"深度解析尚硅谷大数据技术之Spark内核V3.0:核心组件与任务调度机制"
需积分: 0 22 浏览量
更新于2024-03-22
收藏 1.12MB DOCX 举报
本文介绍了尚硅谷大数据技术之Spark内核版本V3.0的内容,主要包括了Spark内核的概述,其中涉及了Spark的核心运行机制,包括核心组件的运行机制、任务调度机制、内存管理机制以及核心功能的运行原理等内容。熟练掌握Spark内核原理可以帮助我们更好地设计Spark代码,并能够准确地解决项目运行过程中出现的问题。
在Spark内核概述中,我们首先回顾了Spark的核心组件,其中包括了Driver和Executor。Driver节点是执行Spark任务中的main方法的节点,负责实际的代码执行工作。在Spark作业执行过程中,Driver主要负责将用户程序转换为作业执行图,并且负责维护整个作业的执行状态。另一方面,Executor节点是在Worker节点上执行任务的容器,负责执行具体的任务并向Driver报告任务执行的状态。Executor节点的数量可以根据集群的资源情况进行动态调整,以实现更好的性能。
另外,本文还介绍了Spark的任务调度机制。Spark的任务调度是基于DAG调度模型的,在调度过程中会将用户程序转换为有向无环图(DAG),并根据依赖关系来执行任务。这种调度模型可以有效减少任务之间的依赖关系,提高作业的并行度,从而提高作业的执行效率。
