"基于自注意力对抗的深度子空间聚类:高维数据的有效处理与簇结构提取"
版权申诉
DOCX格式 | 578KB |
更新于2024-02-23
| 181 浏览量 | 举报
聚类作为无监督学习的技术,是许多领域中常用的统计数据分析技术,例如图像分割、人脸识别和文本分析。其目的是将数据分成若干簇,使得同一簇内的数据具有相似特征,而不同簇的数据具有较大差异的特征。通常,数据相似性可采用某种距离函数来衡量,例如欧氏距离、闵可夫斯基距离和信息熵等。目前流行的聚类方法有k均值(k-means)聚类、层次聚类、谱聚类等。然而,现实生活中存在高维数据,单独使用以上方法聚类的效率极低,并且在数据存在噪声干扰时结果也不够鲁棒。近年来,各国学者发现,虽然高维数据的结构在整个数据空间很难聚类,但高维数据的内在结构通常小于实际维度,并且簇结构可能在某个子空间很容易被观测到。因此,为了聚类高维数据,子空间聚类(Subspace clustering, SC)假定高维空间可分成若干个低维子空间,然后将这些低维子空间中提取的数据点分割成不同的簇。子空间聚类目前主要有4大类方法,包括迭代法、代数法、统计法和基于谱聚类的方法。其中基于谱聚类的子空间聚类一经提出就受到了广泛关注。
本文提出了一种基于自注意力对抗的深度子空间聚类方法。首先,通过引入自注意力机制,提升了特征映射的能力,使得算法能够更好地发现数据中的子空间结构。其次,利用对抗训练的思想,使得模型能够更好地抵抗噪声干扰和提升聚类的鲁棒性。在实验部分,作者通过对比实验验证了所提出方法的有效性,结果显示该方法在多个数据集上均取得了较好的聚类性能,并且对噪声数据具有较强的鲁棒性。
总的来说,本文提出了一种新的子空间聚类方法,通过引入自注意力机制和对抗训练的思想,使得聚类算法在处理高维数据时能够取得更好的效果。虽然该方法在实验阶段取得了较好的结果,但仍有许多需要进一步探索的问题。例如,如何更好地选择自注意力机制中的超参数以及对抗训练中的损失函数设置等。希望未来能够有更多的研究者对该方法进行进一步的探索和改进,使得子空间聚类方法在处理高维数据时能够发挥更大的作用。
给定一数据集 X={x1,x2,⋅⋅⋅xn}∈Rd×nX={x1,x2,⋅⋅⋅xn}∈Rd×n, 假设这组数据集属于
NN 个线性子空间{Si}Ni=1{Si}i=1N, 子空间维度分别为{di}Ni=1{di}i=1N. 假设属于某线性
子空间 SiSi 的样本足够多, 且张成整个子空间 SiSi, 则 SiSi 中的任意一样本 xx 均能表示为
XX 中除去 xx 的线性组合, 即数据集的“自表示”特性
[7]
, 则有如下子空间学习模型:
min12∥X−XC∥2F+λ∥C∥pmin12‖X−XC‖F2+λ‖C‖p
(1)
C∈Rn×nC∈Rn×n 为输入数据 XX 的自表示系数矩阵, 其中 CiCi 为第 ii 个数据 XiXi 由
其他数据表示的系数向量. ∥C∥p‖C‖p 为正则化项, ∥⋅∥p‖⋅‖p 为任意矩阵范数, 如稀疏子空间聚
类的 1-范数∥C∥1‖C‖1
[11]
, 低秩子空间聚类核范数∥C∥∗‖C‖∗
[12]
和 F-范数
[39]
. 然后使用谱聚类算
法对由自表示系数矩阵构建的相似度矩阵 A=12∣∣C+CT∣∣A=12|C+CT|聚类, 获得最终聚类结
果.
学者们发现基于自表示方法利用不同的正则化项可以处理受损数据, 例如, 包含噪声
和异常值的数据, 而且自表示系数矩阵呈现出块对角化的结构, 这非常有利于后续的谱聚类
[7]
处理. 因此, 如何获得鲁棒的自表示系数矩阵是基于谱聚类的子空间聚类算法的关键问题.
然而, 上述子空间模型学习到的自表示结构仅适用于线性子空间. 另一方面, 现实数据
常常具有高维的非线性结构, 传统子空间学习受到限制. 可喜的是, 深度自动编码器可将数
据转换至一个潜在的低维子空间, 捕获数据的非线性结构, 从而获得数据的低维特征表示.
