自动化地抓取和处理互联网上的数据。以下是关于这一主题的详细知识点:
1. 爬虫原理与数据抓取:
- 通用爬虫和聚焦爬虫:通用爬虫遍历整个互联网,而聚焦爬虫则根据特定目标有选择地抓取网页。
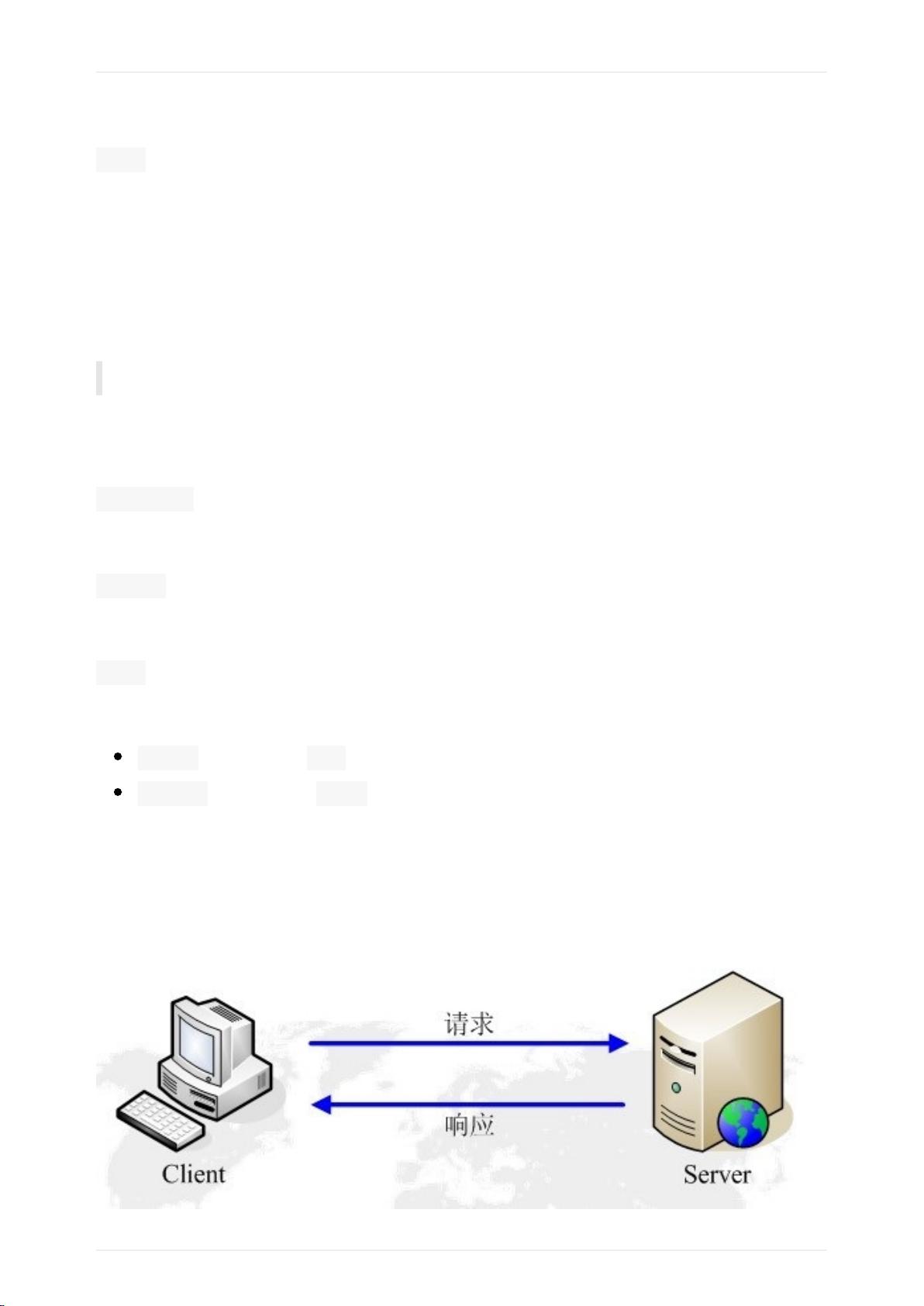
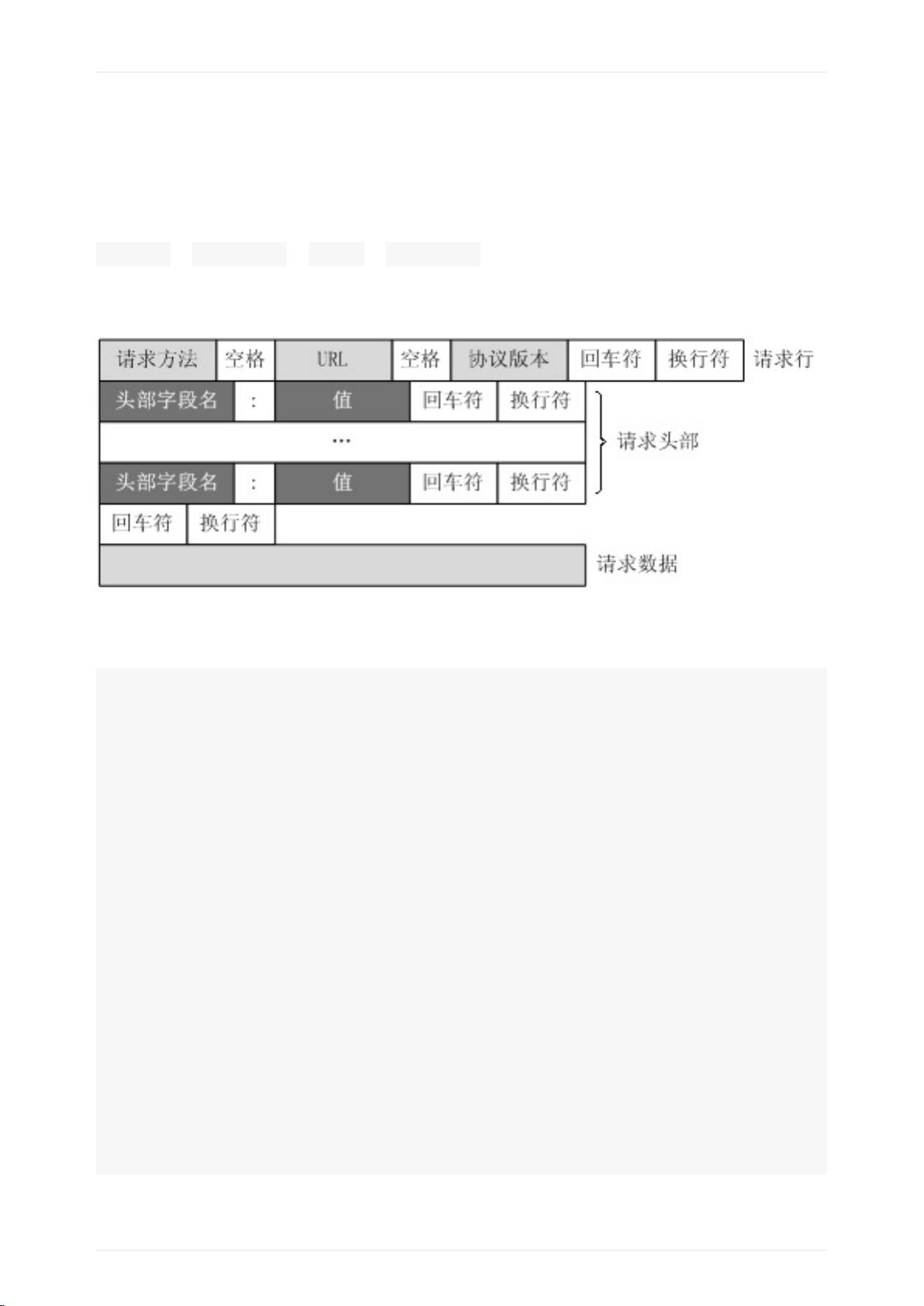
- HTTP/HTTPS请求与响应:理解HTTP协议的基本概念,包括GET和POST请求,以及服务器的响应状态码和头信息。
- Fiddler:学习使用HTTP抓包工具,如Fiddler,来监控和调试网络请求。
2. Python网络请求库:
- urllib2模块:学习如何使用urllib2进行GET和POST请求,处理异常如URLError和HTTPError,以及自定义Handler和Opener以扩展功能。
- Requests模块:更高级且易于使用的库,支持GET和POST请求,同时提供了丰富的功能,如自动处理cookies、会话管理等。
3. 数据提取:
- 非结构化数据与结构化数据:区分两者,学习如何从非结构化的HTML或XML文档中提取结构化数据。
- 正则表达式re模块:使用正则表达式进行文本匹配和数据提取,编写简单的爬虫案例。