此外,本文还介绍了Spark的内存管理机制。Spark内存管理主要是指Spark如何管理内存资源,包括内存的分配、释放、回收等操作。Spark的内存管理采用了堆内存和堆外内存相结合的方式,通过使用内存管理器来管理内存资源,以提高作业的执行效率。
最后,本文还介绍了Spark核心功能的运行原理。Spark提供了丰富的API和功能,例如RDD、DataFrame、DataSet等,这些功能都是基于Spark内核的运行机制实现的。了解这些核心功能的运行原理可以帮助我们更好地使用Spark进行数据处理和分析,提高代码的效率和性能。
综上所述,熟练掌握Spark内核的原理和运行机制可以帮助我们更好地设计和优化Spark代码,提高作业的执行效率和性能,从而更好地应用Spark进行大数据处理和分析。感谢尚硅谷大数据研发部为我们提供如此精彩的Spark内核学习内容。
尚硅谷大数据技术之 Spark 内核
—————————————————————————————
更多 Java –大数据 –前端 –python 人工智能资料下载,可百度访问:尚硅谷官网
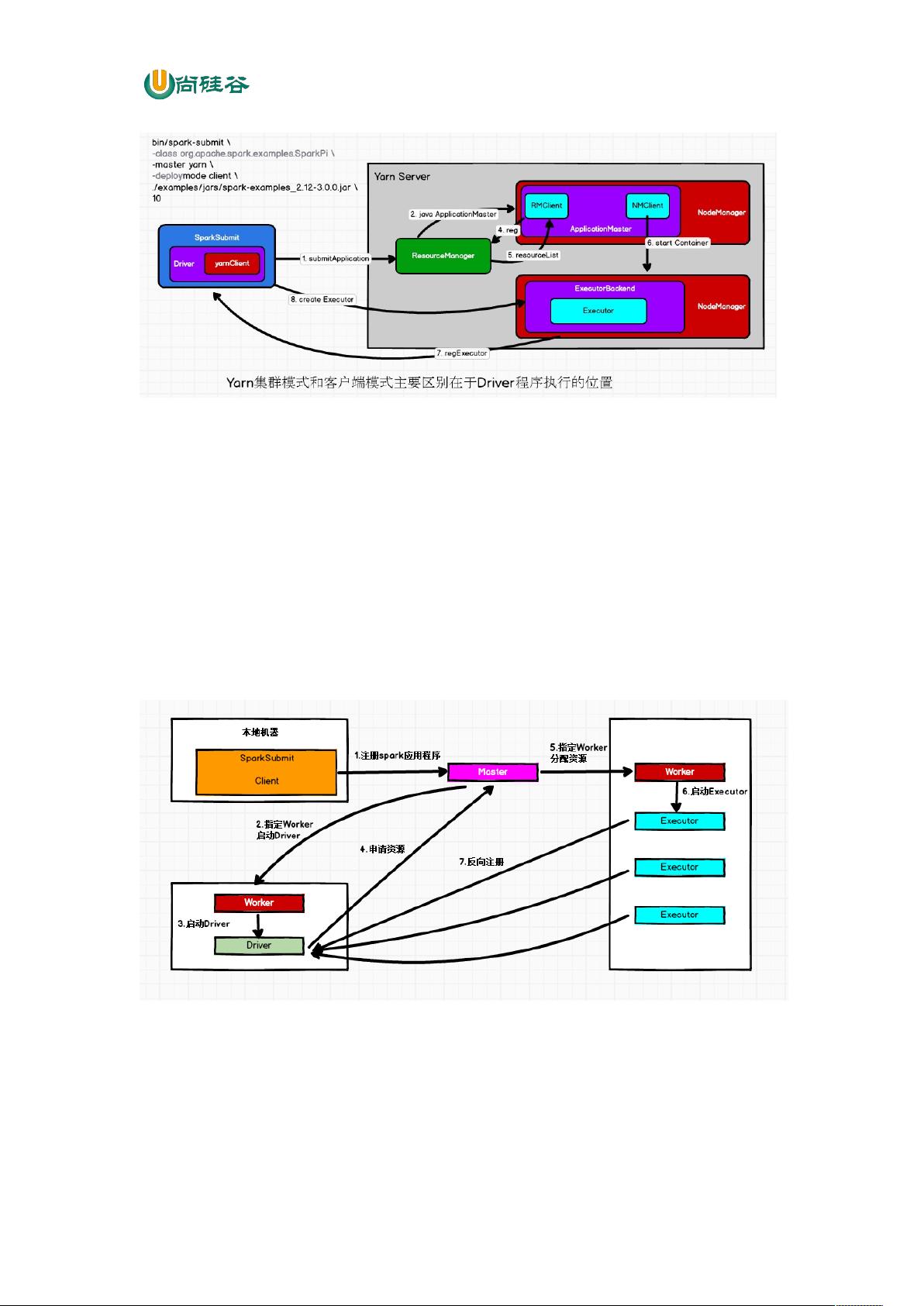
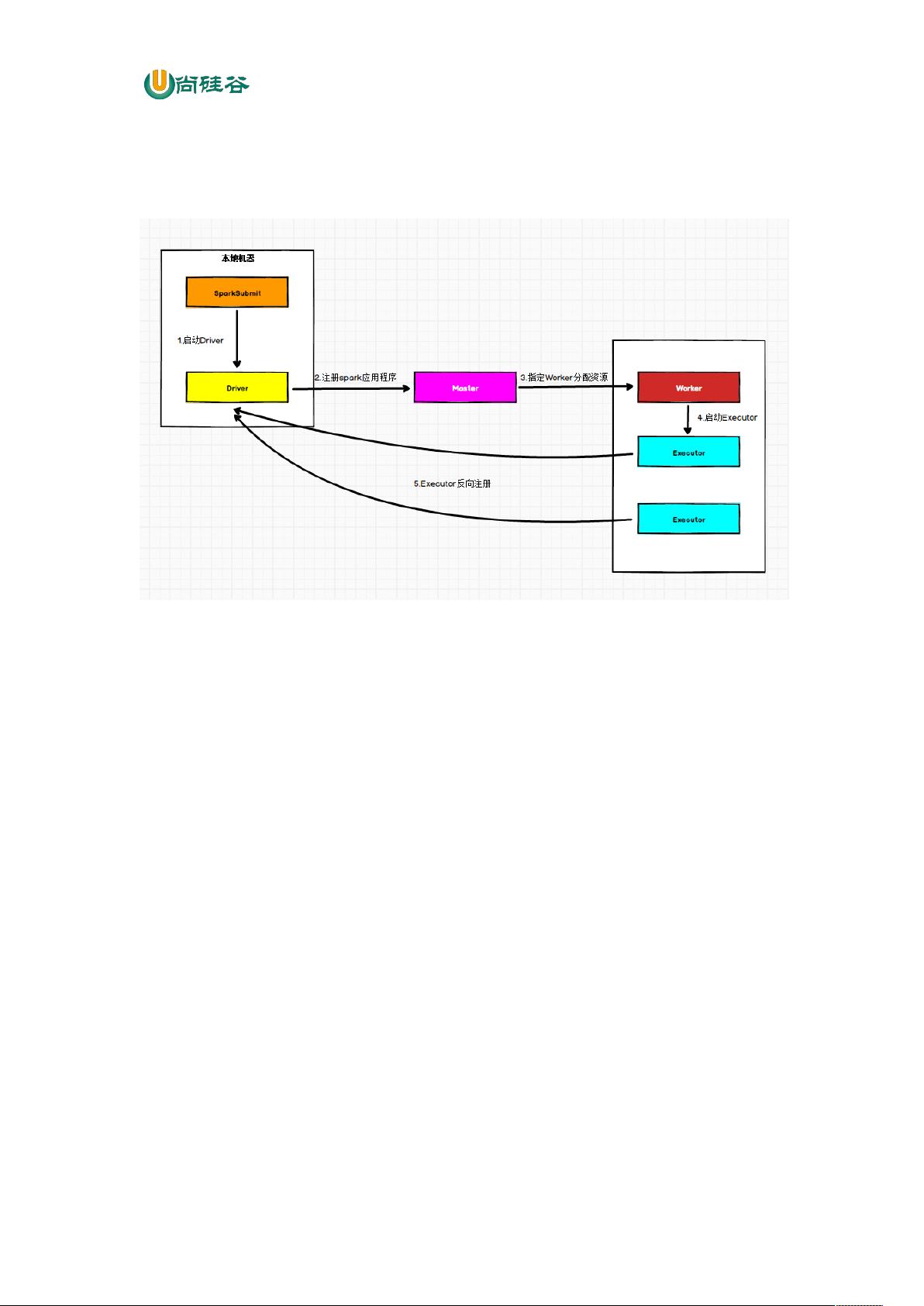
2.2 Standalone 模式运行机制
Standalone 集群有 2 个重要组成部分,分别是:
1) Master(RM):是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责;
2) Worker(NM):是一个进程,一个 Worker 运行在集群中的一台服务器上,主要负责两个
职责,一个是用自己的内存存储 RDD 的某个或某些 partition;另一个是启动其他进程
和线程(Executor),对 RDD 上的 partition 进行并行的处理和计算。
2.2.1 Standalone Cluster 模式
在 Standalone Cluster 模式下,任务提交后,Master 会找到一个 Worker 启动 Driver。
Driver 启动后向 Master 注册应用程序,Master 根据 submit 脚本的资源需求找到内部资源至
少可以启动一个Executor 的所有 Worker,然后在这些 Worker 之间分配 Executor,Worker 上
的 Executor 启动后会向Driver 反向注册,所有的 Executor 注册完成后,Driver 开始执行 main
函数,之后执行到Action 算子时,开始划分Stage,每个 Stage 生成对应的 taskSet,之后将
剩余30页未读,继续阅读
2022-08-03 上传
2022-08-08 上传
2023-03-15 上传
2018-04-10 上传
2018-10-12 上传
点击了解资源详情
2019-05-28 上传
2020-06-30 上传
点击了解资源详情

顾露
- 粉丝: 19
- 资源: 313
 我的内容管理
展开
我的内容管理
展开