因此与深度神经网络结合的子空间学习旨在低维特征上学习数据的自表示系数, 如深度子
空间聚类算法(Deep subspace clustering, DSC)
[40]
. DSC 首先采用深度自动编码器学习原数据
的低维特征表示, 然后利用一个由全连接网络构成的自表示层来学习数据的相邻关系, 该自
表示层将神经元连接的权重视为同一子空间中数据样本之间的相似度. 其目标函数表示如
下:
min12∥X−X^∥2F+λ12∥Z−ZC∥2F+λ2∥C∥pmin12‖X−X^‖F2+λ12‖Z−ZC‖F2+λ2‖C‖p
(2)
其中, X^=fd(Z)∈Rd×nX^=fd(Z)∈Rd×n 为 XX 的重构数据, 式(2)中第一项表示编解码的
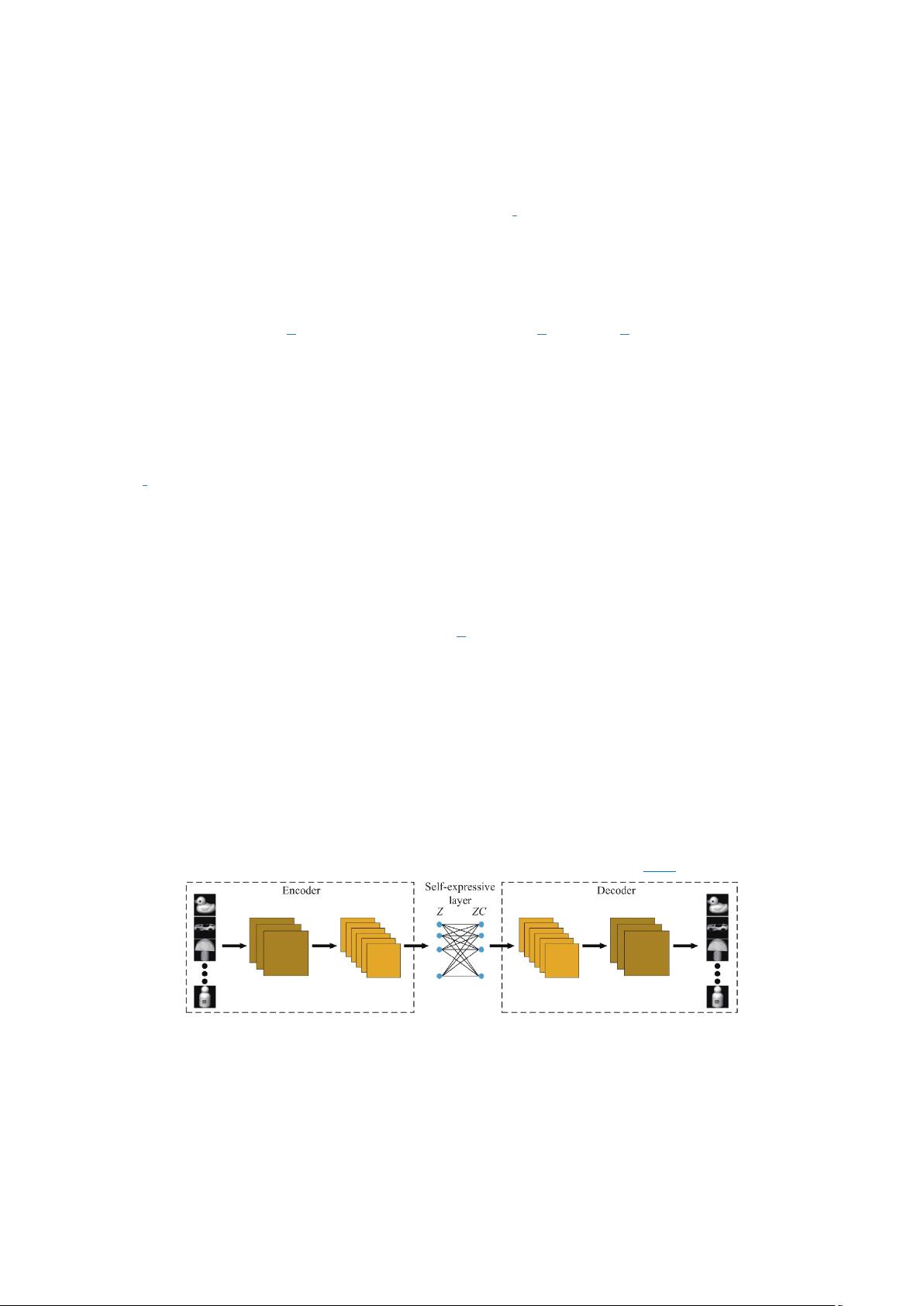
保真度, 尽可能少地损失重要信息. 第二项中 Z=fe(X)∈Rk×n (k≪d)Z=fe(X)∈Rk×n (k≪d)为
特征表示矩阵, 结合“自表示”层网络学习自表示系数. fe(⋅)fe(⋅)为编码器网络, fd(⋅)fd(⋅)表示
解码器网络, λ1λ1 和 λ2λ2 为权重参数用于调节各项平衡, 其网络结构如图 1 所示.
图 1 深度子空间聚类网络结构图
Fig. 1 The framework of Deep Subspace Clustering
剩余14页未读,继续阅读
相关推荐



罗伯特之技术屋
- 粉丝: 4558
 我的内容管理
展开
我的内容管理
展开







最新资源
- 小学水墨风学校网站模板设计
- 深入理解线程池的实现原理与应用
- MSP430编程代码集锦:实用例程源码分享
- 绿色大图幻灯商务响应式企业网站开发源码包
- 深入理解CSS与Web标准的专业解决方案
- Qt/C++集成Google拼音输入法演示Demo
- Apache Hive 0.13.1 版本安装包详解
- 百度地图范围标注技术及应用
- 打造个性化的Windows 8锁屏体验
- Atlantis移动应用开发深度解析
- ASP.NET实验教程:源代码详细解析与实践
- 2012年工业观察杂志完整版
- 全国综合缴费营业厅系统11.5:一站式缴费与运营管理解决方案
- JAVA原生实现HTTP请求的简易指南
- 便携PDF浏览器:随时随地快速查看文档
- VTF格式图片编辑工具:深入起源引擎贴图修改
