Hadoop电商商城:基于用户收藏的推荐系统实现与优化
104 浏览量
更新于2024-08-28
1
收藏 429KB PDF 举报
在本文档中,我们探讨了如何利用Hadoop构建一个购物商城推荐系统,主要针对单商家、多买家的场景,数据库采用MySQL,编程语言为Java。推荐系统的核心技术包括数据迁移工具Sqoop1.9.33用于在MySQL和Hadoop之间传输数据,以及Hadoop2.2.0的伪分布模式进行练习。
1. **数据迁移与准备**:
- Sqoop1.9.33在这里扮演了关键角色,它被用来从MySQL数据库中提取"用户收藏商品"的信息,这是推荐系统的基础数据。由于推荐依据相对简单,这里假设用户收藏商品的行为可以作为相似度计算的基础。
- 数据迁移涉及到编写Sqoop命令行脚本或在Eclipse中配置Job,以将这些数据导入到Hadoop分布式文件系统(HDFS)中。
2. **推荐算法实现**:
- 推荐算法使用MapReduce框架来处理大规模数据。第一步是对用户行为(如收藏)进行分组,将用户对商品的喜好映射到不同的键值对中,其中键代表用户,值是其收藏的商品列表。
- 第二步是计算商品之间的相似性,通过构建商品共现矩阵,矩阵中的每个元素表示两个商品同时被多少用户收藏。可以使用诸如余弦相似度或Jaccard相似度等算法来量化商品间的相似度。
3. **结果处理与反馈**:
- 推荐结果会通过Sqoop再次写回到MySQL数据库,以便于Java商城应用程序读取并展示给用户,比如显示"喜欢该商品的人还喜欢,相同购物喜好的好友推荐"这样的个性化建议。
4. **代码结构**:
- 提供了部分代码片段,如`Util`类中的`Pattern`定义用于分割数据,以及`ShopxxProductRecommend`类可能用于MapReduce的Mapper和Reducer方法实现。这些代码展示了如何处理输入数据,分组和相似度计算。
5. **注意事项**:
- 开发过程中可能会遇到Sqoop1.9.33版本的兼容性和文档不足问题,遇到这类问题可以通过发送邮件至指定邮箱(keepmovingzx@163.com)寻求帮助。
这个项目展示了如何将用户行为数据从关系型数据库迁移到Hadoop,利用MapReduce计算商品之间的关联,并将结果返回给前端应用以提供个性化推荐。这是一个典型的大数据推荐系统设计与实现案例。
hadoop实现购物商城推荐系统实现购物商城推荐系统
1,商城:是单商家,多买家的商城系统。数据库是mysql,语言java。