- XPath与lxml库:学习XPath语法,使用lxml库解析HTML和XML文档,提取所需数据。
- BeautifulSoup4:理解其解析机制,通过它进行HTML解析和数据提取。
- JSON模块与JsonPath:处理JSON格式数据,使用JsonPath进行JSON对象的数据提取。
4. 并发控制:
- 多线程和协程:了解如何利用Python的threading模块进行多线程爬虫,以及使用gevent等库实现协程,提高爬虫效率。
- 猿事百科多线程爬虫案例:实际操作案例,演示如何用多线程爬取网站数据。
5. 数据存储:
- MongoDB数据库:介绍NoSQL数据库MongoDB,包括安装、基本操作(增删改查)和索引创建。
- 数据库操作:掌握数据库的集合操作,如数据类型、查询、更新、删除,以及聚合操作。
6. 动态HTML处理:
- 动态HTML介绍:了解现代网站中JavaScript生成内容的现象,以及对静态爬虫的挑战。
- Selenium与PhantomJS:学习使用Selenium自动化测试工具,配合PhantomJS无头浏览器处理动态加载的内容。
7. 图像识别:
- 机器图像识别:在爬虫场景下,可能会遇到验证码识别,这里涉及图像处理和机器学习技术,如OCR(光学字符识别)。
