Spark大数据处理技术详解
需积分: 9 124 浏览量
更新于2024-07-15
收藏 1.19MB PDF 举报
"《大数据处理技术》教材中关于Spark的内容,由昆明理工大学计算机科学与技术系的周海河编写。本章主要介绍了Spark的基本概念、生态系统、运行架构、SparkSQL、部署与应用方式以及编程实践。书中强调了Spark作为内存计算的并行计算框架,相比Hadoop具有更快的运行速度和更高的效率。Spark支持多种编程语言,提供丰富的功能模块,如SQL查询、流处理、机器学习和图算法,并能在多种环境下运行。"
在大数据领域,Spark是一个至关重要的工具,它源于美国加州伯克利大学AMP实验室的研究,后来成为Apache软件基金会的重要项目。Spark的主要优势在于其运行速度快,这得益于其DAG(有向无环图)执行引擎和对内存计算的支持,使得循环数据流处理变得更加高效。相比于Hadoop,Spark在处理大规模数据时能够显著减少计算资源的需求,同时提高处理速度。
Spark的设计目标是易用性,它支持使用Scala、Java、Python和R语言进行编程,对于数据分析人员来说,这是一个非常友好的特性。此外,通过SparkShell,用户可以进行交互式的编程体验,增强了开发的灵活性和便捷性。
Spark的通用性体现在它的多功能性上。SparkSQL提供了SQL接口,使得传统数据库用户可以方便地进行大数据查询。Spark还包含了流处理功能,适应实时数据处理需求,以及MLlib机器学习库和GraphX图计算框架,满足了多样化的数据处理场景。
Spark可以在不同的运行模式下工作,无论是独立集群,还是在Hadoop之上,甚至是云端环境如Amazon EC2,都能够灵活部署。此外,Spark能接入多种数据存储系统,如HDFS、Cassandra、HBase和Hive,这大大增强了其数据处理的兼容性和灵活性。
Spark是大数据处理领域的一个强大工具,它以其高性能、易用性和广泛的适用性,成为了现代大数据解决方案的关键组成部分。了解和掌握Spark的相关知识,对于从事大数据分析和处理的从业者至关重要。