2,sqoop1.9.33:在mysql和hadoop中交换数据。
3,hadoop2.2.0:这里用于练习的是伪分布模式。
4,完成内容:喜欢该商品的人还喜欢,相同购物喜好的好友推荐。
步骤:
1,通过sqoop从mysql中将 “用户收藏商品” (这里用的是用户收藏商品信息表作为推荐系统业务上的依据,业务依据可以很
复杂。这里主要介绍推荐系统的基本原理,所以推荐依据很简单)的表数据导入到hdfs中。
2,用MapReduce实现推荐算法。
3,通过sqoop将推荐系统的结果写回mysql。
4,java商城通过推荐系统的数据实现<喜欢该商品的人还喜欢,相同购物喜好的好友推荐。>两个功能。
实现:
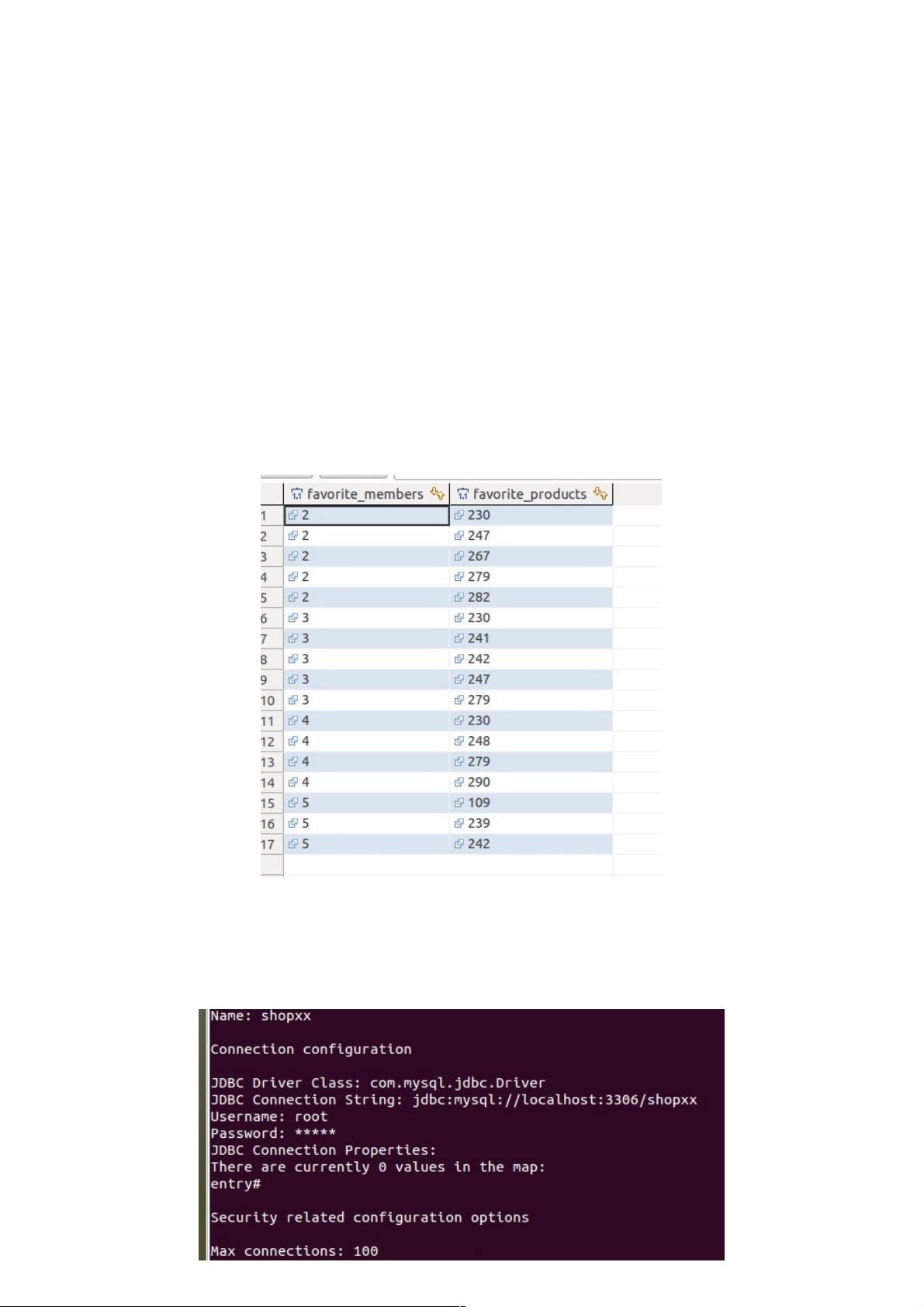
1,推荐系统的数据来源:
左边是用户,右边是商品。用户每收藏一个商品都会生成一条这样的信息,<喜欢该商品的人还喜欢,相同购物喜好的好友推
荐。>的数据来源都是这张表。
sqoop导入数据,这里用的sqoop1.9.33。sqoop1.9.33的资料很少,会出现一些错误,搜索不到的可以发到我的邮箱
keepmovingzx@163.com。
创建链接信息
下载后可阅读完整内容,剩余9页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-06-09 上传
2024-03-13 上传
2011-03-08 上传
2024-11-06 上传
2021-07-20 上传
2019-05-24 上传

weixin_38516380
- 粉丝: 3
- 资源: 942
 我的内容管理
展开
我的内容管理
展开







最新资源
- Mathematics for Computer Graphics
- Tomcat 安装配置手册
- web课件第九章 ASP.NET的XML编程
- Java Struts教程
- 基于PLC的步进电机控制系统及其在火车轴温检测系统中的应用.pdf
- Eclipse中文教程
- 基于TCPIP的局域网多用户通信
- oracle动态过程执行
- WEB SERVICE
- 嵌入式Linux驱动开发实例分析
- linux c 编程.pdf
- 1_必读_高质量C++编程指南(林锐博士).pdf
- c语言指针经验总结.pdf
- kr.ac.jbnu.ssel.misrac:OpenMRC
- ogov-importer:阿根廷国会法案进口商
- 大数据导论PPT和期末复习笔记