本课程涵盖了Python后端开发中构建高效爬虫所需的基础知识和技术,从网络请求、数据解析到数据存储和处理动态HTML,为开发者提供了全面的学习路径。通过这些内容的学习,开发者可以掌握构建复杂网络爬虫的能力。
名词注解:
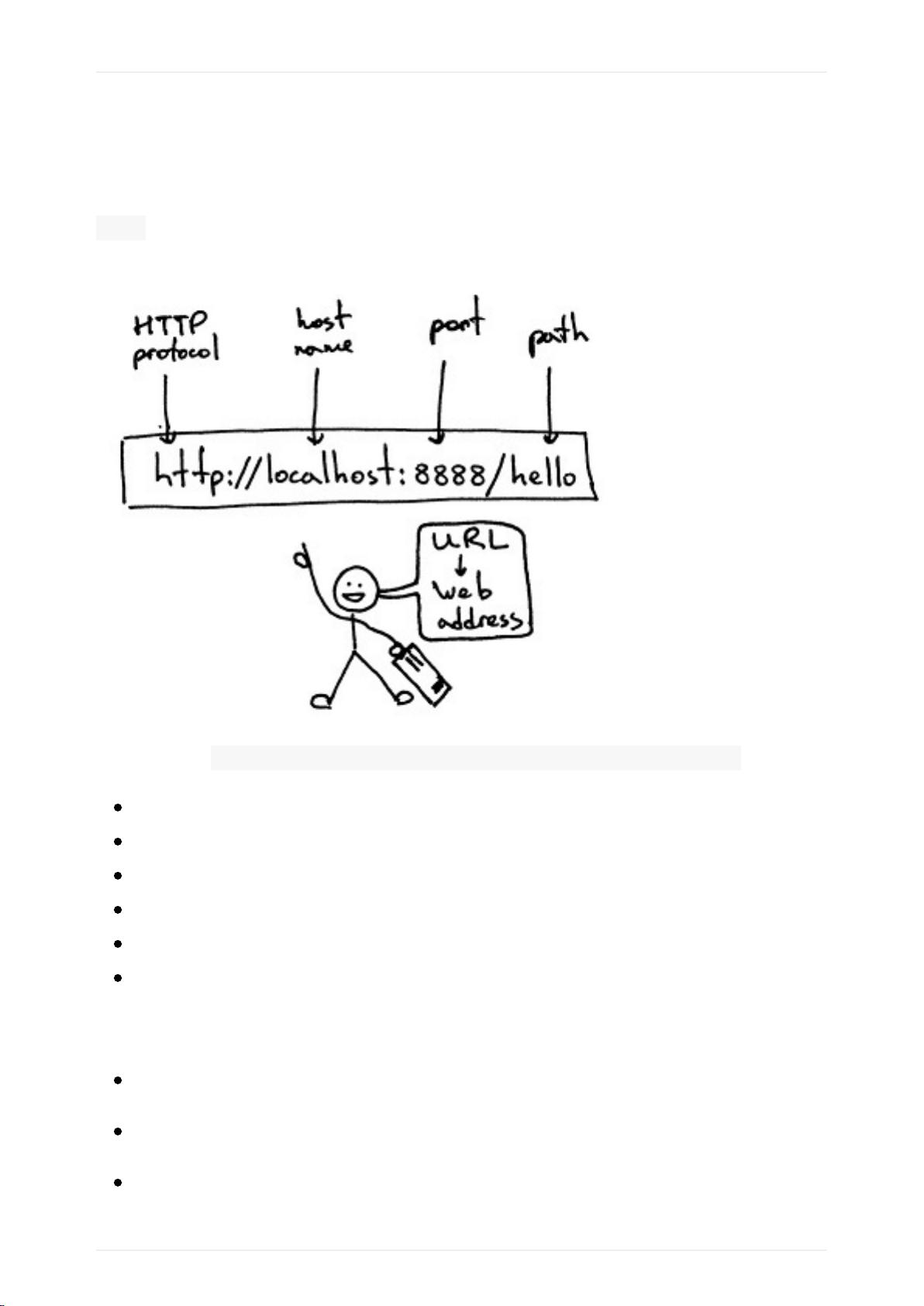
1.URL
URL(Uniform/UniversalResourceLocator的缩写):统⼀资源定位符,
是⽤于完整地描述Internet上⽹⻚和其他资源的地址的⼀种标识⽅法。
基本格式: scheme://host[:port]/path/[?query-string][#anchor]
scheme:协议(例如:http,https,ftp等)
host:服务器的域名或IP地址
port:服务器的端⼝(如果是⾛协议默认端⼝,HTTP缺省端⼝80)
path:访问资源的路径
query-string:查询字符串参数,发送给http服务器的数据
anchor:锚点(跳转到⽹⻚的指定锚点位置)
例如:
ftp://192.168.0.123:8080/index
http://www.baidu.com
http://item.jd.com/11936238.html#product-detail
(复习)HTTP/HTTPS的请求与响应
16


剩余604页未读,继续阅读
2019-10-21 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

handlrer
- 粉丝: 1
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- model_MEPERS
- Contacts_App
- java版商城源码-learnUrl:学习网址
- paizhao.zip
- 新星
- ACs---Engenharia:为需求工程主题的AC1创建的存储库
- tmux-power:mu Tmux电力线主题
- Flutter_frist_demo:颤振学习演示
- java版商城源码-mall:购物中心
- u5_final
- 华为模拟器企业网设计.zip
- python-random-integer-project
- aqi-tool:空气质量指数(AQI)计算器
- java版商城源码-MachiKoroDigitization:MachiKoro游戏由3人组成
- c04-ch5-exercices-leandregrimmel:c04-ch5-exercices-leandregrimmel由GitHub Classroom创建
- Monique-Nilles