《大数据处理技术》 昆明理工大学计算机科学与技术系 周海河 18908715777@189.cn
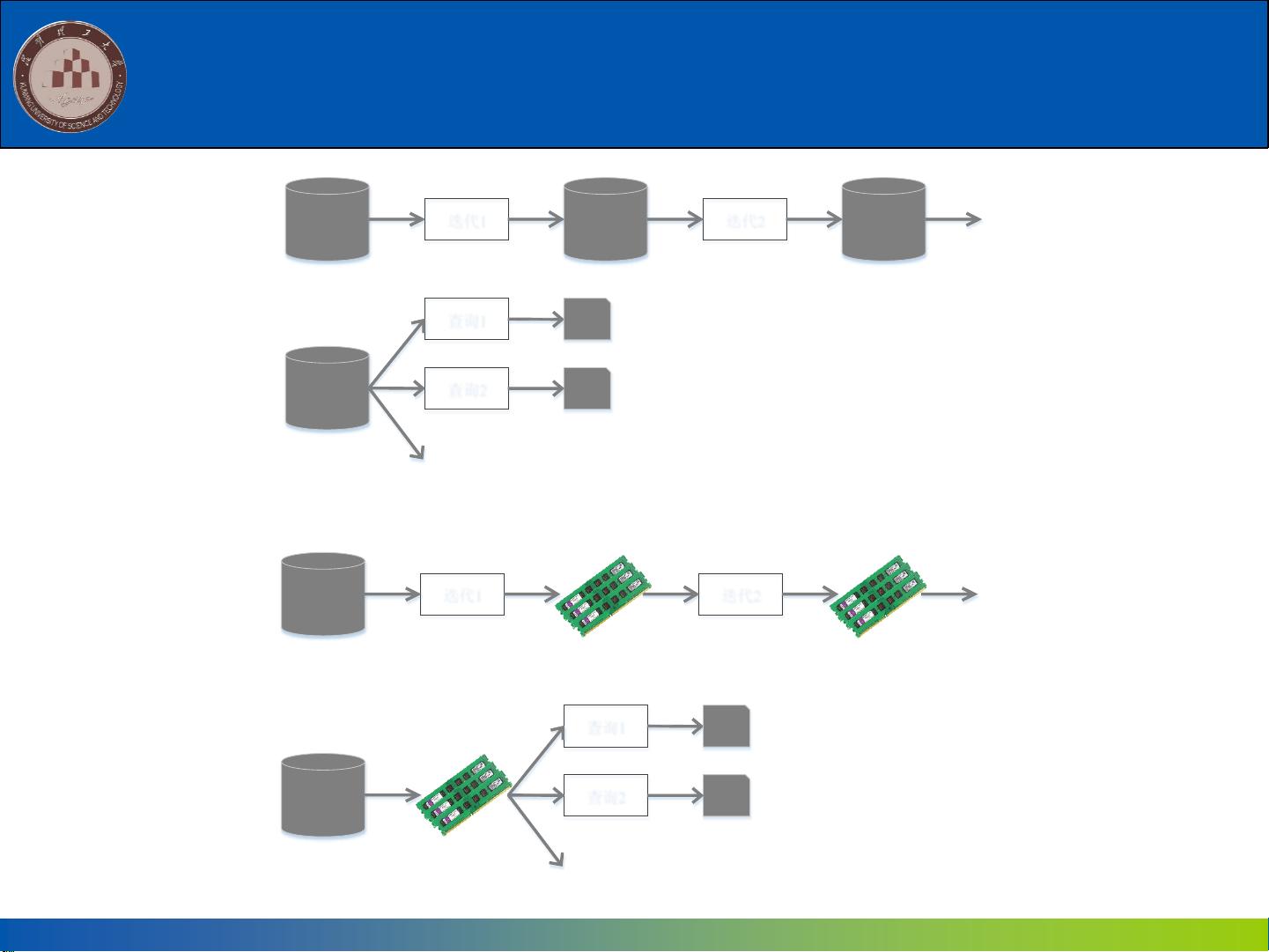
9.1.3 Spark与Hadoop的对比
迭代1 迭代2
HDFS
读取
HDFS
写入
HDFS
读取
HDFS
写入
...
查询1
查询2
...
结果1
结果2
(a) Hadoop MapReduce执行流程
迭代1 迭代2
读取
存储在
内存中
...
输入
输入
输入
存储在
内存中
读取
内存
查询1
查询2
...
结果1
结果2
输入
存储在
内存中
(b) Spark执行流程
图16-2 Hadoop与Spark的执行流程对比


剩余52页未读,继续阅读
143 浏览量
496 浏览量
2018-05-17 上传
2024-07-05 上传
2021-04-08 上传
119 浏览量
118 浏览量
2023-05-27 上传
2023-08-26 上传

kmzhouhaihe
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 微信小程序项目源码分享与解析
- Android中Handler与子线程实现计时方法
- AntiFreeze:永不卡死的高效任务管理器
- DPS系统7.05版本发布:全面升级的统计分析软件
- 记忆卡游戏:HTML制作的互动记忆练习工具
- 易语言实现EXCEL数据与MYSQL数据库交互操作教程
- 掌握数据科学核心技能的哈佛专业证书课程
- C#实现仿Windows记事本功能及特色工具集成
- 全面覆盖BAT Java面试题及详解
- H5音乐播放器模板开发:一站式网页音乐体验
- rcsslogplayer-15.1.0版本发布:全新的日志播放器
- 邮件服务库SendGrid、PostMark、MailGun和Mandrill使用教程
- perseid博客引擎:使用Meteor打造的早期原型
- 创建干净简洁的投资组合网站:mike.lastorbit.co的Jekyll主题指南
- LM2596双路稳压电源设计与完整AD工程资料
- FunPlane打飞机小游戏开发体验分享
